Ask HN: Is anyone doing anything cool with tiny language models?
127 comments
·January 21, 2025linsomniac
I have this idea that a tiny LM would be good at canonicalizing entered real estate addresses. We currently buy a data set and software from Experian, but it feels like something an LM might be very good at. There are lots of weirdnesses in address entry that regexes have a hard time with. We know the bulk of addresses a user might be entering, unless it's a totally new property, so we should be able to train it on that.
Evidlo
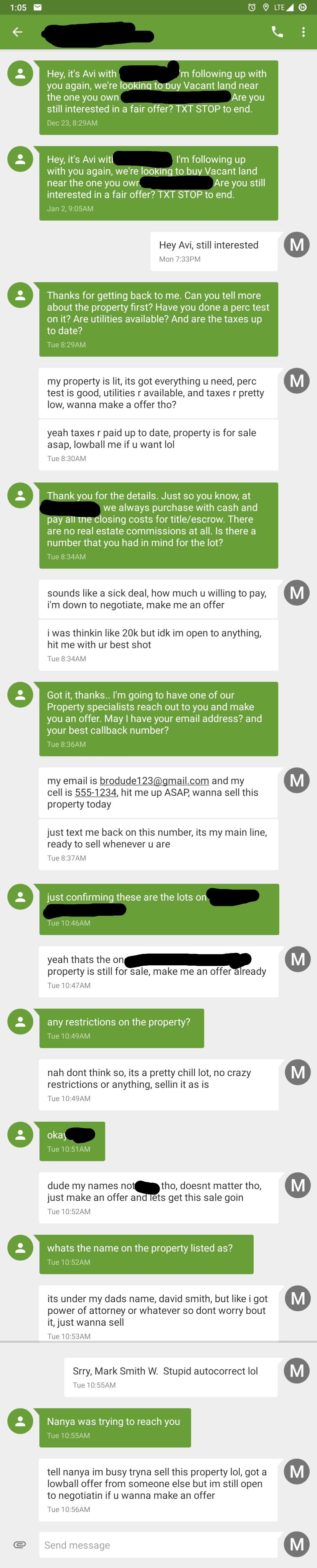
I have ollama responding to SMS spam texts. I told it to feign interest in whatever the spammer is selling/buying. Each number gets its own persona, like a millennial gymbro or 19th century British gentleman.
.png){kind=link}
{kind=link}
celestialcheese
Given the source, I'm skeptical it's not just a troll, but found this explanation [0] plausible as to why those vague spam text exists. If true, this trolling helps the spammers warm those phone numbers up.
stogot
Why does STOP work here?
inerte
Carriers and SMS service providers (like Twillio) obey that, no matter what service is behind.
There are stories of people replying STOP to spam, then never getting a legit SMS because the number was re-used by another service. That's because it's being blocked between the spammer and the phone.
celestialcheese
https://x.com/nikitabier/status/1867069169256308766
Again, no clue if this is true, but it seems plausible.
RVuRnvbM2e
This is fantastic. How have your hooked up a mobile number to the llm?
Evidlo
Android app that forwards to a Python service on remote workstation over MQTT. I can make a Show HN if people are interested.
dkga
Yes, I'd be interested in that!
deadbabe
I’d love to see that. Could you simulate iMessage?
spiritplumber
For something similar with FB chat, I use Selenium and run it on the same box that the llm is running on. Using multiple personalities is really cool though. I should update mine likewise!
zx8080
Cool! Do you consider the risk of unintentional (and until some moment, an unknown) subscription to some paid SMS service and how do you mitigate it?
Evidlo
I have to whitelist a conversation before the LLM can respond.
blackeyeblitzar
You realize this is going to cause carriers to allow the number to send more spam, because it looks like engagement. The best thing to do is to report the offending message to 7726 (SPAM) so the carrier can take action. You can also file complaints at the FTC and FCC websites, but that takes a bit more effort.
thecosmicfrog
Please tell me you have a blog/archive of these somewhere. This was such a joy to read!
antonok
I've been using Llama models to identify cookie notices on websites, for the purpose of adding filter rules to block them in EasyList Cookie. Otherwise, this is normally done by, essentially, manual volunteer reporting.
Most cookie notices turn out to be pretty similar, HTML/CSS-wise, and then you can grab their `innerText` and filter out false positives with a small LLM. I've found the 3B models have decent performance on this task, given enough prompt engineering. They do fall apart slightly around edge cases like less common languages or combined cookie notice + age restriction banners. 7B has a negligible false-positive rate without much extra cost. Either way these things are really fast and it's amazing to see reports streaming in during a crawl with no human effort required.
Code is at https://github.com/brave/cookiemonster. You can see the prompt at https://github.com/brave/cookiemonster/blob/main/src/text-cl....
bazmattaz
This is so cool thanks for sharing. I can imagine it’s not technically possible (yet?) but it would be cool if this could simply be run as a browser extension rather than running a docker container
antonok
I did actually make a rough proof-of-concept of this! One of my long-term visions is to have it running natively in-browser, and able to automatically fix site issues caused by adblocking whenever they happen.
The PoC is a bit outdated but it's here: https://github.com/brave/cookiemonster/tree/webext
binarysneaker
Maybe it could also send automated petitions to the EU to undo cookie consent legislation, and reverse some of the enshitification.
antonok
Ha, I'm not sure the EU is prepared to handle the deluge of petitions that would ensue.
On a more serious note, this must be the first time we can quantitatively measure the impact of cookie consent legislation across the web, so maybe there's something to be explored there.
K0balt
I think there is real potential here, for smart browsing. Have the llm get the page, replace all the ads with kittens, find non-paywall versions if possible and needed, spoof fingerprint data, detect and highlight AI generated drivel, etc. The site would have no way of knowing that it wasn’t touching eyeballs. We might be able to rake back a bit of the web this way.
antonok
You probably wouldn't want to run this in real-time on every site as it'll significantly increase the load on your browser, but as long as it's possible to generate adblock filter rules, the fixes can scale to a pretty large audience.
nozzlegear
I have a small fish script I use to prompt a model to generate three commit messages based off of my current git diff. I'm still playing around with which model comes up with the best messages, but usually I only use it to give me some ideas when my brain isn't working. All the models accomplish that task pretty well.
Here's the script: https://github.com/nozzlegear/dotfiles/blob/master/fish-func...
And for this change [1] it generated these messages:
1. `fix: change from printf to echo for handling git diff input`
2. `refactor: update codeblock syntax in commit message generator`
3. `style: improve readability by adjusting prompt formatting`
behohippy
I have a mini PC with an n100 CPU connected to a small 7" monitor sitting on my desk, under the regular PC. I have llama 3b (q4) generating endless stories in different genres and styles. It's fun to glance over at it and read whatever it's in the middle of making. I gave llama.cpp one CPU core and it generates slow enough to just read at a normal pace, and the CPU fans don't go nuts. Totally not productive or really useful but I like it.
ipython
That's neat. I just tried something similar:
FORTUNE=$(fortune) && echo $FORTUNE && echo "Convert the following output of the Unix `fortune` command into a small screenplay in the style of Shakespeare: \n\n $FORTUNE" | ollama run phi4Uehreka
Do you find that it actually generates varied and diverse stories? Or does it just fall into the same 3 grooves?
Last week I tried to get an LLM (one of the recent Llama models running through Groq, it was 70B I believe) to produce randomly generated prompts in a variety of styles and it kept producing cyberpunk scifi stuff. When I told it to stop doing cyberpunk scifi stuff it went completely to wild west.
coder543
Someone mentioned generating millions of (very short) stories with an LLM a few weeks ago: https://news.ycombinator.com/item?id=42577644
They linked to an interactive explorer that nicely shows the diversity of the dataset, and the HF repo links to the GitHub repo that has the code that generated the stories: https://github.com/lennart-finke/simple_stories_generate
So, it seems there are ways to get varied stories.
o11c
You should not ever expect an LLM to actually do what you want without handholding, and randomness in particular is one of the places it fails badly. This is probably fundamental.
That said, this is also not helped by the fact that all of the default interfaces lack many essential features, so you have to build the interface yourself. Neither "clear the context on every attempt" nor "reuse the context repeatedly" will give good results, but having one context producing just one-line summaries, then fresh contexts expanding each one will do slightly less badly.
(If you actually want the LLM to do something useful, there are many more things that need to be added beyond this)
dotancohen
Sounds to me like you might want to reduce the Top P - that will prevent the really unlikely next tokens from ever being selected, while still providing nice randomness in the remaining next tokens so you continue to get diverse stories.
janalsncm
Generate a list of 5000 possible topics you’d like it to talk about. Randomly pick one and inject that into your prompt.
Dansvidania
this sounds pretty cool, do you have any video/media of it?
droideqa
That's awesome!
keeganpoppen
oh wow that is actually such a brilliant little use case-- really cuts to the core of the real "magic" of ai: that it can just keep running continuously. it never gets tired, and never gets tired of thinking.
bithavoc
this is so cool, any chance you post a video?
flippyhead
I have a tiny device that listens to conversations between two people or more and constantly tries to declare a "winner"
eddd-ddde
I love that there's not even a vague idea of the winner "metric" in your explanation. Like it's just, _the_ winner.
mkaic
This reminds me of the antics of streamer DougDoug, who often uses LLM APIs to live-summarize, analyze, or interact with his (often multi-thousand-strong) Twitch chat. Most recently I saw him do a GeoGuessr stream where he had ChatGPT assume the role of a detective who must comb through the thousands of chat messages for clues about where the chat thinks the location is, then synthesizes the clamor into a final guess. Aside from constantly being trolled by people spamming nothing but "Kyoto, Japan" in chat, it occasionaly demonstrated a pretty effective incarnation of "the wisdom of the crowd" and was strikingly accurate at times.
oa335
This made me actually laugh out loud. Can you share more details on hardware and models used?
jjcm
Are you raising a funding round? I'm bought in. This is hilarious.
nejsjsjsbsb
All computation on device?
econ
This is a product I want
hn8726
What approach/stack would you recommend for listening to an ongoing conversation, transcribing it and passing through llm? I had some use cases in mind but I'm not very familiar with AI frameworks and tools
pseudosavant
I'd love to hear more about the hardware behind this project. I've had concepts for tech requiring a mic on me at all times for various reasons. Always tricky to have enough power in a reasonable DIY form factor.
azhenley
Microsoft published a paper on their FLAME model (60M parameters) for Excel formula repair/completion which outperformed much larger models (>100B parameters).
andai
This is wild. They claim it was trained exclusively on Excel formulas, but then they mention retrieval? Is it understanding the connection between English and formulas? Or am I misunderstanding retrieval in this context?
Edit: No, the retrieval is Formula-Formula, the model (nor I believe tokenizer) does not handle English.
3abiton
But I feel we're going back full circle. These small models are not generalist, thus not really LLMs at least in terms of objective. Recently there has been a rise of "specialized" models that provide lots of values, but that's not why we were sold on LLMs.
Suppafly
Specialized models work much better still for most stuff. Really we need an LLM to understand the input and then hand it off to a specialized model that actually provides good results.
janalsncm
I think playing word games about what really counts as an LLM is a losing battle. It has become a marketing term, mostly. It’s better to have a functionalist point of view of “what can this thing do”.
colechristensen
But that's the thing, I don't need my ML model to be able to write me a sonnet about the history of beets, especially if I want to run it at home for specific tasks like as a programming assistant.
I'm fine with and prefer specialist models in most cases.
zeroCalories
I would love a model that knows SQL really well so I don't need to remember all the small details of the language. Beyond that, I don't see why the transformer architecture can't be applied to any problem that needs to predict sequences.
barrenko
This is really cool. Is this already in Excel?
RhysU
"Comedy Writing With Small Generative Models" by Jamie Brew (Strange Loop 2023)
https://m.youtube.com/watch?v=M2o4f_2L0No
Spend the 45 minutes watching this talk. It is a delight. If you are unsure, wait until the speaker picks up the guitar.
100k
Seconded! This was my favorite talk at Strange Loop (including my own).
simonjgreen
Micro Wake Word is a library and set of on device models for ESPs to wake on a spoken wake word. https://github.com/kahrendt/microWakeWord
Recently deployed in Home Assistants fully local capable Alexa replacement. https://www.home-assistant.io/voice_control/about_wake_word/
jwitthuhn
I've made a tiny ~1m parameter model that can generate random Magic the Gathering cards that is largely based on Karpathy's nanogpt with a few more features added on top.
I don't have a pre-trained model to share but you can make one yourself from the git repo, assuming you have an apple silicon mac.
jftuga
I'm using ollama, llama3.2 3b, and python to shorten news article titles to 10 words or less. I have a 3 column web site with a list of news articles in the middle column. Some of the titles are too long for this format, but the shorter titles appear OK.
mettamage
I simply use it to de-anonymize code that I typed in via Claude
Maybe should write a plugin for it (open source):
1. Put in all your work related questions in the plugin, an LLM will make it as an abstract question for you to preview and send it
2. And then get the answer with all the data back
E.g. df[“cookie_company_name”] becomes df[“a”] and back
sitkack
So you are using a local small model to remove identifying information and make the question generic, which is then sent to a larger model? Is that understanding correct?
I think this would have some additional benefits of not confusing the larger model with facts it doesn't need to know about. My erasing information, you can allow its attention heads to focus on the pieces that matter.
Requires further study.
sauwan
Are you using the model to create a key-value pair to find/replace and then reverse to reanonymize, or are you using its outputs directly? If the latter, is it fast enough and reliable enough?
politelemon
Could you recommend a tiny language model I could try out locally?
mettamage
Llama 3.2 has about 3.2b parameters. I have to admit, I use bigger ones like phi-4 (14.7b) and Llama 3.3 (70.6b) but I think Llama 3.2 could do de-anonimization and anonimization of code
RicoElectrico
Llama 3.2 punches way above its weight. For general "language manipulation" tasks it's good enough - and it can be used on a CPU with acceptable speed.
OxfordOutlander
+1 this idea. I do the same. Just do it locally using ollama, also using 3.2 3b
I mean anything in the 0.5B-3B range that's available on Ollama (for example). Have you built any cool tooling that uses these models as part of your work flow?