Most RESTful APIs aren't really RESTful
328 comments
·July 9, 2025cjpearson
PaulHoule
Fielding won the real battle precisely because he was intellectually incoherent and mostly wrong. It's the "worse is better" of the 21st century.
RPC systems were notoriously unergonomic and at best marginally successful. See Sun RPC, RMI, DCOM, CORBA, XML-RPC, SOAP, Protocol Buffers, etc.
People say it is not RPC but all the time we write some function in Javascript like
const getItem = async (itemId) => { ... }
GET /item/{item_id}
Item getItem(String itemId) { ... }
majkinetor
Amen. Particularly ISO8601.
motorest
> I sympathize with the pedantry here and found Fielding's paper to be interesting, but this is a lost battle.
Why do people feel compelled to even consider it to be a battle?
As I see it, the REST concept is useful, but the HATEOAS detail ends up having no practical value and creates more problems than the ones it solves. This is in line with the Richardson maturity model[1], where the apex of REST includes all the HATEOAS bells and whistles.
Should REST without HATEOAS classify as REST? Why not? I mean, what is the strong argument to differentiate an architectural style that meets all but one requirement? And is there a point to this nitpicking if HATEOAS is practically irrelevant and the bulk of RESTful APIs do not implement it? What's the value in this nitpicking? Is there any value to cite thesis as if they where Monty Python skits?
cle
For me the battle is with people who want to waste time bikeshedding over the definition of "REST" and whether the APIs are "RESTful", with no practical advantages, and then having to steer the conversation--and their motivation--towards more useful things without alienating them. It's tiresome.
reactordev
I’m with you. HATEOAS is great when you have two independent (or more) enterprise teams with PMs fighting for budget.
When it’s just yours and your two pizza team, contract-first-design is totally fine. Just make sure you can version your endpoints or feature-flag new API’s so it doesn’t break your older clients.
cryptonector
Defining media types seems right to me, but what ends up happening is that you use swagger instead to define APIs and out the window goes HATEOAS, and part of the reason for this is just that defining media types is not something people do (though they should).
Basically: define a schema for your JSON, use an obvious CRUD mapping to HTTP verbs for all actions, use URI local-parts embedded in the JSON, use standard HTTP status codes, and embed more error detail in the JSON.
ivan_gammel
>the HATEOAS detail ends up having no practical value and creates more problems than the ones it solves.
Many server-rendered websites support REST by design: a web page with links and forms is the state transferred to client. Even in SPAs, HATEOAS APIs are great for shifting business logic and security to server, where it belongs. I have built plenty of them, it does require certain mindset, but it does make many things easier. What problems are you talking about?
guru4consulting
complexity
commandlinefan
We should probably stop calling the thing that we call REST, REST and be done with it - it's only tangentially related to what Fielding tried to define.
motorest
> We should probably stop calling the thing that we call REST (...)
That solves no problem at all. We have Richardson maturity model that provides a crisp definition, and it's ignored. We have the concept of RESTful, which is also ignored. We have RESTless, to contrast with RESTful. Etc etc etc.
None of this discourages nitpickers. They are pedantic in one direction, and so lax in another direction.
Ultimately it's all about nitpicking.
troupo
> but the HATEOAS detail ends up having no practical value and creates more problems than the ones it solves.
Only because we never had the tools and resources that, say, GraphQL has.
And now everyone keeps re-inventing half of HTTP anyway. See this diagram https://raw.githubusercontent.com/for-GET/http-decision-diag... (docs https://github.com/for-GET/http-decision-diagram/tree/master...) and this: https://github.com/for-GET/know-your-http-well
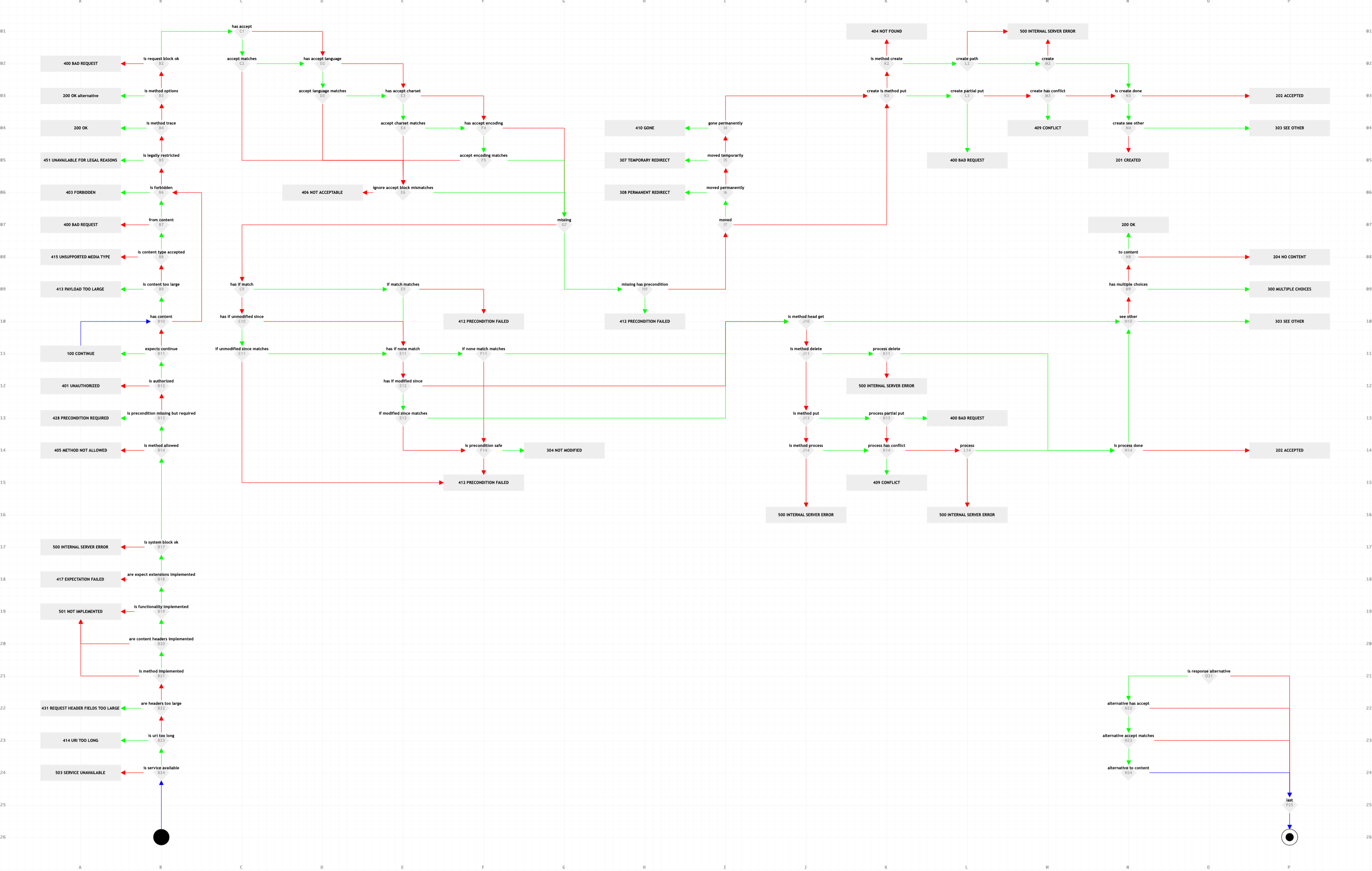{kind=link}
naasking
HATEOAS adds lots of practical value if you care about discoverability and longevity.
montroser
Discoverability by whom, exactly? Like if it's for developer humans, then good docs are better. If it's for robots, then _maybe_ there's some value... But in reality, it's not for robots.
HATEOAS solves a problem that doesn't exist in practice. Can you imagine an API provider being like, "hey, we can go ahead and change our interface...should be fine as long as our users are using proper clients that automatically discover endpoints and programmatically adapt accordingly"? Or can you imagine an API consumer going, "well, this HTTP request delivers the data we need, but let's make sure not to hit it directly -- instead, let's recursively traverse a graph of requests each time to make sure this is still the way to do it!"
cable
LLMs also appear to have an easier time consuming it (not surprisingly.)
programmarchy
For most APIs that doesn’t deliver any value which can’t be gained from API docs, so it’s hard to justify. However, these days it could be very useful if you want an AI to be able to navigate your API. But MCP has the spotlight now.
yieldcrv
100% agreed, “language evolves”
This article also tries to make the distinction of not focusing on the verbs themselves. That the RESTful dissertation doesn’t focus on them.
The other side of this is that the IETF RESTful proposals from 1999 that talk about the protocol for implementation are just incomplete. The obscure verbs have no consensus on their implementation and libraries across platforms may do PUT, PATCH, DELETE incompatibly. This is enough reason to just stick with GET and POST and not try to be a strict REST adherents since you’ll hit a wall.
null
eska
While I ask people whether they actually mean REST according to the paper or not, I am one of the people who refuse to just move on. The reason being that the mainstream use of the term doesn’t actually mean anything, it is not useful, and therefore not pragmatic at all. I basically say “so you actually just mean some web API, ok” and move on with that. The important difference being that I need to figure out the peculiarities of each such web API.
osigurdson
>> The important difference being that I need to figure out the peculiarities of each such web API
So if they say it is Roy Fielding certified, you would not have to figure out any "peculiarities"? I'd argue that creating a typical OpenAPI style spec which sticks to standard conventions is more professional than creating a pedantically HATEOAS API. Users of your API will be confused and confusion leads to bugs.
infecto
So you enjoy being pedantic for the sake of being pedantic? I see no useful benefit either from a professional or social setting to act like this.
I don’t find this method of discovery very productive and often regardless of meeting some standard in the API the real peculiarities are in the logic of the endpoints and not the surface.
hiAndrewQuinn
I can see a value in pedantry in a professional setting from a signaling point of view. It's a cheap way to tell people "Hey! I'm not like those other girls, I care about quality," without necessarily actually needing to do the hard work of building that quality in somewhere where the discerning public can actually see your work.
(This is not a claim that the original commenter doesn't do that work, of course, they probably do. Pedants are many things but usually not hypocrites. It's just a qualifier.)
You'd still probably rather work with that guy than with me, where my preferred approach is the opposite of penalty. I slap it all together and rush it out the door as fast as possible.
andoando
REST is pretty much impossible to adhere to for any sufficiently complex and we should just toss it in the garbage
calvinmorrison
REST means, generally, HTTP requests with json as a result.
hombre_fatal
It also means they made some effort to use appropriate http verbs instead of GET/POST for everything, and they made an effort to organize their urls into patterns like `/things/:id/child/:child_id`.
It was probably an organic response to the complexity of SOAP/WSDL at the time, so people harping on how it's not HATEOAS kinda miss the historical context; people didn't want another WSDL.
marcosdumay
I really hate my conclusions here, but from a limited freedom point of view, if all of that is going to happen...
> The team constantly bikesheds over correct status codes and at least a few are used contrary to the HTTP spec
So we should better start with a standard scaffolding for the replies so we can encode the errors and forget about status codes. So the only thing generating an error status is unhandled exception mapped to 500. That's the one design that survives people disagreeing.
> There's a decent chance listing endpoints were changed to POST to support complex filters
So we'd better just standardize that lists support both GET and POST from the beginning. While you are there, also accept queries on both the url and body parameters.
Cthulhu_
HTTP/JSON API works too, but you can assume it's what they mean by REST.
It makes me wish we stuck with XML based stuff, it had proper standards, strictly enforced by libraries that get confused by things not following the standards. HTTP/JSON APIs are often hand-made and hand-read, NIH syndrone running rampant because it's perceived to be so simple and straightforward. To the point of "we don't need a spec, you can just see the response yourself, right?". At least that was the state ~2012, nowadays they use an OpenAPI spec but it's often incomplete, regardless of whether it's handmade (in which case people don't know everything they have to fill in) or generated (in which case the generators will often have limitations and MAYBE support for some custom comments that can fill in the gaps).
motorest
> HTTP/JSON API works too, but you can assume it's what they mean by REST.
This is the kind of slippery slope where pedantic nitpickers thrive. The start to complain that if you accept any media type other than JSON then it's not "REST-adjacent" anymore because JSON is in the name and some bloke wrote down somewhere that JSON was a trait of this architectural style.
In this sense, the term "RESTful" is useful to shut down these pedantic nitpickers. It's "REST-adjacent" still, but the right answer to nitpicking is "who cares".
troupo
> The start to complain that if you accept any media type other than JSON then it's not "REST-adjacent" anymore because JSON is in the name and some bloke wrote down somewhere that JSON was a trait of this architectural style.
wat?
Nowhere is JSON in the name of REpresentational State Transfer. Moreover, sending other representations than JSON (and/or different presentations in JSON) is not only acceptable, but is really a part of REST
ivan_gammel
This. Or maybe we should call it "Rest API" in lowercase, meaning not the state transfer, but the state of mind, where developer reached satisfaction with API design and is no longer bothered with hypermedia controls, schemas etc.
harha_
I recall having to maintain an integration to some obscure SOAP API that ate and spit out XML with strict schemas and while I can't remember much about it, I think the integration broke quite easily if the other end changed their API somehow.
Zambyte
Assuming the / was meant to describe it as both an HTTP API and a JSON API (rather than HTTP API / JSON API) it should be JSON/HTTP, as it is JSON over HTTP, like TCP/IP or GNU/Linux :)
marcosdumay
> it had proper standards
Lol. Have you read them?
SOAP in particular can really not be described as "proper".
It had the advantage that the API docs were always generated, and thus correct, but the most common thing is for one software stack not being able to use a service built with another stack.
pantulis
> The team constantly bikesheds over correct status codes and at least a few are used contrary to the HTTP spec
I had to chuckle here. So true!
mixedbit
When I was working on my first HTTP-based API 13 years ago, based on many comments about true REST, I decided to first study what REST should really be. I've read Fielding's paper cover to cover, I've read RESTful Web Services Cookbook from O'Reilly and then proceeded to workaround Django idioms to provide REST API. This was a bit cargo cult thinking from my end, I didn't truly understand how REST would benefit my service. I took me several more years and several more HTTP APIs to understand that in the case of these services, there were no benefits.
The vision of API that is self discoverable and that works with a generic client is not practical in most cases. I think that perhaps AWS dashboard with its multitude of services has some generic UI code that allows to handle these services without service-specific logic, but I doubt even that.
Fielding's paper doesn't provide a complete recipe for building self-discoverable APIs. It is an architecture, but the details of how clients should really discover the endpoints and determine what these endpoints are doing is left out of the paper. To make truly discoverable API you need to specify protocol for endpoints discovery, operations descriptions, help messages etc. Then you need clients that understand your specification, so it is not really a generic client. If your service is the only one that implements this client, you made a lot of extra effort to end up with the same solution that not REST services implement - a service provides an API and JS code to work with the API (or a command line client that works with the API), but there is no client code reuse at all.
I also think that good UX is not compatible with REST goals. From a user perspective, app-specific code can provide better UX than generic code that can discover endpoints and provide UI for any app. Of course, UI elements can be standardized and described in some languages (remember XUL?), so UI can adapt to app requirements. But the most flexible way for such standardization is to provide a language like JavaScript that is responsible for building UI.
rswail
The browser is "generic code" that provides the UX we use all day, every day.
REST includes allowing code to be part of the response from a server, there are the obvious security issues, but the browsers (and the standards) have dealt with a lot of that.
https://ics.uci.edu/~fielding/pubs/dissertation/net_arch_sty...
pradn
I think you're right. APIs have a lot of aspects to them, so describing them is hard. API users need to know typical latency bounds, which error codes may be retried, whether an action is atomic or idempotent. HATEOAS gets you none of these things.
So fully implementing a perfect version of REST is usually not necessary for most types of problems users actually encounter.
What REST has given us is an industry-wide lingua franca. At the basic level, it's a basic understanding of how to map nouns/verbs to HTTP verbs and URLs. Users get to use the basic HTTP response codes. There's still a ton of design and subtlety to all this. Do you really get to do things that are technically allowed, but might break at a typical load balancer (returning bodies with certain error codes)? Is your returning 500 retriable in all cases, with what preferred backoff behavior?
ivan_gammel
>API users need to know typical latency bounds, which error codes may be retried, whether an action is atomic or idempotent. HATEOAS gets you none of these things.
Those things aren't always necessary. However API users always need to know which endpoints are available in the current context. This can be done via documentation and client-side business logic implementing it (arguably, more work) or this can be done with HATEOAS (just check if server returned the endpoint).
HTTP 500 retriable sounds like a design error, when you can use HTTP 503 to explicitly say "try again later, it's temporal".
ralferoo
I think this hits the nail on the head. Complaining that the current understanding of REST isn't exactly the same as the original usage is missing the point that now REST gives people a good idea of what to expect and how to use the exposed interface.
It's actually a very analogous complaint to how object-oriented programming isn't how it was supposed to be and that only Smalltalk got it right. People now understand what is meant when people say OOP even if it's not what the creator of the term envisioned.
Computer Science, and even the world in general, is littered with examples of this process in action. What's important is that there's a general consensus of the current meaning of a word.
pradn
Yes, the field is littered with imperfection.
One thing though - if you do take the time to learn the original "perfect" versions of these things, it helps you become a much better system designer. I'm constantly worried about API design because it has such large and hard-to-change consequences.
On the other hand, we as an industry have also succeeded quite a bit! So many of our abstractions work really well.
kccqzy
It's not just the original REST that usually has no benefits. The industry's reinterpreted version of weak REST also usually has little to no benefits. Who really cares that deleting a resource must necessarily be done with the DELETE HTTP verb rather than simply a POST?
cryptonector
You have to represent the action somehow. And letting proxies understand a wee bit of what's going on is useful. That's how you can have a proxy that lets your users browse the web but not login to external sites, and so on.
s_ting765
The DELETE verb exists, there's no reason not to use it.
Balooga
There is one reason. The DELETE absolutely must be idempotent. If it's not, then use POST.
marcosdumay
The POST verb exists, there's no reason not to use it to ask a server to delete data.
In fact, there are plenty of reasons not to use DELETE and PUT. Middleboxes managed by incompetent security people block them, they require that developers have a minimum of expertise and don't break the idempotency rule, lots of software stacks simply don't support them (yeah, those stacks are bad, what still doesn't change anything), and the most of the internet just don't use the benefit they provide (because they don't trust the developers behind the server to not break the rules).
kccqzy
And you just added more work to yourself to interpret the HTTP verb. You already need work to interpret the body of a POST request, so why not put the information of "the operation is trying to delete" inside the body?
naasking
> To make truly discoverable API you need to specify protocol for endpoints discovery, operations descriptions, help messages etc. Then you need clients that understand your specification, so it is not really a generic client.
Generic clients just need to understand hypermedia and they can discover your API, as long as your API returns hypermedia from its starting endpoint and all other endpoints are transitively linked from that start point.
Let me ask you this: if I gave you an object X in your favourite OO language, could you use your languages reflection capabilities to discover all properties of every object transitively reachable from X, and every method that could be called on X and all objects transitively reachable from X? Could you not even invoke many of those methods assuming the parameter types are mostly standardized objects or have constructors that accept standardized objects?
This is what discoverability via HATEOAS is. True REST can be seen as exporting an object model with reflection capabilities. For clients that are familiar with your API, they are using hypermedia to access known/named properties and methods, and generic clients can use reflection to do the same.
mixedbit
> Let me ask you this: if I gave you an object X in your favourite OO language, could you use your languages reflection capabilities to discover all properties of every object transitively reachable from X, and every method that could be called on X and all objects transitively reachable from X? Could you not even invoke many of those methods assuming the parameter types are mostly standardized objects or have constructors that accept standardized objects?
Sure this can be done, but I can't see how to build a useful generic app that interacts with objects automatically by discovering the methods and calling them with discovered parameters. For things like debugger, REPL, or some database inspection/manipulation tool, this approach is useful, but for most apps exposed to end users, the UI needs to be aware what the available methods do and need to be intentionally designed to provide intuitive ways of calling the methods.
naasking
> For things like debugger, REPL, or some database inspection/manipulation tool, this approach is useful, but for most apps exposed to end users
Yes, exactly, but the point is that something like Swagger becomes completely trivial, and so you no longer need a separate, complex tool to do what the web automatically gives you.
The additional benefits are on the server-end, in terms of maintenance and service flexibility. For instance, you can now replace and transition any endpoint URL (except the entry endpoint) at any time without disrupting clients, as clients no longer depend on specific URL formats (URLs are meaningful only to the server), but depend only on the hypermedia that provides the endpoints they should be using. This is Wheeler's aphorism: hypermedia adds one level of indirection to an API which adds all sorts of flexibility.
For example, you could have a set of servers implementing an application function, each designated by a different URL, and serve the URL for each server in the hypermedia using any policy that makes sense, effectively making an application-specific load balancer. We worked around scaling issues over the years by adding adding SNI to TLS and creating dedicated load balancers, but Fielding's REST gave us everything we needed long before! And it's more flexible than SNI because these servers don't even have to be physically located behind a load balancer.
shadowgovt
> Generic clients just need to understand hypermedia
Yikes. Nobody wants to implement a browser to create a UI for ordering meals from a restaurant. I'm pretty sure the reason we ended up settling on just tossing JSON blobs around and baking the semantics of them into the client is that we don't want the behavior of the application to get tripped up on whether someone failed to close a <b> tag.
(Besides: practically, for a web-served interface, the client may as well carry semantic understanding because the client came from the server).
naasking
> Yikes. Nobody wants to implement a browser to create a UI for ordering meals from a restaurant.
You don't need a full web browser. Fielding published his thesis in 2000, browsers were almost trivial then, and the needs for programming are even more trivial: you can basically skip any HTML that isn't a link tag or form data for most purposes.
> baking the semantics of them into the client is that we don't want the behavior of the application to get tripped up on whether someone failed to close a <b> tag.
This is such a non-issue. Why aren't you worried about badly formatted JSON? Because we have well-tested JSON formatters. In a world where people understood the value of hypermedia as an interchange format, we'd be in exactly the same position.
And to be clear, if JSON had links as a first class type rather than just strings, then that would qualify as a hypermedia format too.
Balooga
> Fielding's paper doesn't provide a complete recipe for building self-discoverable APIs.
But it does though. A HTTP server returns a HTTP response to a request from a browser. The request is a HTML webpage that is rendered to the user with all discoverable APIs visible as clickable links. Welcome to the World Wide Web.
mixedbit
You describe how web pages work, web pages are intended for human interactions, APIs are intended for machine interaction. How a generic Python or JavaScript client can discover these APIs? Such clients will request JSON representation of a resource, because JSON is intended for machine consumption, HTML is intended for humans. Representations are equivalent, if you request JSON representations of a /users resource, you get a JSON list. If you request HTML representation of a /users resource you get an HTML list, but the content should be the same. Should you return UI controls for modifying a list as part of the HTML representation? If you do so, your JSON and HTML representations are different, and your Python and JavaScript client still cannot discover what list modification operations are possible, only human can do it by looking at the HTML representation. This is not REST if I understand the paper correctly.
Balooga
> You describe how web pages work, web pages are intended for human interactions
Exactly, yes! The first few sentences from Wikipedia...
"REST (Representational State Transfer) is a software architectural style that was created to describe the design and guide the development of the architecture for the World Wide Web. REST defines a set of constraints for how the architecture of a distributed, Internet-scale hypermedia system, such as the Web, should behave." -- [1]
If you are desiging a system for the Web, use REST. If you are designing a system where a native app (that you create) talks to a set of services on a back end (that you also create), then why conform to REST principles?
ohdeargodno
[dead]
salmonellaeater
Where this kind of API design is useful is when there is a user with an agent (e.g. a browser or similar) who can navigate the API and interact with the different responses based on their media types and what the links are called.
Most web APIs are not designed with this use-case in mind. They're designed to facilitate web apps that are much more specific in what they're trying to present to the user. This is both deliberate and valuable; app creators need to be able to control the presentation to achieve their apps' goals.
REST API design is for use-cases where the users should have control over how they interact with the resources provided by the API. Some examples that should be using REST API design:
- Government portals for publicly accessible information, like legal codes, weather reports, or property records
- Government portals for filing forms and other interactions
- Open data initiatives like Wikipedia and OpenStreetmap
cryptonector
> Where this kind of API design is useful is when there is a user with an agent (e.g. a browser or similar) who can navigate the API and interact with the different responses based on their media types and what the links are called.
It's also useful when you're programming a client that is not a web page!
You GET a thing, you dereference fields/paths in the returned representation, you construct a new URI, you perform an operation on it, and so on.
Consider a directory / database application. You can define a RESTful, HATEOAS API for it, write a single-page web application for it -or a non-SPA if you prefer-, and also write libraries and command-line interfaces to the same thing, all using roughly similar code that does what I described above. That's pretty neat. In the case of a non-SPA you can use pure HTML and not think that you're "dereferencing fields of the returned representation", but the user and the user-agent are still doing just that.
ninkendo
> Where this kind of API design is useful is when there is a user with an agent (e.g. a browser or similar) who can navigate the API and interact with the different responses based on their media types and what the links are called.
The funny thing is, that perfectly describes HTML. Here’s a document with links to other documents, which the user can navigate based on what the links are called. Because if it’s designed for users, it’s called a User Interface. If it’s designed for application programming, it’s called an Application Programming Interface. This is why HATEOAS is kinda silly to me. It pretends APIs should be used by Users directly. But we already have that, it’s called a UI.
thyristan
The point is that your Web UI can easily be made to be a REST HATEOAS conforming API at the same time. No separate codepaths, no duplicate efforts, just maybe some JSON templates in addition to HTML templates.
wvh
You're right, pure REST is very academic. I've worked with open/big data, and there's always a struggle to get realistic performance and app architecture design; for anything non-obvious, I'd say there are shades of REST rather than a simple boolean yes/no. Even academics have to produce a working solution or "application", i.e. that which can be actually applied, at some point.
thyristan
When there is lots of data and performance is important, HTTP is the wrong protocol. JSON/XML/HTML is the wrong data format.
jonfw
> Where this kind of API design is useful is when there is a user with an agent (e.g. a browser or similar) who can navigate the API and interact with the different responses based on their media types and what the links are called.
> Most web APIs are not designed with this use-case in mind.
I wonder if this will change as APIs might support AI consumption?
Discoverability is very important to an AI, much more so than to a web app developer.
MCP shows us how powerful tool discoverability can be. HATEOS could bring similar benefits to bare API consumption.
sublinear
> Government portals for publicly accessible information, like legal codes, weather reports, or property records
Yes, and it's so nice when done well.
recursivedoubts
This is a very good and detailed review of the concepts of REST, kudos to the author.
One additional point I would add is that making use of the REST-ful/HATEOAS pattern (in the original sense) requires a conforming client to make the juice worth the squeeze:
dwaltrip
I'll never understand why the HATEOAS meme hasn't died.
Is anyone using it? Anywhere?
What kind of magical client can make use of an auto-discoverable API? And why does this client have no prior knowledge of the server they are talking to?
kelseyfrog
I used it on an enterprise-grade video surveillance system. It was great - basically solved the versioning and permissions problem at the API level. We leveraged other RFCs where applicable.
The biggest issue was that people wanted to subvert the model to "make things easier" in ways that actually made things harder. The second biggest issue is that JSON is not, out of the box, a hypertext format. This makes application/json not suitable for HATEOAS, and forcing some hypertext semantics onto it always felt like a kludge.
eadmund
> I'll never understand why the HATEOAS meme hasn't died.
> Is anyone using it? Anywhere?
As I recall ACME (the protocol used by Let’s Encrypt) is a HATEOAS protocol. If so (a cursory glance at RFC 8555 indicates that it may be), then it’s used by almost everyone who serves HTTPS.
Arguably HTTP, when used as it was intended, is itself a HATEOAS protocol.
> What kind of magical client can make use of an auto-discoverable API? And why does this client have no prior knowledge of the server they are talking to?
LLMs seem to do well at this.
And remember that ‘auto-discovery’ means different things. A link typed next enables auto-discovery of the next resource (whatever that means); it assumes some pre-existing knowledge in the client of what ‘next’ actually means.
marcosdumay
> As I recall ACME (the protocol used by Let’s Encrypt) is a HATEOAS protocol.
On this case specifically, everybody's lives are worse because of that.
recursivedoubts
Yes. You used it to enter this comment.
I am using it to enter this reply.
The magical client that can make use of an auto-discoverable API is called a "web browser", which you are using right this moment, as we speak.
ehutch79
So, given a hateos api, and stock firefox (or chrome, or safari, or whatever), it will generate client views with crud functionality?
Let alone ux affordances, branding, etc.
recursivedoubts
Yes. You used such an api to post your reply. And I am using it as well, via the affordances presented by the mobile safari hypermedia client program. Quite an amazing system!
physicles
This is true, but isn’t this quite far away from the normal understanding of API, which is an interface consumed by a program? Isn’t this the P in Application Programming Interface? If it’s a human at the helm, it’s called a User Interface.
recursivedoubts
I agree that's a common understanding of things, but I don't think that it's 100% accurate. I think that a web browser is a client program, consuming a RESTful application programming interface in the manner that RESTful APIs are designed to be consumed, and presenting the result to a human to choose actions.
I think if you restrict the notion of client to "automated programs that do not have a human driving them" then REST becomes much less useful:
https://htmx.org/essays/hypermedia-clients/
https://intercoolerjs.org/2016/05/08/hatoeas-is-for-humans.h...
AI may change this at some point.
didntcheck
The web browser is just following direct commands. The auto discovery and logic is implemented by my human brain
dwaltrip
Wait what? So everything is already HATEOAS?
I thought the “problem” was that no one was building proper restful / HATEOAS APIs.
It can’t go both ways.
myaccountonhn
https://htmx.org/ might be the closest attempt?
rapnie
https://data-star.dev are taking things a bit further in terms of simplicity and performance and hypermedia concepts. Worth a look.
null
motorest
I think OData isn't used, and that's a proper standard and a lower bar to clear. HATEOAS isn't even benefiting from a popular standard, which is both a cause and a result.
_heimdall
You realize that anyone using a browser to view HTML is using HATEOS, right? You could probably argue whether SPAs fit the bill, but for sure any server rendered or static site is using HATEOS.
The point isn't that clients must have absolutely no prior knowledge of the server, its that clients shouldn't have to have complete knowledge of the server.
We've grown used to that approach because most of us have been building tightly coupled apps where the frontend knows exactly how the backend works, but that isn't the only way to build a website or web app.
dwaltrip
Can you be more specific? What exactly is the partial knowledge? And how is that different from non-conforming APIs?
Scarblac
UI designers want control over the look of the page in detail. E.g. some actions that can be taken on a resource are a large button and some are hidden in a menu or not rendered in the UI at all.
A client application that doesn't have any knowledge about what actions are going to be possible with a resource, instead rendering them dynamically based on the API responses, is going to make them all look the same.
So RESTful APIs as described in the article aren't useful for the most common use case of Web APIs, implementing frontend UIs.
ivan_gammel
This is wrong on many levels.
1. UX designers operate on every stage of software development lifecycle from product discovery to post-launch support (validation of UX hypotheses), they do not exercise control - they work within constraints as part of the team. The location of a specific action in UI and interaction triggering it is orthogonal to availability of this action. Availability is defined by the state. If state restricts certain actions, UX must reflect that.
2. From architectural point of view, once you encapsulate the checking state behavior, the following will work the same way: "if (state === something)" and "if (resource.links["action"] !== null)". The latter approach will be much better, because in most cases any state-changing actions will require validation on server and you can implement the logic only once (on server).
I have been developing HATEOAS applications for quite a while and maintain HAL4J library: there are some complexities in this approach, but UI design is certainly not THE problem.
sublinear
My experience with "RESTful APIs" rarely has much to do with the UI. Why even have any API if all you care about is the UI? Why not go back to server driven crap like DWR then?
Scarblac
My experience is that SPAs have been the way to make frontends, for the last eight years or so. May be coming to an end now. Anyway, contact with the backend all went through an API.
During that same time, the business also wanted to use the fact that our applications had an API as a selling point - our customers are pretty technical and some of them write scripts against our backends.
Backenders read about API design, they get the idea they should be REST like (as in, JSON, with different HTTP methods for CRUD operations).
And of course we weren't going to have two separate APIs, that we ran our frontends on our API was another selling point (eat your own dog food, proof that the API can do everything our frontend can, etc).
So: the UI runs on a REST API.
I'm hoping that we'll go back to Django templates with a sprinkle of HTMX here and there in the future, but who knows. That will probably be a separate backend that runs in front of this API then...
sublinear
> our applications had an API as a selling point - our customers are pretty technical and some of them write scripts against our backends
It is a selling point. A massive one if you're writing enterprise software. It's not merely about "being technical", but mandatory for recurring automated jobs and integration with their other software.
ohdeargodno
[dead]
_heimdall
What's often missed when this topic comes up is the question of who the back end API is intended for.
REST and HATEOAS are beneficial when the consumer is meant to be a third party that doesn't directly own the back end. The usual example is a plain old HTML page, the end user of that API is the person using a browser. MCP is a more recent example, that protocol is only needed because they want agents talking to APIs they don't own and need a solution for discoverability and interpretability in a sea of JSON RPC APIs.
When the API consumer is a frontend app written specifically for that backend, the benefits of REST often just don't outweigh the costs. It takes effort to design a more generic, better documented and specified API. While I don't like using tools like tRPC in production, its hugely useful for me when prototyping for much the same reason, I'm building both ends of the app and its faster to ignore separation of concerns.
edit: typo
recursivedoubts
agree very strongly and think it goes even deeper than that!
a3w
*HATEOAS
mschaef
> The core problem it addresses is client-server coupling. There are probably countless projects where a small change in a server’s URI structure required a coordinated (and often painful) deployment of multiple client applications. A HATEOAS-driven approach directly solves this by decoupling the client from the server’s namespace. This addresses the quality of evolvability.
Not sure I agree with this. All it does is move the coupling problem around. A client that doesn't understand where to find a URL in a document (or even which URL's are available for what purpose within that document) is just as bad as a client that assumes the wrong URL structure.
At some point, the client of an API needs to understand the semantics of what that API provides and how/where it provides those semantics. Moving it from a URL hierarchy to a document structure doesn't provide a huge amount of added value. (Particularly in a world where essentially all of the server API's are defined in terms of URL patterns routing to handlers. This is explicit hardcoded encouragement to think in a style in opposition to the HATEOAS philosophy.)
I also tend to think that the widespread migration of data formats from XML to JSON has worked against "Pure" REST/HATEOAS. XML had/has the benefit of a far richer type structure when compared to JSON. While JSON is easier to parse on a superficial level, doing things like identifying times, hyperlinks, etc. is more difficult due to the general lack of standardization of these things. JSON doesn't provide enough native and widespread representations of basic concepts needed for hypertext.
(This is one of those times I'd love some counterexamples. Aside from the original "present hypertext documents to humans via a browser" use case, I'd love to read more about examples of successful programmatic API's written in a purely HATEOAS style.)
physicles
This is what I don’t understand either.
/user/123/orders
How is this fundamentally different than requesting /user/123 and assuming there’s a link called “orders” in the response body?
spankalee
Good.
Strict HATEOAS is bad for an API as it leads to massively bloated payloads. We _should_ encode information in the API documentation or a meta endpoint so that we don't have to send tons of extra information with every request.
alkonaut
Similarly, I call Java programs "Object Oriented programs" despite Alan Kays protests that it isn't at all what Object Orientation was described as in early papers.
The sad truth is that it's the less widely used concept that has to shift terminology, if it comes into wide use for something else or a "diluted" subset of the original idea(s). Maybe the true-OO-people have a term for Kay-like OO these days?
I think the idea of saving "REST" to mean the true Fielding style including HATEOAS and everything is probably as futile as trying to reserve OO to not include C++ or Java.
sublinear
> By using HATEOAS and referencing schema definitions (such as XSD or JSON Schema) from within your resource representations, you can enable clients to understand the structure of the data and navigate the API dynamically.
I actually think this is where the problem lies in the real world. One of the most useful features of a JSON schema is the "additionalProperties" keyword. If applied to the "_links" subschema we're back to the original problem of "out of band" information defining the API.
I just don't see what the big deal is if we have more robust ways of serving the docs somewhere else outside of the JSON response. Would it be equivalent if the only URL in "_links" that I ever populate is a link to the JSONified Swagger docs for the "self" path for the client to consume? What's the point in even having "_links" then? How insanely bloated would that client have to be to consume something that complicated? The templates in Swagger are way more information dense and dynamic than just telling you what path and method to use. There's often a lot more for the client to handle than just CRUD links and there exists no JSON schema that could be consistent across all parts of the API.
gabesullice
> If you are building a public API for external developers you don’t control, invest in HATEOAS. If you are building a backend for a single frontend controlled by your own team, a simpler RPC-style API may be the more practical choice.
My conclusion is exactly the opposite. In-house developers can be expected (read: cajoled) to do things the "right" way, like follow links at runtime. You can run tests against your client and server. Internally, flexible REST makes independent evolution of the front end and back end easy.
Externally, you must cater to somebody who hard-coded a URL into their curl command that runs on cron and whose code can't tolerate the slightest deviation from exactly what existed when the script was written. In that case, an RPC-like call is great and easy to document. Increment from `/v1/` to `/v2/`, writer a BC layer between them and move on.
I sympathize with the pedantry here and found Fielding's paper to be interesting, but this is a lost battle. When I see "REST API" I can safely assume the following:
- The API returns JSON
- CRUD actions are mapped to POST/GET/PUT/DELETE
- The team constantly bikesheds over correct status codes and at least a few are used contrary to the HTTP spec
- There's a decent chance listing endpoints were changed to POST to support complex filters
Like Agile, CI or DevOps you can insist on the original definition or submit to the semantic diffusion and use the terms as they are commonly understood.