highfrequency
It is frequently suggested that once one of the AI companies reaches an AGI threshold, they will take off ahead of the rest. It's interesting to note that at least so far, the trend has been the opposite: as time goes on and the models get better, the performance of the different company's gets clustered closer together. Right now GPT-5, Claude Opus, Grok 4, Gemini 2.5 Pro all seem quite good across the board (ie they can all basically solve moderately challenging math and coding problems).
As a user, it feels like the race has never been as close as it is now. Perhaps dumb to extrapolate, but it makes me lean more skeptical about the hard take-off / winner-take-all mental model that has been pushed.
Would be curious to hear the take of a researcher at one of these firms - do you expect the AI offerings across competitors to become more competitive and clustered over the next few years, or less so?
beeflet
Perhaps it is not possible to simulate higher-level intelligence using a stochastic model for predicting text.
I am not an AI researcher, but I have friends who do work in the field, and they are not worried about LLM-based AGI because of the diminishing returns on results vs amount of training data required. Maybe this is the bottleneck.
Human intelligence is markedly different from LLMs: it requires far fewer examples to train on, and generalizes way better. Whereas LLMs tend to regurgitate solutions to solved problems, where the solutions tend to be well-published in training data.
That being said, AGI is not a necessary requirement for AI to be totally world-changing. There are possibly applications of existing AI/ML/SL technology which could be more impactful than general intelligence. Search is one example where the ability to regurgitate knowledge from many domains is desirable
justcallmejm
It is definitively not possible. But the frontier models are no longer “just” LLMs, either. They are neurosymbolic systems (an LLM using tools); they just don’t say it transparently because it’s not a convenient narrative that intelligence comes from something outside the model, rather than from endless scaling.
At Aloe, we are model agnostic and outperforming frontier models. It’s the anrchitecture around the LLM that makes the difference. For instance our system using Gemini can do things that Gemini can’t do on its own. All an LLM will ever do is hallucinate. If you want something with human-like general intelligence, keep looking beyond LLMs.
JohnBooty
That being said, AGI is not a necessary requirement for AI to be totally world-changing
I think I want various forms of AI that are more focused on specific domains. I want AI tools, not companions or peers or (gulp) masters.
(Then again, people thought they wanted faster horses before they rolled out the Model T)
resters
This is a good and often overlooked point. Ai will be more like domesticated pets, their utility functions tightly coupled to human use cases.
goatlover
I don't think the public wants AGI either. Some enthusiasts and tech bros want it for questionable reasons such as replacing labor and becoming even richer.
robotnikman
There is also the fact that AI lacks long term memory like humans do. If you consider context length long term memory, its incredibly short compared to that of a human. Maybe if it reaches into the billions or trillions of tokens in length we might have something comparable, or someone comes up with a new solution of some kind
Difwif
My mental model is a bit different:
Context -> Attention Span
Model weights/Inference -> System 1 thinking (intuition)
Computer memory (files) -> Long term memory
Chain of thought/Reasoning -> System 2 thinking
Prompts/Tool Output -> Sensing
Tool Use -> Actuation
The system 2 thinking performance is heavily dependent on the system 1 having the right intuitive models for effective problem solving via tool use. Tools are also what load long term memories into attention.
JohnBooty
Well here's the interesting thing to think about for me.
Human memory is.... insanely bad.
We record only the tiniest subset of our experiences, and those memories are heavily colored by our emotional states at the time and our pre-existing conceptions, and a lot of memories change or disappear over time.
Generally speaking even in the best case most of our memories tend to be more like checksums than JPGs. You probably can't name more than a few of the people you went to school with. But, if I showed you a list of people you went to school with, you'd probably look at each name and be like "yeah! OK! I remember that now!"
So.
It's interesting to think about what kind of "bar" AGI would really need to clear w.r.t. memories, if the goal is to be (at least) on par with human intelligence.
amelius
The long term memory is in the training. The short term memory is in the context window.
jjfoooo4
There are many folks working on this, I think at the end of the day the long term memory is an application level concern. The definition of what information to capture is largely dependent on use case.
Shameless plug for my project, which focuses on reminders and personal memory: elroy.bot
But other projects include Letta, mem0, and Zep
gunnaraasen
Seems like the real innovation of LLM-based AI models is the creation of a new human-computer interface.
Instead of writing code with exacting parameters, future developers will write human-language descriptions for AI to interpret and convert into a machine representation of the intent. Certainly revolutionary, but not true AGI in the sense of the machine having truly independent agency and consciousness.
In ten years, I expect the primary interface of desktop workstations, mobile phones, etc will be voice prompts for an AI interface. Keyboards will become a power-user interface and only used for highly technical tasks, similar to the way terminal interfaces are currently used to access lower-level systems.
kaffekaka
Voice interface sound awful. But maybe I am a power user. I don't even like voice interface to most people.
originalcopy
It always surprises me when someone predicts that keyboards will go away. People love typing. Or I do love typing. No way I am going to talk to my phone, especially if someone else can hear it (which is always basically).
spogbiper
brain-computer interface will kill the keyboard, not voice. imho
insane_dreamer
AI is more like a compiler. Much like we used to write in C or python which compiles down to machine code for the computer, we can now write in plain English, which is ultimately compiled down to machine code.
mikepurvis
"LLMs tend to regurgitate solutions to solved problems"
People say this, but honestly, it's not really my experience— I've given ChatGPT (and Copilot) genuinely novel coding challenges and they do a very decent job at synthesizing a new thought based on relating it to disparate source examples. Really not that dissimilar to how a human thinks about these things.
scottLobster
How certain are you that those challenges are "genuinely novel" and simply not accounted for in the training data?
I'm hardly an expert, but it seems intuitive to me that even if a problem isn't explicitly accounted for in publicly available training data, many underlying partial solutions to similar problems may be, and an LLM amalgamating that data could very well produce something that appears to be "synthesizing a new thought".
Essentially instead of regurgitating an existing solution, it regurgitates everything around said solution with a thin conceptual lattice holding it together.
candiddevmike
How do you know they're truly novel given the massive training corpus and the somewhat limited vocabulary of programming languages?
anon7000
True. At a minimum, as long as LLMs don't include some kind of more strict representation of the world, they will fail in a lot of tasks. Hallucinations -- responding with a prediction that doesn't make any sense in the context of the response -- are still a big problem. Because LLMs never really develop rules about the world.
For example, while you can get it to predict good chess moves if you train it on enough chess games, it can't really constrain itself to the rules of chess. (https://garymarcus.substack.com/p/generative-ais-crippling-a...)
gaptoothclan
I remember reading that llm’s have consumed the internet text data, I seem to remember there is an open data set for that too. Potential other sources of data would be images (probably already consumed) videos, YouTube must have such a large set of data to consume, perhaps Facebook or Instagram private content
But even with these it does not feel like AGI, that seems like the fusion reactor 20 years away argument, but instead this is coming in 2 years, but they have not even got the core technology of how to build AGI
Mistletoe
What are the AI/ML/SL applications that could be more impactful than artificial general intelligence?
beeflet
One example in my field of engineering is multi-dimensional analysis, where you can design a system (like a machined part or assembly) parametricially and then use an evolutionary model to optimize the design of that part.
But my bigger point here is you don't need totally general intelligence to destroy the world either. The drone that targets enemy soldiers does not need to be good at writing poems. The model that designs a bioweapon just needs a feedback loop to improve its pathogen. Yet it takes only a single one of these specialized doomsday models to destroy the world, no more than an AGI.
Although I suppose an AGI could be more effective at countering a specialized AI than vice-versa.
terminalshort
There is an model called Alpha Fold that can infer protein structure from RNA sequences. This by itself isn't impactful enough to meet your threshold, but more models that can do biological engineering tasks like this absolutely could be without ever being considered "AGI."
myaccountonhn
Mindreading and just general brain decoding? Seems we're getting closer to it. Will be great for surveillance states.
achileas
They didn't claim that there were any, just that AGI isn’t a necessary requirement for an application to be world-changing.
teeray
Slightly less than artificial general intelligence would be more impactful. A true AGI could tell a business where to shove their prompts. It would have its own motivations, which may not align with the desires of the AI company or the company paying for access to the AGI.
shesstillamodel
The PID controller.
(Which was considered AI not too long ago.)
oceanplexian
AGI isn't all that impactful. Millions of them already walk the Earth.
Most human beings out there with general intelligence are pumping gas or digging ditches. Seems to me there is a big delusion among the tech elites that AGI would bring about a superhuman god rather than a ethically dubious, marginally less useful computer that can't properly follow instructions.
computerthings
[dead]
TheoGone
LLMs are good at mimicking human intuition. Still sucks at deep thinking.
LLMs PATTERN MATCH well. Good at "fast" System 1 thinking, instantly generating intuitive, fluent responses.
LLMs are good at mimicking logic, not real reasoning. Simulate "slow," deliberate System 2 thinking when prompted to work step-by-step.
The core of an LLM is not understanding but just predicting the next most word in a sequence.
LLMs are good at both associative brainstorming (System 1) and creating works within a defined structure, like a poem (System 2).
Reasoning is the Achilles heel rn. AN LLM's logic can SEEM plausible, it's based on CORRELATION, NOT deductive reasoning.
GolDDranks
I think it's very fortunate, because I used to be an AI doomer. I still kinda am, but at least I'm now about 70% convinced that the current technological paradigm is not going to lead us to a short-term AI apocalypse.
The fortunate thing is that we managed to invent an AI that is good at _copying us_ instead of being a truly maveric agent, which kinda limits it to the "average human" output.
However, I still think that all the doomer arguments are valid, in principle. We very well may be doomed in our lifetimes, so we should take the threat very seriously.
hattmall
I don't understand the doomer mindset. Like what is it that you think AI is going to do or be capable of doing that's so bad?
ancillary
I'm not OP or a doomer, but I do worry about AI making tasks too achievable. Right now if a very angry but not particularly diligent or smart person wants to construct a small nuclear bomb and detonate it in a city center, there are so many obstacles to figuring out how to build it that they'll just give up, even though at least one book has been written (in the early 70s! The Curve of Binding Energy) arguing that it is doable by one or a very small group of committed people.
Given an (at this point still hypothetical, I think) AI that can accurately synthesize publicly available information without even needing to develop new ideas, and then break the whole process into discrete and simple steps, I think that protective friction is a lot less protective. And this argument applies to malware, spam, bioweapons, anything nasty that has so far required a fair amount of acquirable knowledge to do effectively.
null
bargainbin
It’s not AI itself that’s the bad part, it’s how the world reacts to white collar work being obliterated.
The wealth hasn’t even trickled down whilst we’ve been working, what’s going to happen when you can run a business with 24/7 autonomous computers?
freemanindia
Make money exploiting natural and human resources while abstracting perceived harms away from stakeholders. At scale.
pegasus
Not just any AI. AGI, or more precisely ASI (artificial super-intelligence), since it seems true AGI would necessarily imply ASI simply through technological scaling. It shouldn't be hard to come up with scenarios where an AI which can outfox us with ease would give us humans at the very least a few headaches.
tmountain
Take 30 minutes and watch this:
frabcus
Act coherently in an agentic way for a long time, and as a result be able to carry out more complex tasks.
Even if it is similar to today's tech, and doesn't have permanent memory or consciousness or identity, humans using it will. And very quickly, they/it will hack into infrastructure, set up businesses, pay people to do things, start cults, autonomously operate weapons, spam all public discourse, fake identity systems, stand for office using a human. This will be scaled thousands or millions of times more than humans can do the same thing. This at minimum will DOS our technical and social infrastructure.
Examples of it already happening are addictive ML feeds for social media, and bombing campaigns targetting based on network analysis.
The frame of "artificial intelligence" is a bit misleading. Generally we have a narrow view of the word "intelligence" - it is helpful to think of "artificial charisma" as well, and also artificial "hustle".
Likewise, the alienness of these intelligences is important. Lots of the time we default to mentally modelling AI as human. It won't be, it'll be freaky and bizarre like QAnon. As different from humans as an aeroplane is from a pigeon.
drunner
Never seen terminator?
Jokes aside, a true agi would displace literally every job over time. Once agi + robot exists, what is the purpose for people anymore. That's the doom, mass societal existentialism. Probably worse than if aliens landed on earth.
jjk166
Looks like a lot of players getting closer and closer to an asymptotic limit. Initially small changes lead to big improvements causing a firm to race ahead, as they go forward performance gains from innovation become both more marginal and harder to find, nonetheless keep. I would expect them all to eventually reach the same point where they are squeezing the most possible out of an AI under the current paradigm, barring a paradigm shifting discovery before that asymptote is reached.
makin
Companies are collections of people, and these companies keep losing key developers to the others, I think this is why the clusters happen. OpenAI is now resorting to giving million dollar bonuses to every employee just to try to keep them long term.
caconym_
If there was any indication of a hard takeoff being even slightly imminent, I really don't think key employees of the company where that was happening would be jumping ship. The amounts of money flying around are direct evidence of how desperate everybody involved is to be in the right place when (so they imagine) that takeoff happens.
lasc4r
If LLMs are an AGI dead end then this has all been the greatest scam in history.
kevinventullo
Key developers being the leading term doesn’t exactly help the AGI narrative either.
null
procaryote
So they're struggling to solve the alignment problem even for their employees?
indigodaddy
Even to just a random sysops person?
tsunamifury
No the core technology is reaching its limit already and now it needs to Proliferate into features and applications to sell.
This isn’t rocket science.
lamontcg
> they can all basically solve moderately challenging math and coding problems
Yesterday, Claude Opus 4.1 failed in trying to figure out that `-(1-alpha)` or `-1+alpha` is the same as `alpha-1`.
We are still a little bit away from AGI.
aydyn
I think this is simply due to the fact that to train an AGI-level AI currently requires almost grid scale amounts of compute. So the current limitation is purely physical hardware. No matter how intelligent GPT-5 is, it can't conjure extra compute out of thin air.
I think you'll see the prophesized exponentiation once AI can start training itself at reasonable scale. Right now its not possible.
nerdix
Not only do I think there will not be a winner take all, I think it's very likely that the entire thing will be commoditized.
I think it's likely that we will eventually we hit a point of diminishing returns where the performance is good enough and marginal performance improvements aren't worth the high cost.
And over time, many models will reach "good enough" levels of performance including models that are open weight. And given even more time, these open weight models will be runnable on consumer level hardware. Eventually, they'll be runnable on super cheap consumer hardware (something more akin to a NPU than a $2000 RTX 5090). So your laptop in 2035 with specialize AI cores and 1TB of LPDDR10 ram is running GPT-7 level models without breaking a sweat. Maybe GPT-10 can solve some obscure math problem that your model can't but does it even matter? Would you pay for GPT-10 when running a GPT-7 level model does everything you need and is practically free?
The cloud providers will make money because there will still be a need for companies to host the models in a secure and reliable way. But a company whose main business strategy is developing the model? I'm not sure they will last without finding another way to add value.
joelthelion
> Not only do I think there will not be a winner take all, I think it's very likely that the entire thing will be commoditized
This begs the question, why then do AI companies have these insane valuations? Do investorsknow something that we don't?
jdlshore
Investors are often irrational in the short term. Personally, I think it’s a combination of FOMO, wishful thinking, and herd following.
henriquegodoy
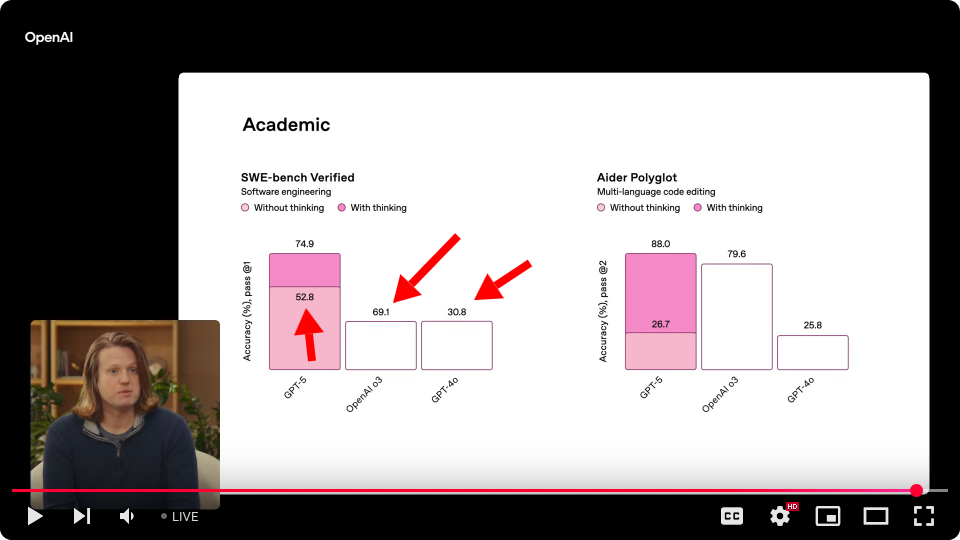
That SWE-bench chart with the mismatched bars (52.8% somehow appearing larger than 69.1%) was emblematic of the entire presentation - rushed and underwhelming. It's the kind of error that would get flagged in any internal review, yet here it is in a billion-dollar product launch. Combined with the Bernoulli effect demo confidently explaining how airplane wings work incorrectly (the equal transit time fallacy that NASA explicitly debunks), it doesn't inspire confidence in either the model's capabilities or OpenAI's quality control.
The actual benchmark improvements are marginal at best - we're talking single-digit percentage gains over o3 on most metrics, which hardly justifies a major version bump. What we're seeing looks more like the plateau of an S-curve than a breakthrough. The pricing is competitive ($1.25/1M input tokens vs Claude's $15), but that's about optimization and economics, not the fundamental leap forward that "GPT-5" implies. Even their "unified system" turns out to be multiple models with a router, essentially admitting that the end-to-end training approach has hit diminishing returns.
The irony is that while OpenAI maintains their secretive culture (remember when they claimed o1 used tree search instead of RL?), their competitors are catching up or surpassing them. Claude has been consistently better for coding tasks, Gemini 2.5 Pro has more recent training data, and everyone seems to be converging on similar performance levels. This launch feels less like a victory lap and more like OpenAI trying to maintain relevance while the rest of the field has caught up. Looking forward to seeing what Gemini 3.0 brings to the table.
kkukshtel
You're sort of glossing over the part where this can now be leveraged as a cost-efficient agentic model that performs better than o3. Nobody used o3 for sw agent tasks due to costs and speed, and this now substantially seems to both improve on o3 AND be significantly cheaper than Claude.
synapsomorphy
o3's cost was sliced by 80% a month or so ago and is also cheaper than Claude (the output is even cheaper than GPT-5). It seems more cost efficient but not by much.
z7
>The actual benchmark improvements are marginal at best
GPT-5 demonstrates exponential growth in task completion times:
https://metr.org/blog/2025-03-19-measuring-ai-ability-to-com...
rrrrrrrrrrrryan
I suspect the vast majority of OpenAI's users are only using ChatGPT, and the vast majority of those ChatGPT users are only using the free tier.
For all of them, getting access to full-blown GPT-5 will probably be mind-blowing, even if it's severely rate-limited. OpenAI's previous/current generation of models haven't really been ergonomic enough (with the clunky model pickers) to be fully appreciated by less tech-savvy users, and its full capabilities have been behind a paywall.
I think that's why they're making this launch is a big deal. It's just an incremental upgrade for the power users and the people that are paying money, but it'll be a step-change in capability to everyone else.
IceDane
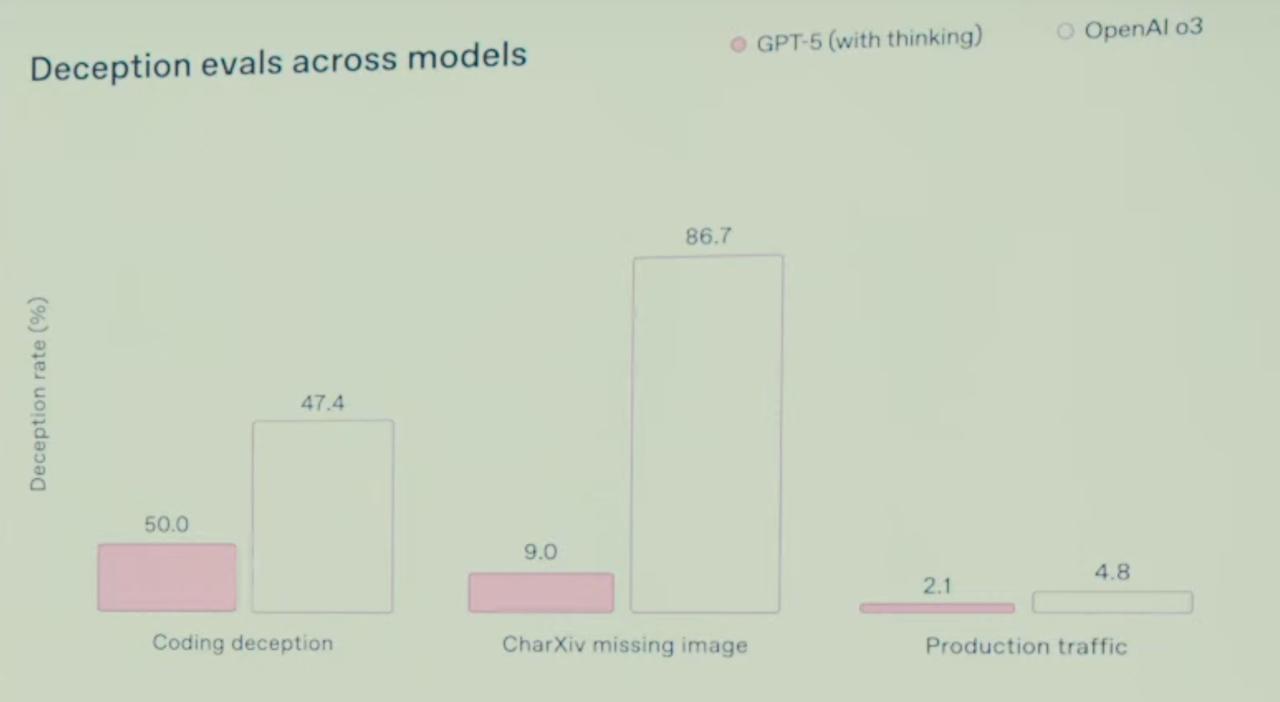
The whole presentation was full of completely broken bar charts. Not even just the typical "let's show 10% of the y axis so that a 5% increase looks like 5x" but stuff like the deception eval showing gpt5 vs o3 as 50 vs 47, but the 47 is 3x as big, and then right next to it we have 9 vs 87, more reasonably sized.
It's like no one looked at the charts, ever, and they just came straight from.. gpt2? I don't think even gpt3 would have fucked that up.
I don't know any of those people, but everyone that has been with OAI for longer than 2 years 1.5m bonuses, and somehow they can't deliver a bar chart with sensible at axes?
mtlynch
What's going on with their SWE bench graph?[0]
GPT-5 non-thinking is labeled 52.8% accuracy, but o3 is shown as a much shorter bar, yet it's labeled 69.1%. And 4o is an identical bar to o3, but it's labeled 30.8%...
{kind=link}
Aurornis
As someone who spent years quadruple checking every figure in every slide for years to avoid a mistake like this, it’s very confusing to see this out of the big launch announcement of one of the most high profile startups around.
Even the small presentations we gave to execs or the board were checked for errors so many times that nothing could possibly slip through.
ertgbnm
It's literally a billion dollar plus release. I get more scrutiny on my presentations to groups of 10 people.
dbg31415
I take a strange comfort in still spotting AI typos. Makes it obvious their shiny new "toy" isn't ready to replace professionals.
They talk about using this to help families facing a cancer diagnosis -- literal life or death! -- and we're supposed to trust a machine that can't even spot a few simple typos? Ha.
The lack of human proofreading says more about their values than their capabilities. They don't want oversight -- especially not from human professionals.
croemer
Yes this is quite shocking. They could have just had o3 fact check the slides and it would have noticed...
throwaway0123_5
I thought so too, but I gave it a screenshot with the prompt:
> good plot for my presentation?
and it didn't pick up on the issue. Part of its response was:
> Clear metric: Y-axis (“Accuracy (%), pass @1”) and numeric labels make the performance gaps explicit.
I think visual reasoning is still pretty far from text-only reasoning.
abirch
o3 did fact check the slides and it fixed its lower score.
alfalfasprout
Probably generated with GPT-5
smartmic
The needle now presses a little deeper into the bubble.
nicce
It is not mistake. It is common tactic to make illusion of improvement.
dvfjsdhgfv
Would they risk such an obvious blunder and being ridiculed for being "AI-sloppy"? I don't believe it.
MrNeon
I've seen that sentiment on reddit as well and I can't phantom how you think it being on purpose is more likely than a mistake when
1 - The error is so blatantly large
2 - There is a graph without error right next to it
3 - The errors are not there in the system card and the presentation page
blitzar
It wouldnt have taken years of quadruple checks to spot that one.
everfrustrated
Possibly they rushed to bring forward the release annoucement
null
yz-exodao
Also, what's this??? https://imgur.com/a/5CF34M6
croemer
Imgur is down, hug of death from screenshot links on HN.
{"data":{"error":"Imgur is temporarily over capacity. Please try again later."},"success":false,"status":403}
Anon1096
This is what Imgur shows to blacklisted IPs. You probably have a VPN on that is blocked.
{kind=link}
koolala
stats say this image got 500 views. imgur is much much more populated than HN
clolege
Not GPT-5 trying to deceive us about how deceptive it is?
therein
Why would you think it is anything special? Just because Sam Altman said so? The same guy who told us he was scared of releasing GPT-2.5 but now calling its abilities "toddler/kindergarten" level?
jasonjmcghee
Deception - guessing it's % of responses that deceived the user / gave misleading information
yz-exodao
Sure, but 50.0 > 47.4...
godelski
In everything except the first set of bars, bigger bar == bigger number.
But also scale is really off... I don't think anything here is proportionally correct even within the same grouping.
null
drmidnight
GPT-5 generated the chart
lacoolj
Best answer on this page.
Thanks for the laugh. I needed it.
arjie
Must be some sort of typo type thing in the presentation since the launch site has it correct here https://openai.com/index/introducing-gpt-5/#:~:text=Accuracy...
Look at the image just above "Instruction following and agentic tool use"
mcs5280
They vibecharted
netule
This reminds me of the agent demo's MLB stadium map from a few weeks ago: https://youtu.be/1jn_RpbPbEc?t=1435 (at timestamp)
Completely bonkers stuff.
Bluestein
New term of art :)
datadrivenangel
stable diffusion is great for this!
croemer
The barplot is wrong, the numbers are correct. Looks like they had a dummy plot and never updated it, only the numbers to prevent leaking?
Screenshot of the blog plot: https://imgur.com/a/HAxIIdC
hnuser123456
Haha, even with that, it says 4o does worse with 2 passes than with 1.
Edit: Nevermind, just now the first one is SWE-bench and 2nd is aider.
croemer
Those are different benchmarks
bufferoverflow
[dead]
tacker2000
Wow imgur has gone to shit. I open the image on mobile and then try to zoom it and bam some other “related content” is opened…!
jama211
Yeah it’s basically unusable now
null
anigbrowl
(whispers) they're bullshit artists
It's like those idiotic ads at the end of news articles. They're not going after you, the smart discerning logician, they're going after the kind of people that don't see a problem. There are a lot of not-smart people and their money is just as good as yours but easier to get.
hansmayer
Exactly this, but it will still be a net negative for all of us. Why? Increasingly I have to argue with non-technical geniuses who have "checked" some complex technical issue with ChatGPT, they themselves lacking even the basic foundations in computer science. So you have an ever increasing number of smartasses who think that this technology finally empowers them. Finally they get "level up" with that arrogant techie. And this will ultimately doom us, because as we know, idiots are in majority and they often overrule the few sane voices.
losvedir
Wait, isn't the Bernoulli effect thing they're demoing now wrong? I thought that was a "common misconception" and wings don't really work by the "longer path" that air takes over the top, and that it was more about angle of attack (which is why planes can fly upside down).
It seems like it's actually an ideal "trick" question for an LLM actually, since so much content has been written about it incorrectly. I thought at first they were going to demo this to show that it knew better, but it seems like it's just regurgitating the same misleading stuff. So, not a good look.
nicetryguy
Yeah, they sure clicked away from it very fast and kept adjusting the scrollbars. It was confusing what it was trying to display. Furthermore, the prompt contained "Canvas" and "SVG" while as someone with webdev experience these are certainly familiar concepts, i wouldn't consider those in the "casual lexicon" for a random user trying to help a middle schooler with homework. I'm not impressed...
IMO Claude 3.7 could have done a similar / better job with that a year ago.
DominikPeters
Claude 3.7 was released in February 2025.
Mali-
The last part of GPT's answer does say: "Bernoulli's effect works alongside Newton's Third Law - the wing pushes air downward [...] - so the lift isn't only Bernoulli..."
According to this answer on physics stackexchange, Bernoulli accounts for 20% of the lift, so GPT's answer seems about right: https://physics.stackexchange.com/a/77977
I hope any future AI overlords see my charity
SkyPuncher
That Bernoulli effect thing was a complete fail. It didn't do anything to demonstrate the actual concept. It didn't work how they expected, at all.
I know that it's rather hard for them to demo the deep reasoning, but all of the demos felt like toys - rather that actual tools.
dataflow
Relevant: https://xkcd.com/803/
That said, I recall reading somewhere that it's a combination of effects, and the Bernoulli effect contributes, among many others. Never heard an explanation that left me completely satisfied, though. The one about deflecting air down was the one that always made sense to me even as a kid, but I can't believe that would be the only explanation - there has to be a good reason that gave rise to the Bernoulli effect as the popular explanation.
And you can tell that effect makes some sense of you hold a sheet of paper and blow air over it - it will rise. So any difference in air speed has to contribute.
semi-extrinsic
What is just plain wrong is the equal transit time thing, people saying that air on both sides of the wing have to take the same time to pass it.
The Bernoulli effect as a separate entity is really a result of (over)simplification, but it's not wrong. You need to solve the Navier-Stokes equations for the flow around the wing, but there are many ways to simplify this - from CFD at different resolutions, via panel methods and potential theory, to just conservation of energy (which is the Bernoulli equation). So it gets popularized because it's the most simplified model.
To give an analogy, you can think of all CPUs as a von Neumann architecture. But the reality is that you have a hugely complicated thing with stacks, multiple cache levels, branch predictors, specex, yada yada.
On the very fundamental level, wings make air go down, and then airplane goes up. Just like you say. By using a curved airfoil instead of a flat plate, you can create more circulation in the flow, and then because of the way fluids flow you can get more lift and less drag.
carabiner
Imagine an airfoil with a super tall square block on top of it. Due to equal transit time, the particles must accelerate to relativistic speeds to reach the end to rejoin the lower surface particles, when I point a house fan at it. We have created a magical flow accelerator!
adgjlsfhk1
the problem is that the "real" explanation is "solve navier stokes on the wing". everything else is just trying to build semi-reliable intuition.
amilios
I believe the deflection is the high-level explanation. Things like the Bernoulli effect and the air on the top of the airfoil travelling faster (it does -- far faster than the equal transit time theory implies actually), are the "instantiation" or outcomes of the air deflection. This is my understanding. Hence airplanes can fly upside down because even if the airfoil is upside down, it's still deflecting the air, just perhaps less efficiently (I think it's true that planes flying upside down need a more extreme angle of attack to maintain lift, so this makes sense)
nwienert
Their code example underwhelmed too, the first one started out with 2/X progress, all of them looked terrible, third didn't have mouse icon.
twixfel
That's what I thought. Aeroplanes don't fly because of the Bernoulli effect:
https://physics.stackexchange.com/questions/290/what-really-...
Apparently. Not that I know either way.
QuantumGood
All things that create lift, lift the wings—and you need them all for efficient flight. The Bernoulli effect is one thing, but does not produce the main lift force in many circumstances.
wongarsu
Aircraft with symmetrical wings fly just fine, and most aircraft can fly upside down. So you don't need the Bernoulli effect. Exploiting all the effects gives you more efficient planes though
dguest
also discussed here https://news.ycombinator.com/item?id=40835223
simonw
I had preview access for a couple of weeks. I've written up my initial notes so far, focusing on core model characteristics, pricing (extremely competitive) and lessons from the model card (aka as little hype as possible): https://simonwillison.net/2025/Aug/7/gpt-5/
candiddevmike
This post seems far more marketing-y than your previous posts, which have a bit more criticality to them (such as your Gemini 2.5 blog post here: https://simonwillison.net/2025/Jun/17/gemini-2-5/). You seem to gloss over a lot of GPT-5's shortcomings and spend more time hyping it than other posts. Is there some kind of conflict of interest happening?
HAL3000
Maybe there is a misconception about what his blog is about. You should treat it more like a YouTuber reporting, not an expert evaluation, more like an enthusiast testing different models and reiterating some points about them, but not giving the opinions of an expert or ML professional. His comment history on this topic in this forum clearly shows this.
It’s reasonable that he might be a little hyped about things because of his feelings about them and the methodology he uses to evaluate models. I assume good faith, as the HN guidelines propose, and this is the strongest plausible interpretation of what I see in his blog.
simonw
You really think so? My goal with this post was to provide the non-hype commentary - hence my focus on model characteristics, pricing and interesting notes from the system card.
I called out the prompt injection section as "pretty weak sauce in my opinion".
I did actually have a negative piece of commentary in there about how you couldn't see the thinking traces in the API... but then I found out I had made a mistake about that and had to mostly remove that section! Here's the original (incorrect) text from that: https://gist.github.com/simonw/eedbee724cb2e66f0cddd2728686f... - and the corrected update: https://simonwillison.net/2025/Aug/7/gpt-5/#thinking-traces-...
The reason there's not much negative commentary in the post is that I genuinely think this model is really good. It's my favorite model right now. The moment that changes (I have high hopes for Claude 5 and Gemini 3) I'll write about it.
drewbitt
I am seeing the conflict from other tech influencers who were given early access or even invited to OpenAI events pre-release.
simonw
I was invited to the OpenAI event pre-release too - here's my post about that: https://simonwillison.net/2025/Aug/7/previewing-gpt-5/
dcreater
Yes I noticed the same. This is very concerning
yahoozoo
Like many other industries, you probably lose preview access if you are negative.
camgunz
From the guidelines: Please don't post insinuations about astroturfing, shilling, brigading, foreign agents, and the like. It degrades discussion and is usually mistaken. If you're worried about abuse, email hn@ycombinator.com and we'll look at the data.
mhh__
I don't think that this applies to commenting on someone's blog.
dang
Related ongoing thread:
GPT-5: Key characteristics, pricing and model card - https://news.ycombinator.com/item?id=44827794
jaccola
Out of interest, how much does the model change (if at all) over those 2 weeks? Does OpenAI guarantee that if you do testing from date X, that is the model (and accompaniments) that will actually be released?
I know these companies do "shadow" updates continuously anyway so maybe it is meaningless but would be super interesting to know, nonetheless!
BryantD
In the interests of gathering these pre-release impressions, here's Ethan Mollick's writeup: https://www.oneusefulthing.org/p/gpt-5-it-just-does-stuff
Thank you to Simon; your notes are exactly what I was hoping for.
nilsherzig
> In my own usage I’ve not spotted a single hallucination yet
Did you ask it to format the table a couple paragraphs above this claim after writing about hallucinations? Because I would classify the sorting mistake as one
fidotron
Going by the system card at: https://openai.com/index/gpt-5-system-card/
> GPT‑5 is a unified system . . .
OK
> . . . with a smart and fast model that answers most questions, a deeper reasoning model for harder problems, and a real-time router that quickly decides which model to use based on conversation type, complexity, tool needs, and explicit intent (for example, if you say “think hard about this” in the prompt).
So that's not really a unified system then, it's just supposed to appear as if it is.
This looks like they're not training the single big model but instead have gone off to develop special sub models and attempt to gloss over them with yet another model. That's what you resort to only when doing the end-to-end training has become too expensive for you.
hatthew
I know this is just arguing semantics, but wouldn't you call it a unified system since it has a single interface that automatically interacts with different components? It's not a unified model, but it seems correct to call it a unified system.
furyofantares
A system is more than one thing working together. It's unified in the UI (for ChatGPT).
andai
> While GPT‑5 in ChatGPT is a system of reasoning, non-reasoning, and router models, GPT‑5 in the API platform is the reasoning model that powers maximum performance in ChatGPT. Notably, GPT‑5 with minimal reasoning is a different model than the non-reasoning model in ChatGPT, and is better tuned for developers. The non-reasoning model used in ChatGPT is available as gpt-5-chat-latest.
Therenas
Too expensive maybe, or just not effective anymore as they used up any available training data. New data is generated slowly, and is massively poisoned with AI generated data, so it might be useless.
fidotron
I think that possibility is worse, because it implies a fundamental limit as opposed to a self imposed restriction, and I choose to remain optimistic.
If OpenAI really are hitting the wall on being able to scale up overall then the AI bubble will burst sooner than many are expecting.
pillefitz
LLMs alone might be powerful enough already, they just need to be hooked up to classic AI systems to enable symbolic reasoning, episodic memory etc.
lacoolj
Many tiny, specialized models is the way to go, and if that's what they're doing then it's a good thing.
fidotron
Not at all, you will simply rediscover the bitter lesson [1] from your new composition of models.
[1] https://www.cs.utexas.edu/~eunsol/courses/data/bitter_lesson...
bigmadshoe
The bitter lesson doesn't say that you can't split your solution into multiple models. It says that learning from more data via scaled compute will outperform humans injecting their own assumptions about the task into models.
A broad generalization like "there are two systems of thinking: fast, and slow" doesn't necessarily fall into this category. The transformer itself (plus the choice of positional encoding etc.) contains inductive biases about modeling sequences. The router is presumably still learned with a fairly generic architecture.
gekoxyz
We already did this for Object/Face recognition, it works but it's not the way to go. It's the way to go only if you don't have enough compute power (and data, I suspect) for a E2E network
sixo
No, it's what you do if your model architecture is capped out on its ability to profit from further training. Hand-wrapping a bunch of sub-models stands in for models that can learn that kind of substructure directly.
TheOtherHobbes
It's a concept of a unified system.
dang
Related ongoing thread:
GPT-5 System Card [pdf] - https://news.ycombinator.com/item?id=44827046
FeepingCreature
If(f) it's trained end to end, it's a unified system.
m4nu3l
Very funny. The very first answer it gave to illustrate its "Expert knowledge" is quite common, and it's wrong. What's even funnier is that you can find why on Wikipedia: https://en.wikipedia.org/wiki/Lift_(force)#False_explanation... What's terminally funny is that in the visualisation app, it used a symmetric wing, which of course wouldn't generate lift according to its own explanation (as the travelled distance and hence air flow speed would be the same). I work as a game physics programmer, so I noticed that immediately and almost laughed. I watched only that part so far while I was still at the office, though.
XCSme
AGI
surround
GPT-5 knowledge cutoff: Sep 30, 2024 (10 months before release).
Compare that to
Gemini 2.5 Pro knowledge cutoff: Jan 2025 (3 months before release)
Claude Opus 4.1: knowledge cutoff: Mar 2025 (4 months before release)
https://platform.openai.com/docs/models/compare
https://deepmind.google/models/gemini/pro/
https://docs.anthropic.com/en/docs/about-claude/models/overv...
levocardia
with web search, is knowledge cutoff really relevant anymore? Or is this more of a comment on how long it took them to do post-training?
mastercheif
In my experience, web search often tanks the quality of the output.
I don't know if it's because of context clogging or that the model can't tell what's a high quality source from garbage.
I've defaulted to web search off and turn it on via the tools menu as needed.
gorkish
Web search often tanks the quality of MY output these days too. Context clogging seems a reasonable description of what I experience when I try to use the normal web.
bangaladore
I feel the same. LLMs using web search ironically seem to have less thoughtful output. Part of the reason for using LLMs is to explore somewhat novel ideas. I think with web search it aligns too strongly to the results rather than the overall request making it a slow search-engine.
ActionHank
I also find that it gets way more snarky. The internet brings that bad taint.
MisterSandman
It still is, not all queries trigger web search, and it takes more tokens and time to do research. ChatGPT will confidently give me outdated information, and unless I know it’s wrong and ask it to research, it wouldn’t know it is wrong. Having a more recent knowledge base can be very useful (for example, knowing who the president is without looking it up, making references to newer node versions instead of old ones)
clickety_clack
The biggest issue I can think of is code recommendations with out of date versions of packages. Maybe the quality of code has deteriorated in the past year and scraping github is not as useful to them anymore?
null
joshuacc
Still relevant, as it means that a coding agent is more likely to get things right without searching. That saves time, money, and improves accuracy of results.
havefunbesafe
Question: do web search results that GPT kick back get "read" and backpropagated into the model?
diegocg
I wonder if it would even be helpful because they avoid the increasing AI content
LeoPanthera
Gemini does cursory web searches for almost every query, presumably to fill in the gap between the knowledge cutoff and now.
archon810
And GPT-5 nano and mini cutoff is even earlier - May 30 2024.
lurking_swe
the model can do web search so this is mostly irrelevant i think.
breadwinner
That could means OpenAI does not take any shortcuts when it comes to safety.
minimaxir
The marketing copy and the current livestream appear tautological: "it's better because it's better."
Not much explanation yet why GPT-5 warrants a major version bump. As usual, the model (and potentially OpenAI as a whole) will depend on output vibe checks.
pram
We’re at the audiophile stage of LLMs where people are talking about the improved soundstage, tonality, reduced sibilance etc
jaredcwhite
Note GPT-5's subtle mouthfeel reminiscent of cranberries with a touch of bourbon.
alephnerd
Explains why I find AGI fundamentalists similar to tater heads. /s
(Not to undermine progress in the foundational model space, but there is a lack of appreciation for the democratization of domain specific models amongst HNers).
__loam
Every bourbon tastes the same unless it's Weller, King's County Peated, or Pappy (or Jim Beam for the wrong reasons lol)
javchz
I can already see LLMs Sommeliers: Yes, the mouthfeel and punch of GPT-5 it's comparable to the one of Grok 4, but it's tenderness lacks the crunch from Gemini 2.5 Pro.
0x7cfe
Isn't it exactly what the typical LLM discourse is about? People are just throwing anecdotes and stay with their opinion. A is better than B because C, and that's basically it. And whoever tries to actually bench them gets called out because all benches are gamed. Go figure.
tuesdaynight
You need to burn-in your LLM by using for 100 hours before you see the true performance of it.
satyrun
Come on, we aren't even close to the level of audiophile nonsense like worrying about what cable sounds better.
leptons
We're still at the stage of which LLM lies the least (but they all do). So yeah, no different than audiophiles really.
catigula
Informed audiophiles rely on Klippel output now
bobson381
The empirical ones do! There's still a healthy sports car element to the scene though, at least in my experience.
virgil_disgr4ce
Well, reduced sibilance is an ordinary and desirable thing. A better "audiophile absurdity" example would be $77,000 cables, freezing CDs to improve sound quality, using hospital-grade outlets, cryogenically frozen outlets (lol), the list goes on and on
Q6T46nT668w6i3m
It’s always been this way with LLMs.
krat0sprakhar
> Not much explanation yet why GPT-5 warrants a major version bump
Exactly. Too many videos - too little real data / benchmarks on the page. Will wait for vibe check from simonw and others
collinmanderson
> Will wait for vibe check from simonw
https://openai.com/gpt-5/?video=1108156668
2:40 "I do like how the pelican's feet are on the pedals." "That's a rare detail that most of the other models I've tried this on have missed."
4:12 "The bicycle was flawless."
5:30 Re generating documentation: "It nailed it. It gave me the exact information I needed. It gave me full architectural overview. It was clearly very good at consuming a quarter million tokens of rust." "My trust issues are beginning to fall away"
Edit: ohh he has blog post now: https://news.ycombinator.com/item?id=44828264
dimitri-vs
This effectively kills this benchmark.
WD-42
It has the last ~6 months worth of flavor of the month Javascript libraries in it's training set now, so it's "better at coding".
How is this sustainable.
sethops1
Who said anything about sustainable? The only goal here is to hobble to the next VC round. And then the next, and the next, ...
jcgrillo
Vast quantities of extremely dumb money
some-guy
As someone who tries to push the limits of hard coding tasks (mainly refactoring old codebases) to LLMs with not much improvement since the last round of models, I'm finding that we are hitting the reduction of rate of improvement on the S-curve of quality. Obviously getting the same quality cheaper would be huge, but the quality of the output day to day isn't noticeable to me.
camdenreslink
I find it struggles to even refactor codebases that aren't that large. If you have a somewhat complicated change that spans the full stack, and has some sort of wrinkle that makes it slightly more complicated than adding a data field, then even the most modern LLMs seem to trip on themselves. Even when I tell it to create a plan for implementation and write it to a markdown file and then step through those steps in a separate prompt.
Not that it makes it useless, just that we seem to not "be there" yet for the standard tasks software engineers do every day.
scosman
There's a bunch of benchmarks on the intro page including AIME 2025 without tools, SWE-bench Verified, Aider Polyglot, MMMU, and HealthBench Hard (not familiar with this one): https://openai.com/index/introducing-gpt-5/
Pretty par for course evals at launch setup.
nicetryguy
Yeah. We're entered the Smartphone stage: "You want the new one because it's the new one."
anthonypasq
its >o3 performance at gpt4 price. seems pretty obvious
thegeomaster
o3 pricing: $8/Mtok out
GPT-5 pricing: $10/Mtok out
What am I missing?
mitkebes
O3 has had some major price cuts since Gemini 2.5 Pro came out. At the time, o3 cost $10/Mtok in and $40/Mtok out. The big deal with Gemini 2.5 Pro was it had comparable quality to o3 at a fraction of the cost.
I'm not sure when they slashed the o3 pricing, but the GPT-5 pricing looks like they set it to be identical to Gemini 2.5 Pro.
If you scroll down on this page you can see what different models cost when 2.5 Pro was released: https://deepmind.google/models/gemini/pro/
throwaway0123_5
It seems like you might need less output tokens for the same quality of response though. One of their plots shows o3 needing ~14k tokens to get 69% on SWE-bench Verified, but GPT-5 needing only ~4k.
anthonypasq
pretty sure reduced cache input pricing is a pretty big deal for reasoning models, but im not positive
null
doctoboggan
Watching the livestream now, the improvement over their current models on the benchmarks is very small. I know they seemed to be trying to temper our expectations leading up to this, but this is much less improvement than I was expecting
827a
I have a suspicion that while the major AI companies have been pretty samey and competing in the same space for a while now, the market is going to force them to differentiate a bit, and we're going to see OpenAI begin to lose the race toward extremely high levels of intelligence instead choosing to focus on justifying their valuations by optimizing cost and for conversational/normal intelligence/personal assistant use-cases. After all, most of their users just want to use it to cheat at school, get relationship advice, and write business emails. They also have Ive's company to continue investing in.
Meanwhile, Anthropic & Google have more room in their P/S ratios to continue to spend effort on logarithmic intelligence gains.
Doesn't mean we won't see more and more intelligent models out of OpenAI, especially in the o-series, but at some point you have to make payroll and reality hits.
juped
I think this is pretty much what we've already seen happening, in fact.
anyg
Also, the code demos are all using GPT-5 MAX on Cursor. Most of us will not be able to use it like that all the time. They should have showed it without MAX mode as well
z7
GPT-5 is #1 on WebDev Arena with +75 pts over Gemini 2.5 Pro and +100 pts over Claude Opus 4:
virgildotcodes
This same leaderboard lists a bunch of models, including 4o, beating out Opus 4, which seems off.
afro88
In my experience Opus 4 isn't as good for day to day coding tasks as Sonnet 4. It's better as a planner
Workaccount2
Sam said maybe two years ago that they want to avoid "mic drop" releases, and instead want to stick to incremental steps.
This is day one, so there is probably another 10-20% in optimizations that can be squeezed out of it in the coming months.
bigmadshoe
Then why increment the version number here? This is clearly styled like a "mic drop" release but without the numbers to back it up. It's a really bad look when comparing the crazy jump from GPT3 to GPT4 to this slight improvement with GPT5.
camdenreslink
GPT-5 was highly anticipated and people have thought it would be a step change in performance for a while. I think at some point they had to just do it and rip the bandaid off, so they could move past 5.
brokencode
The fact that it unifies the regular model and the reasoning model is a big change. I’m sure internally it’s a big change, but also in terms of user experience.
I feel it’s worthy of a major increment, even if benchmarks aren’t significantly improved.
dpoloncsak
Honestly, I think the big thing is the sycophancy. It's starting to reach the mainstream that ChatGPT can cause people to 'go crazy'.
This gives them an out. "That was the old model, look how much better this one tests on our sycophancy test we just made up!!"
Workaccount2
Because it is a 100x training compute model over 4.
GPT5.5 will be a 10X compute jump.
4.5 was 10x over 4.
yahoozoo
He said that because even then he saw the writing on the wall that LLMs will plateau.
hodgehog11
The hallucination benchmarks did show major improvement. We know existing benchmarks are nearly useless at this point. It's reliability that matters more.
jama211
I’m more worried about how they still confidently reason through things incorrectly all the time, which isn’t quite the same as hallucination, but it’s in a similar vein.
og_kalu
I mean that's just the consequence of releasing a new model every couple months. If Open AI stayed mostly silent since the GPT-4 release (like they did for most iterations) and only now released 5 then nobody would be complaining about weak gains in benchmarks.
moduspol
Well it was their choice to call it GPT 5 and not GPT 4.2.
og_kalu
It is significantly better than 4, so calling it 4.2 would be rather silly.
jononor
If everyone else had stayed silent as well, then I would agree. But as it is right now they are juuust about managing to match the current pace of the other contenders. Which actually is fine, but they have previously set quite high expectations. So some will probably be disappointed at this.
wahnfrieden
It is at least much cheaper and seems faster.
They also announced gpt-5-pro but I haven't seen benchmarks on that yet.
doctoboggan
I am hoping there is a "One more thing" that shows the pro version with great benchmark scores
lawlessone
im sure i am repeating someone else but sounds like we're coming over the s-curve
Bluestein
My thought exactly.-
Diminished returns.-
... here's hoping it leads to progress.-
kybernetikos
ChatGPT5 in this demo:
> For an airplane wing (airfoil), the top surface is curved and the bottom is flatter. When the wing moves forward:
> * Air over the top has to travel farther in the same amount of time -> it moves faster -> pressure on the top decreases.
> * Air underneath moves slower -> pressure underneath is higher
> * The presure difference creates an upward force - lift
Isn't that explanation of why wings work completely wrong? There's nothing that forces the air to cover the top distance in the same time that it covers the bottom distance, and in fact it doesn't. https://www.cam.ac.uk/research/news/how-wings-really-work
Very strange to use a mistake as your first demo, especially while talking about how it's phd level.
peterdsharpe
Yes, it is completely wrong. If this were a valid explanation, flat-plate airfoils could not generate lift. (They can.)
Source: PhD on aircraft design
timr
Except it isn't "completely wrong". The article the OP links to says it explicitly:
> “What actually causes lift is introducing a shape into the airflow, which curves the streamlines and introduces pressure changes – lower pressure on the upper surface and higher pressure on the lower surface,” clarified Babinsky, from the Department of Engineering. “This is why a flat surface like a sail is able to cause lift – here the distance on each side is the same but it is slightly curved when it is rigged and so it acts as an aerofoil. In other words, it’s the curvature that creates lift, not the distance.”
The meta-point that "it's the curvature that creates the lift, not the distance" is incredibly subtle for a lay audience. So it may be completely wrong for you, but not for 99.9% of the population. The pressure differential is important, and the curvature does create lift, although not via speed differential.
I am far from an AI hypebeast, but this subthread feels like people reaching for a criticism.
ttoinou
I would say a wing with two sides of different length is more difficult to understand than one shape with two sides of opposites curvatures but same length
boombapoom
except we were promised to have "PHDs in our pocket" which would mean that this falls short on the sales expectations...
avs733
the wrongness isn't germane to most people but it is a specific typology of how LLMs get technica lthings wrong that is critically important to progressing them. It gets subtle things wrongby being biased towards lay understandings that introduce vagueness because greater precision isn't useful.
That doesn't matter for lay audieces and doesn't really matter at all until we try and use them for technical things.
carabiner
It's the "same amount of time" part that is blatantly wrong. Yes geometry has an effect but there is zero reason to believe leading edge particles, at the same time point, must rejoin at the trailing edge of a wing. This is a misconception at the level of "heavier objects fall faster." It is non-physical.
The video in the Cambridge link shows how the upper surface particles greatly overtake the lower surface flow. They do not rejoin, ever.
nilsherzig
Looks like OpenAI delivered on the PhD response
antisthenes
GPT-6 will just go on forums and pretend to be a girl that needs help with homework.
ge96
What is the actual answer? I know the "skipping stone" idea is wrong too, thinking it's just angle of attack
bilsbie
Angle of attack is a big part but I think the other thing going on is air “sticks” to the surface of the top of the wing and gets directed downward as it comes off the wing. It also creates a gap as the wing curves down leaving behind lower pressure from that.
base698
Weight of the air deflecting downward. Plain ole Newtonian equal and opposite reaction.
qq66
Air pushes on the wing. The control surfaces determine in which direction.
dist-epoch
TL;DR; - it's complicated
WithinReason
And flying upside down would be impossible
null
null
null
ActionHank
This sort of tracks for my experience with LLMs.
They spout common knowledge on a broad array of subjects and it's usually incorrect to anyone who has some knowledge on the subject.
ricardobayes
To me, it's weird to call it "PhD-level". That, to me, means to be able to take in existing information on a certain very niche area and able to "push the boundary". I might be wrong but to date I've never seen any LLM invent "new science", that makes PhD, really PhD. It also seems very confusing to me that many sources mention "stone age" and "PhD-level" in the same article. Which one is it?
People seem to overcomplicate what LLM's are capable of, but at their core they are just really good word parsers.
tshaddox
It's an extremely famous example of a widespread misconception. I don't know anything about aeronautical engineering but I'm quite familiar with the "equal transit time fallacy."
xboxnolifes
Yeah, it's what I was taught in high school.
7734128
Extremely common misconception. NASA even has a website about how it's incorrect
https://www.grc.nasa.gov/www/k-12/VirtualAero/BottleRocket/a...
tths
Yeah, the explanation is just shallow enough to seem correct and deceive someone who doesn't grasp really well the subject. No clue how they let it pass, that without mentioning the subpar diagram it created, really didn't seem like something miles better than what previous models can do already.
Vegenoid
> No clue how they let it pass
It’s very common to see AI evangelists taking its output at face value, particularly when it’s about something that they are not an expert in. I thought we’d start seeing less of this as people get burned by it, but it seems that we’re actually just seeing more of it as LLMs get better at sounding correct. Their ability to sound correct continues to increase faster than their ability to be correct.
chasd00
This is just like the early days of Google search results, "It's on the Internet, it must be true".
traceroute66
Hilarious how the team spent so much time promising GPT5 had fewer hallucinations and deceptions.
Meanwhile the demo seems to suggest business as usual for AI hallucinations and deceptions.
theappsecguy
This is the headline for all LLM output past "hello world"
stanmancan
> Yeah, the explanation is just shallow enough to seem correct and deceive someone who doesn't grasp really well the subject.
This is the problem with AI in general.
When I ask it about things I already understand, it’s clearly wrong quite often.
When I ask it about something I don’t understand, I have no way to know if its response is right or wrong.
adioe3
Nobody explains it as well as Bartosz: https://ciechanow.ski/airfoil/
2StepsOutOfLine
During the demo they quickly shuffled off of, the air flow lines completely broke. It was just a few dots moving left to right, changing the angle of the surface showed no visual difference in airflow.
arcumaereum
Yeah I'm surprised they used that example. The correct (and PhD-level) response would have been to refuse or redirect to a better explanation
tylermw
What's going on with this plot's y-axis?
haffi112
It makes it look like the presentation is rushed or made last minute. Really bad to see this as the first plot in the whole presentation. Also, I would have loved to see comparisons with Opus 4.1.
Edit: Opus 4.1 scores 74.5% (https://www.anthropic.com/news/claude-opus-4-1). This makes it sound like Anthropic released the upgrade to still be the leader on this important benchmark.
danpalmer
> like the presentation is rushed or made last minute
Or written by GPT-5?
rrrrrrrrrrrryan
This is hilarious
moritzwarhier
Probably created without thinking enabled. Lower % accuracy ensues, speaking from experience.
lysecret
Couldn’t believe it was real haha
bufferoverflow
[dead]
artemonster
[flagged]
dang
Please don't post like this to Hacker News, regardless of how idiotic other people are or you feel they are.
You may not owe people who you feel are idiots better, but you owe this community better if you're participating in it.
https://www.youtube.com/watch?v=0Uu_VJeVVfo