Basic Facts about GPUs
57 comments
·June 24, 2025b0a04gl
chickenzzzzu
>GPU was never the botteneck >it was memory layout
ah right so the GPU was the bottleneck then
tough
did you see yesterday nano-vllm [1] from a deepseek employee 1200LOC and faster than vanilla vllm?
jcelerier
did you do a PR to integrate these changes back into llama.cpp ? 2x speedup would be absolutely wild
zargon
Almost nobody using llama.cpp does batch inference. I wouldn’t be surprised if the change is somewhat involved to integrate with all of llama.cpp’s other features. Combined with lack of interest and keeping up with code churn, that would probably make it difficult to get included, with the number of PRs the maintainers are flooded with.
buildxyz
Any speed up that is 2x is definitely worth fixing. Especially since someone has already figured out the issue and performance testing [1] shows that llamacpp* is lagging behind vLLM by 2x. This is a positive for all running LLMs locally using llamacpp.
Even if llamacpp isnt used for batch inference now, this can allow those to finally run llamacpp for batching and on any hardware since vLLM supports only select hardware. Maybe finally we can stop all this gpu api software fragmentation and cuda moat as llamacpp benchmarks have shown Vulkan to be as or more performant than cuda or sycl.
[1] https://miro.medium.com/v2/resize:fit:1400/format:webp/1*lab...
{kind=link}
tough
if you open a PR, even if it doesnt get merged, anyone with the same issue can find it, and use your PR/branch/fix if it suits better their needs than master
zozbot234
It depends, if the optimization is too hardware-dependent it might hurt/regress performance on other platforms. One would have to find ways to generalize and auto-tune it based on known features of the local hardware architecture.
amelius
Yes, easiest is to separate it into a set of options. Then have a bunch of Json/yaml files, one for each hw configuration. From there, the community can fiddle with the settings and share new settings if new hardware is released.
elashri
Good article summarizing good chunk of information that people should have some idea about. I just want to comment that the title is a little bit misleading because this is talking about the very choices that NVIDIA follows in developing their GPU archs which is not what always what others do.
For example, the arithmetic intensity break-even point (ridge-point) is very different once you leave the NVIDIA-land. If we take AMD Instinct MI300, it has up to 160 TFLOPS FP32 paired with ~6 TB/s of HBM3/3E bandwidth gives a ridge-point near 27 FLOPs/byte which is about double that of the A100’s 13 FLOPs/byte. The larger on-package HBM (128 – 256 GB) GPU memory also shifts the practical trade-offs between tiling depth and occupancy. Although this is very expensive and does not have CUDA (which can be good and bad at the same time).
apitman
Unfortunately Nvidia GPUs are the only ones that matter until AMD starts taking their computer software seriously.
fooblaster
They are. It's just not at the consumer hardware level.
have-a-break
You could argue it's all the nice GPU debugging tools nVidia provides which makes GPU programming accessible.
There are so many potential bottlenecks (normally just memory access patterns, but without tools to verify you have to design and run manual experiments).
tucnak
This misconception is repeated time and time again; software support of their datacenter-grade hardware is just as bad. I've had the displeasure of using MI50, MI100 (a lot), MI210 (very briefly.) All three are supposedly enterprise-grade computing hardware, and yet, it was a pathetic experience with a myriad of disconnected components which had to be patched, & married with a very specific kernel version to get ANY kind of LLM inference going.
Now, the last of it I bothered with was 9 months ago; enough is enough.
tucnak
Unfortunately, GPU's are old news now. When it comes to perf/watt/dollar, TPU's are substantially ahead for both training and inference. There's a sparsity disadvantage with the trailing-edge TPU devices such as v4 but if you care about large-scale training of any sort, it's not even close. Additionally, Tenstorrent p300 devices are hitting the market soon enough, and there's lots of promising stuff is coming on Xilinx side of the AMD shop: the recent Versal chips allow for AI compute-in-network capabilities that puts NVIDIA Bluefield's supposed programmability to shame. NVIDIA likes to say Bluefield is like a next-generation SmartNIC, but compared to actually field-programmable Versal stuff, it's more like 100BASE-T cards from the 90s.
I think it's very naive to assume that GPU's will continue to dominate the AI landscape.
menaerus
So, where does one buy a TPU?
almostgotcaught
> Unfortunately, GPU's are old news now
...
> the recent Versal chips allow for AI compute-in-network capabilities that puts NVIDIA Bluefield's supposed programmability to shame
I'm always just like... who are you people. Like what is the profile of a person that just goes around proclaiming wild things as if they're completely established. And I see this kind of comment on hn very frequently. Like you either work for Tenstorrent or you're an influencer or a zdnet presenter or just ... because none of this even remotely true.
Reminds me of
"My father would womanize; he would drink. He would make outrageous claims like he invented the question mark. Sometimes, he would accuse chestnuts of being lazy."
> I think it's very naive to assume that GPU's will continue to dominate the AI landscape
I'm just curious - how much of your portfolio is AMD and how much is NVDA and how much is GOOG?
eapriv
Spoiler: it’s not about how GPUs work, it’s about how to use them for machine learning computations.
oivey
It’s a pretty standard run down of CUDA. Nothing to do with ML other than using relu in an example and mentioning torch.
LarsDu88
Maybe this should be titled "Basic Facts about Nvidia GPUs" as the WARP terminology is a feature of modern Nvidia GPUs.
Again, I emphasize "modern"
An NVIDIA GPU from circa 2003 is completely different and has baked in circuitry specific to the rendering pipelines used for videogames at that time.
So most of this post is not quite general to all "GPUs" which a much broader category of devices that don't necessarily encompass the type of general purpose computation we use modern Nvidia GPUs for.
SoftTalker
Contrasting colors. Use them!
Yizahi
font-weight: 300;
I'm 99% sure that author had designed this website on an Apple Mac with so called "font smoothing" enabled, which makes all regular fonts artificially "semi-bold". So to make a normal looking font, Mac designers use this thinner font weight and then Apple helpfully makes it kinda "normal".
currency
The author might be formatting for and editing in dark mode. I use edge://flags/#enable-force-dark and the links are readable.
jasonjmcghee
If the author stops by- the links and the comments in the code blocks were the ones that I had to use extra effort to read.
It might be worth trying to increase the contrast a bit.
The content is really great though!
kittikitti
This is a really good introduction and I appreciate it. When I was building my AI PC, the deep dive research into GPU's took a few days but this lays it out in front of me. It's especially great because it touches on high-value applications like generative artificial intelligence. A notable diagram from the page that I wasn't able to find represented well elsewhere was the memory hierarchy of the A100 GPU's. The diagrams were very helpful. Thank you for this!
neuroelectron
ASCII diagrams, really?
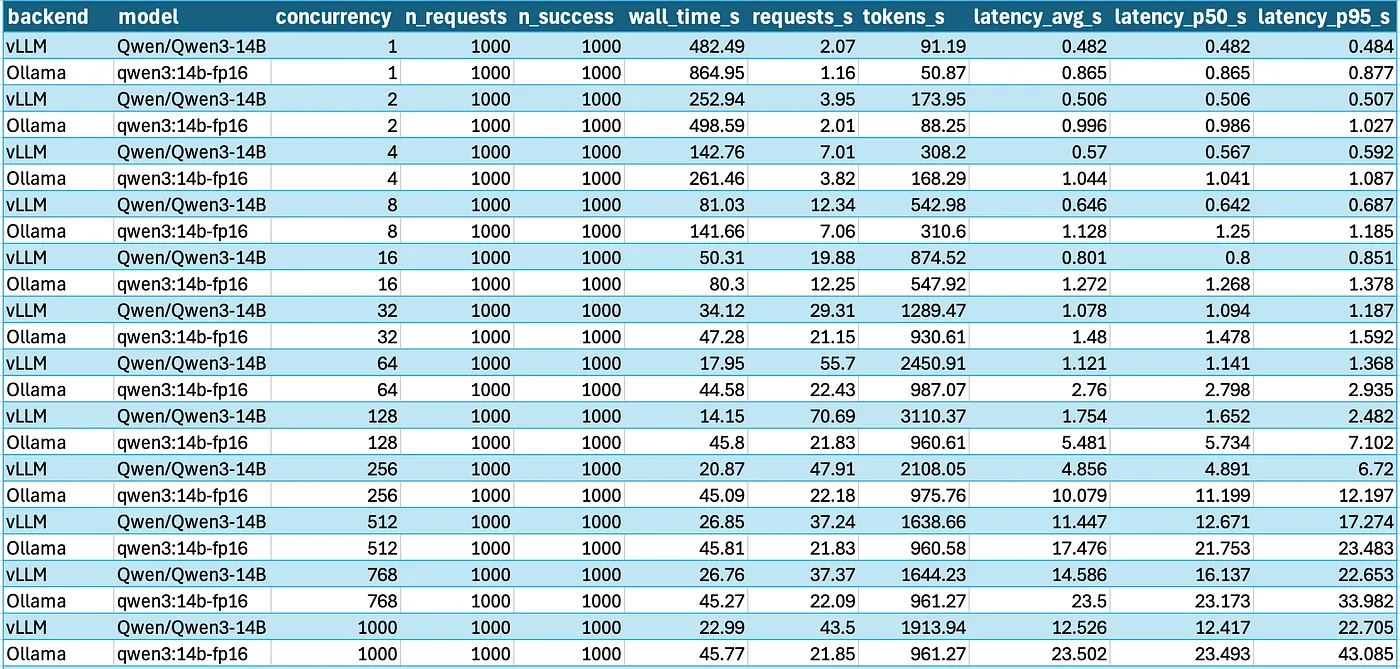
been running llama.cpp and vllm on same 4070, trying to batch more prompts for serving. llama.cpp was lagging bad once I hit batch 8 or so, even though GPU usage looked fine. vllm handled it way better.
later found vllm uses paged kv cache with layout that matches how the GPU wants to read fully coalesced without strided jumps. llama.cpp was using a flat layout that’s fine for single prompt but breaks L2 access patterns when batching.
reshaped kv tensors in llama.cpp to interleave ; made it [head, seq, dim] instead of [seq, head, dim], closer to how vllm feeds data into fused attention kernel. 2x speedup right there w.r.t same ops.
GPU was never the bottleneck. it was memory layout not aligning with SM’s expected access stride. vllm just defaults to layouts that make better use of shared memory and reduce global reads. that’s the real reason it scales better per batch.
this took its own time of say 2+days and had to dig under the nice looking GPU graphs to find real bottlenecks, it was widly trial and error tbf,
> anybody got idea on how to do this kinda experiment in hot reload mode without so much hassle??