AMD claims Arm ISA doesn't offer efficiency advantage over x86
292 comments
·September 8, 2025exmadscientist
torginus
I remember reading this Jim Keller interview:
https://web.archive.org/web/20210622080634/https://www.anand...
Basically the gist of it is that the difference between ARM/x86 mostly boils down to instruction decode, and:
- Most instructions end up being simple load/store/conditional branch etc. on both architectures, where there's literally no difference in encoding efficiency
- Variable length instruction has pretty much been figured out on x86 that it's no longer a bottleneck
Also my personal addendum is that today's Intel efficiency cores are have more transistors and better perf than the big Intel cores of a decade ago
jorvi
Nice followup to your link: https://chipsandcheese.com/p/arm-or-x86-isa-doesnt-matter.
Personally I do not entirely buy it. Intel and AMD have had plenty of years to catch up to Apple's M-architecture and they still aren't able to touch it in efficiency. The PC Snapdragon chips AFAIK also offer better performance-per-watt than AMD or Intel, with laptops offering them often having 10-30% longer battery life at similar performance.
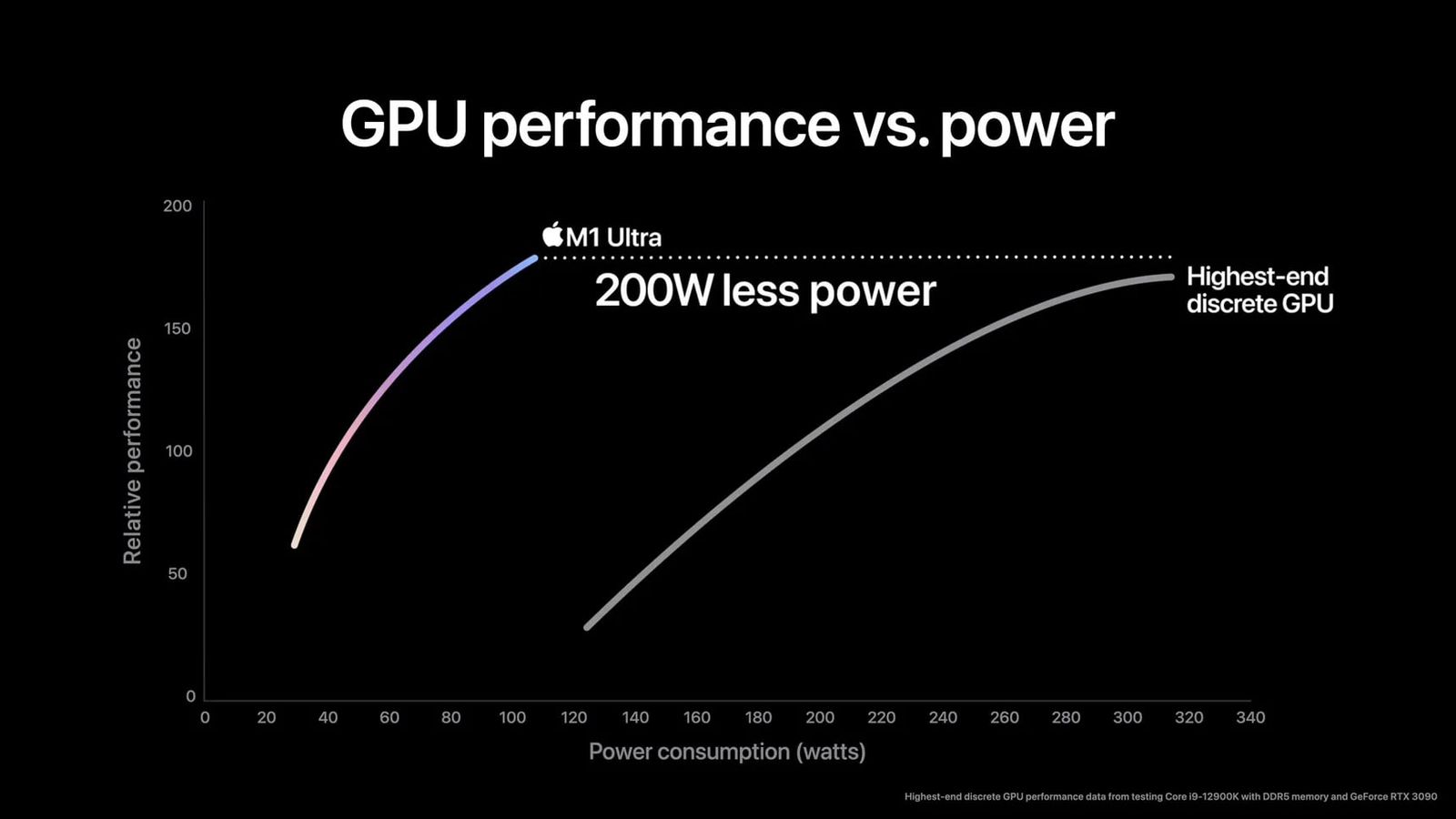
The same goes for GPUs, where Apple's M1 GPU completely smoked an RTX3090 in performance-per-watt, offering 320W of RTX 3090 performance in a 110W envelope: https://images.macrumors.com/t/xuN87vnxzdp_FJWcAwqFhl4IOXs=/...
{kind=link}
ben-schaaf
> Personally I do not entirely buy it. Intel and AMD have had plenty of years to catch up to Apple's M-architecture and they still aren't able to touch it in efficiency. The PC Snapdragon chips AFAIK also offer better performance-per-watt than AMD or Intel, with laptops offering them often having 10-30% longer battery life at similar performance.
Do not conflate battery life with core efficiency. If you want to measure how efficient a CPU core is you do so under full load. The latest AMD under full load uses the same power as M1 and is faster, thus it has better performance per watt. Snapdragon Elite eats 50W under load, significantly worse than AMD. Yet both M1 and Snapdragon beat AMD on battery life tests, because battery life is mainly measured using activities where the CPU is idle the vast majority of the time. And of course the ISA is entirely irrelevant when the CPU isn't being used to begin with.
> The same goes for GPUs, where Apple's M1 GPU completely smoked an RTX3090 in performance-per-watt, offering 320W of RTX 3090 performance in a 110W envelope
That chart is Apple propaganda. In Geekbench 5 the RTX 3090 is 2.5x faster, in blender 3.1 it is 5x faster. See https://9to5mac.com/2022/03/31/m1-ultra-gpu-comparison-with-... and https://techjourneyman.com/blog/m1-ultra-vs-nvidia-rtx-3090/
exmadscientist
Yes, Intel/AMD cannot match Apple in efficiency.
But Apple cannot beat Intel/AMD in single-thread performance. (Apple marketing works very hard to convince people otherwise, but don't fall for it.) Apple gets very, very close, but they just don't get there. (As well, you might say they get close enough for practical matters; that might be true, but it's not the question here.)
That gap, however small it might be for the end user, is absolutely massive on the chip design level. x86 chips are tuned from the doping profiles of the silicon all the way through to their heatsinks to be single-thread fast. That last 1%? 2%? 5%? of performance is expensive, and is far far far past the point of diminishing returns in turns of efficiency cost paid. That last 20% of performance burns 80% of the power. Apple has chosen not to do things this way.
So x86 chips are not particularly well tuned to be efficient. They never have been; it's, on some level, a cultural problem. Could they be? Of course! But then the customers who want what x86 is right now would be sad. There are a lot of customers who like the current models, from hyperscalers to gamers. But they're increasingly bad fits for modern "personal computing", a use case which Apple owns. So why not have two models? When I said "doping profiles of the silicon" above, that wasn't hyperbole, that's literally true. It is a big deal to maintain a max-performance design and a max-efficiency design. They might have the same RTL but everything else will be different. Intel at their peak could have done it (but was too hubristic to try); no one else manufacturing x86 has had the resources. (You'll note that all non-Apple ARM vendor chips are pure efficiency designs, and don't even get close to Apple or Intel/AMD. This is not an accident. They don't have the resources to really optimize for either one of these goals. It is hard to do.)
Thus, the current situation: Apple has a max-efficiency design that's excellent for personal computing. Intel/AMD have aging max-performance designs that do beat Apple at absolute peak... which looks less and less like the right choice with every passing month. Will they continue on that path? Who knows! But many of their customers have historically liked this choice. And everyone else... isn't great at either.
torginus
There are just so many confounding factors that it's almost entirely impossible to pin down what's going on.
- M-series chips have closely integrated RAM right next to the CPU, while AMD makes do with standard DDR5 far away from the CPU, which leads to a huge latency increase
- I wouldn't be surprised if Apple CPUs (which have a mobile legacy) are much more efficient/faster at 'bursty' workloads - waking up, doing some work and going back to sleep
- M series chips are often designed for a lower clock frequency, and power consumption increases quadratically (due to capactive charge/dischargelosses on FETs) Here's a diagram that shows this on a GPU:
So while it's entirely possible that AArch64 is more efficient (the decode HW is simpler most likely, and encoding efficiency seems identical):
https://portal.mozz.us/gemini/arcanesciences.com/gemlog/22-0...?
It's hard to tell how much that contributes to the end result.
diddid
I mean the M1 is nice but pretending that it can do in 110w what the 3090 does with 320w is Apple marketing nonsense. Like if your use case is playing games like cp2077, the 3090 will do 100fps in ultra ray tracing and an M4 Max will only do 30fps. Not to mention it’s trivial to undervolt nvidia cards and get 100% performance at 80% power. So 1/3 the power for 1/3 the performance? How is that smoking anything?
KingOfCoders
Why would they? They are dominated by gaming benchmarks in a way Apple isn't. For decades it was not efficiency but raw performance, 50% more power usage for 10% more performance was ok.
"The same goes for GPUs, where Apple's M1 GPU completely smoked an RTX3090 in performance-per-watt"
Gamers are not interested in performance-per-watt but fps-per-$.
If some behavior looks strange to you, most probably you don't understand the underlying drivers.
michaelmrose
RTX3090 is a desktop part optimized for maximum performance with a high-end desktop power supply. It isn't meaningful to compare its performance per watt with a laptop part.
Saying it offers a certain wattage worth of the desktop part means even less because it measures essentially nothing.
You would probably want to compare it to a mobile 3050 or 4050 although this still risks being a description of the different nodes more so than the actual parts.
codedokode
x86 decoding must be a pain - I vaguely remember that they have trace caches (a cache of decoded micro-operations) to skip decoding in some cases. You probably don't make such caches when decoding is easy.
Also, more complicated decoding and extra caches means longer pipeline, which means more price to pay when a branch is mispredicted (binary search is a festival of branch misprediction for example, and I got 3x acceleration of linear search on small arrays when I switched to the branchless algorithm).
Also I am not a CPU designer, but branch prediction with wide decoder also must be a pain - imagine that while you are loading 16 or 32 bytes from instruction cache, you need to predict the address of next loaded chunk in the same cycle, before you even see what you got from cache.
As for encoding efficiency, I played with little algorithms (like binary search or slab allocator) on godbolt, and RISC-V with compressed instruction generates similar amount of code as x86 - in rare cases, even slightly smaller. So x86 has a complex decoding that doesn't give any noticeable advantages.
x86 also has flags, which add implicit dependencies between instructions, and must make designer's life harder.
wallopinski
I was an instruction fetch unit (IFU) architect on P6 from 1992-1995. And yes, it was a pain, and we had close to 100x the test vectors of all the other units, going back to the mid 1980's. Once we started going bonkers with the prefixes, we just left the pre-Pentium decoder alone and added new functional blocks to handle those. And it wasn't just branch prediction that sucked, like you called out! Filling the instruction cache was a nightmare, keeping track of head and tail markers, coalescing, rebuilding, ... lots of parallel decoding to deal with cache and branch-prediction improvements to meet timing as the P6 core evolved was the typical solution. We were the only block (well, minus IO) that had to deal with legacy compatibility. Fortunately I moved on after the launch of Pentium II and thankfully did not have to deal with Pentium4/Northwood.
jabl
> I vaguely remember that they have trace caches (a cache of decoded micro-operations) to skip decoding in some cases. You probably don't make such caches when decoding is easy.
The P4 microarch had trace caches, but I believe that approach has since been avoided. What practically all contemporary x86 processors do have, though is u-op caches, which contain decoded micro-ops. Note this is not the same as a trace cache.
For that matter, many ARM cores also have u-op caches, so it's not something that is uniquely useful only on x86. The Apple M* cores AFAIU do not have u-op caches, FWIW.
jcranmer
> x86 decoding must be a pain
So one of the projects I've been working on and off again is the World's Worst x86 Decoder, which takes a principled approach to x86 decoding by throwing out most of the manual and instead reverse-engineering semantics based on running the instructions themselves to figure out what they do. It's still far from finished, but I've gotten it to the point that I can spit out decoder rules.
As a result, I feel pretty confident in saying that x86 decoding isn't that insane. For example, here's the bitset for the first two opcode maps on whether or not opcodes have a ModR/M operand: ModRM=1111000011110000111100001111000011110000111100001111000011110000000000000000000000000000000000000011000001010000000000000000000011111111111111110000000000000000000000000000000000000000000000001100111100000000111100001111111100000000000000000000001100000011111100000000010011111111111111110000000011111111000000000000000011111111111111111111111111111111111111111111111111111110000011110000000000000000111111111111111100011100000111111111011110111111111111110000000011111111111111111111111111111111111111111111111
I haven't done a k-map on that, but... you can see that a boolean circuit isn't that complicated. Also, it turns out that this isn't dependent on presence or absence of any prefixes. While I'm not a hardware designer, my gut says that you can probably do x86 instruction length-decoding in one cycle, which means the main limitation on the parallelism in the decoder is how wide you can build those muxes (which, to be fair, does have a cost).
That said, there is one instruction where I want to go back in time and beat up the x86 ISA designers. f6/0, f6/1, f7/0, and f7/1 [1] take in an extra immediate operand whereas f6/2 and et al do not. It's the sole case in the entire ISA where this happens.
[1] My notation for when x86 does its trick of using one of the register selector fields as extra bits for opcodes.
camel-cdr
> trace caches
They don't anymore they have uop caches, but trace caches are great and apple uses them [1].
They allow you to collapse taken branches into a single fetch.
Which is extreamly important, because the average instructions/taken-branch is about 10-15 [2]. With a 10 wide frontend, every second fetch would only be half utilized or worse.
> extra caches
This is one thing I don't understand, why not replace the L1I with the uop-cache entirely?
I quite like what Ventana does with the Veyron V2/V3. [3,4] They replaced the L1I with a macro-op trace cache, which can collapse taken branches, do basic instruction fusion and more advanced fusion for hot code paths.
[1] https://www.realworldtech.com/forum/?threadid=223220
[2] https://lists.riscv.org/g/tech-profiles/attachment/353/0/RIS... (page 10)
monocasa
> x86 decoding must be a pain - I vaguely remember that they have trace caches (a cache of decoded micro-operations) to skip decoding in some cases. You probably don't make such caches when decoding is easy.
To be fair, a lot of modern ARM cores also have uop caches. There's a lot to decide even without the variable length component, to the point that keeping a cache of uops and temporarily turning pieces of the IFU off can be a win.
eigenform
> [...] imagine that while you are loading 16 or 32 bytes from instruction cache, you need to predict the address of next loaded chunk in the same cycle, before you even see what you got from cache.
Yeah, you [ideally] want to predict the existence of taken branches or jumps in a cache line! Otherwise you have cycles where you're inserting bubbles into the pipeline (if you aren't correctly predicting that the next-fetched line is just the next sequential one ..)
phire
Intel’s E cores decode x86 without a trace cache (μop cache), and are very efficient. The latest (Skymont) can decode 9 x86 instructions per cycle, more than the P core (which can only decode 8)
AMD isn’t saying that decoding x86 is easy. They are just saying that decoding x86 doesn’t have a notable power impact.
ahartmetz
Variable length decoding is more or less figured out, but it takes more design effort, transistors and energy. They cost, but not a lot, relatively, in a current state of the art super wide out-of-order CPU.
wallopinski
"Transistors are free."
That was pretty much the uArch/design mantra at intel.
rasz
Not a lot is not how I would describe it. Take a 64bit piece of fetched data. On ARM64 you will just push that into two decoder blocks and be done with it. On x86 you got what, 1 to 15 bytes range per instruction? I dont even want to think about possible permutations, its in the 10 ^ some two digit number order.
IshKebab
Yeah I'm not sure I buy it either.
It doesn't matter if most instructions have simple encodings. You still need to design your front end to handle the crazy encodings.
I doubt it makes a big difference, so until recently he would have been correct - why change your ISA when you can just wait a couple of months to get the same performance improvement. But Moore's law is dead now so small performance differences matter way more now.
topspin
I've listened Keller's views on CPU design and the biggest takeaway I found is that performance is overwhelmingly dominated by predictors. Good predictors mitigate memory latency and keep pipelines full. Bad predictors stall everything while cores spin on useless cache lines. The rest, including ISA minutiae, rank well below predictors on the list of things that matter.
At one time, ISA had a significant impact on predictors: variable length instructions complicated predictor design. The consensus is that this is no longer the case: decoders have grown to overcome this and now the difference is negligible.
fanf2
Apple’s ARM cores have wider decode than x86
M1 - 8 wide
M4 - 10 wide
Zen 4 - 4 wide
Zen 5 - 8 wide
adgjlsfhk1
pure decoder width isn't enough to tell you everything. X86 has some commonly used ridiculously compact instructions (e.g. lea) that would turn into 2-3 instructions on most other architectures.
ryuuchin
Is Zen 5 more like a 4x2 than a true 8 since it has dual decode clusters and one thread on a core can't use more than one?
wmf
Skymont - 9 wide
mort96
Wow, I had no idea we were up to 8 wide decoders in amd64 CPUs.
AnotherGoodName
For variable vs fixed width i have heard that fixed width is part of apple silicons performance. There’s literally gains to be had here for sure imho.
astrange
It's easier but it's not that important. It's more important for security - you can reinterpret variable length instructions by jumping inside them.
mort96
This matches my understanding as well, as someone who has a great deal of interest in the field but never worked in it professionally. CPUs all have a microarchitecture that doesn't look like the ISA at all, and they have an instruction decoder that translates ISA one or more ISA instructions into zero or more microarchitectural instructions. There are some advantages to having a more regular ISA, such as the ability to more easily decode multiple instructions in parallel if they're all the same size or having to spend fewer transistors on the instruction decoder, but for the big superscalar chips we all have in our desktops and laptops and phones, the drawbacks are tiny.
I imagine that the difference is much greater for the tiny in-order CPUs we find in MCUs though, just because an amd64 decoder would be a comparatively much larger fraction of the transistor budget
themafia
Then there's mainframes. Where you want code compiled in 1960 to run unmodified today. There was quite of original advantage as well as IBM was able to implement the same ISA with three different types and costs of computers.
astrange
uOps are kind of oversold in the CPU design mythos. They are not that different from the original ISA, and some x86 instructions (like lea) are both complex and natural fits for hardware so don't get microcoded.
newpavlov
>RISC-V is a new-school hyper-academic hot mess.
Yeah... Previously I was a big fan of RISC-V, but after I had to dig slightly deeper into it as a software developer my enthusiasm for it has cooled down significantly.
It's still great that we got a mainstream open ISA, but now I view it as a Linux of the hardware world, i.e. a great achievement, with a big number of questionable choices baked in, which unfortunately stifles other open alternatives by the virtue of being "good enough".
chithanh
> which unfortunately stifles other open alternatives by the virtue of being "good enough".
In China at least, the hardware companies are smart enough to not put all eggs in the RISC-V basket, and are pursuing other open/non-encumbered ISAs.
They have LoongArch which is a post-MIPS architecture with elements from RISC-V. Also they have ShenWei/SunWay which is post-Alpha.
And they of course have Phytium (ARM), HeXin (OpenPower), and Zhaoxin (x86).
codedokode
What choices? The main thing that comes to mind is lack of exceptions on integer overflow but you are unlikely meaning this.
newpavlov
- Handling of misaligned loads/stores: RISC-V got itself into a weird middle ground, ops on misaligned pointers may work fine, may work "extremely slow", or cause fatal exceptions (yes, I know about Zicclsm, it's extremely new and only helps with the latter, also see https://github.com/llvm/llvm-project/issues/110454). Other platforms either guarantee "reasonable" performance for such operations, or forbid misaligned access with "aligned" loads/stores and provide separate misaligned instructions. Arguably, RISC-V should've done the latter (with misaligned instructions defined in a separate higher-end extension), since passing unaligned pointer into an aligned instruction signals correctness problems in software.
- The hardcoded page size. 4 KiB is a good default for RV32, but arguably a huge missed opportunity for RV64.
- The weird restriction in the forward progress guarantees for LR/SC sequences, which forces compilers to compile `compare_exchange` and `compare_exchange_weak` in the absolutely same way. See this issue for more information: https://github.com/riscv/riscv-isa-manual/issues/2047
- The `seed` CSR: it does not provide a good quality entropy (i.e. after you accumulated 256 bits of output, it may contain only 128 bits of randomness). You have to use a CSPRNG on top of it for any sensitive applications. Doing so may be inefficient and will bloat binary size (remember, the relaxed requirement was introduced for "low-powered" devices). Also, software developers may make mistake in this area (not everyone is a security expert). Similar alternatives like RDRAND (x86) and RNDR (ARM) guarantee proper randomness and we can use their output directly for cryptographic keys with very small code footprint.
- Extensions do not form hierarchies: it looks like the AVX-512 situation once again, but worse. Profiles help, but it's not a hierarchy, but a "packet". Also, there are annoyances like Zbkb not being a proper subset of Zbb.
- Detection of available extensions: we usually have to rely on OS to query available extensions since the `misa` register is accessible only in machine mode. This makes detection quite annoying for "universal" libraries which intend to support various OSes and embedded targets. The CPUID instruction (x86) is ideal in this regard. I totally disagree with the virtualization argument against it, nothing prevents VM from intercepting the read, no one excepts huge performance from such reads.
And this list is compiled after a pretty surface-level dive into the RISC-V spec. I heard about other issues (e.g. being unable to port tricky SIMD code to the V extension or underspecification around memory coherence important for writing drivers), but I can not confidently talk about those, so it's not part of my list.
P.S.: I would be interested to hear about other people gripes with RISC-V.
whynotminot
An annoying thing people have done since Apple Silicon is claim that its advantages were due to Arm.
No, not really. The advantage is Apple prioritizing efficiency, something Intel never cared enough about.
choilive
In most cases, efficiency and performance are pretty synonymous for CPUs. The faster you can get work done (and turn off the silicon, which is admittedly a higher design priority for mobile CPUs) the more efficient you are.
The level of talent Apple has cannot be understated, they have some true CPU design wizards. This level of efficiency cannot be achieved without making every aspect of the CPU as fast as possible; their implementation of the ARM ISA is incredible. Lots of companies make ARM chips, but none of them are Apple level performance.
As a gross simplification, where the energy/performance tradeoff actually happens is after the design is basically baked. You crank up the voltage and clock speed to get more perf at the cost of efficiency.
toast0
> In most cases, efficiency and performance are pretty synonymous for CPUs. The faster you can get work done (and turn off the silicon, which is admittedly a higher design priority for mobile CPUs) the more efficient you are.
Somewhat yes, hurry up and wait can be more efficient than running slow the whole time. But at the top end of Intel/AMD performance, you pay a lot of watts to get a little performance. Apple doesn't offer that on their processors, and when they were using Intel processors, they didn't provide thermal support to run in that mode for very long either.
The M series bakes in a lower clockspeed cap than contemperary intel/amd chips; you can't run in the clock regime where you spend a lot of watts and get a little bit more performance.
cheema33
> The advantage is Apple prioritizing efficiency, something Intel never cared enough about.
Intel cared plenty once they realized that they were completely missing out on the mobile phone business. They even made X86/Atom chips for the phone market. Asus for example had some phones (Zenfone) with Intel X86 chips in them in the mid-2010s. However, Intel Atom suffered from poor power efficiency and battery life and soon died.
wvenable
By prioritizing efficiency, Apple also prioritizes integration. The PC ecosystem prefers less integration (separate RAM, GPU, OS, etc) even at the cost of efficiency.
AnthonyMouse
> By prioritizing efficiency, Apple also prioritizes integration. The PC ecosystem prefers less integration (separate RAM, GPU, OS, etc) even at the cost of efficiency.
People always say this but "integration" has almost nothing to do with it.
How do you lower the power consumption of your wireless radio? You have a network stack that queues non-latency sensitive transmissions to minimize radio wake-ups. But that's true for radios in general, not something that requires integration with any particular wireless chip.
How do you lower the power consumption of your CPU? Remediate poorly written code that unnecessarily keeps the CPU in a high power state. Again not something that depends on a specific CPU.
How much power is saved by soldering the memory or CPU instead of using a socket? A negligible amount if any; the socket itself has no significant power draw.
What Apple does well isn't integration, it's choosing (or designing) components that are each independently power efficient, so that then the entire device is. Which you can perfectly well do in a market of fungible components simply by choosing the ones with high efficiency.
In fact, a major problem in the Android and PC laptop market is that the devices are insufficiently fungible. You find a laptop you like where all the components are efficient except that it uses an Intel processor instead of the more efficient ones from AMD, but those components are all soldered to a system board that only takes Intel processors. Another model has the AMD APU but the OEM there chose poorly for the screen.
It's a mess not because the integration is poor but because the integration exists instead of allowing you to easily swap out the part you don't like for a better one.
happycube
There's a critical instruction for Objective C handling (I forget exactly what it is) but it's faster than intel's chips even in Rosetta 2's x86 emulation.
Panzer04
Eh, probably the biggest difference is in the OS. The amount of time Linux or Windows will spend using a processor while completely idle can be a bit offensive.
MindSpunk
Apple also buys out basically all of TSMC's initial capacity for their leading edge node so generally every time a new Apple Silicon thing comes out it's a process node ahead of every other chip they're comparing to.
steve1977
Also Apple has a ton of cash that it can give to TSMC to essentially get exclusive access to the latest manufacturing process.
JumpCrisscross
> Apple has a ton of cash that it can give to TSMC to essentially get exclusive access to the latest manufacturing process
How have non-Apple chips on TSMC’s 5nm process compared with Apple’s M series?
tliltocatl
Nitpick: uncore and the fabrication details dominate the ISA on high end/superscalar architectures (because modern superscalar basically abstract the ISA away at the frontend). On smaller (i. e. MCU) cores x86 will never stand any chance.
bpye
Not that it stopped Intel trying - https://en.m.wikipedia.org/wiki/Intel_Quark
somanyphotons
I'd love to see what would happen if AMD put out a chip with the instruction decoders swapped out for risc-v instruction decoders
AnotherGoodName
Fwiw the https://en.wikipedia.org/wiki/AMD_Am29000 RISC CPU and the https://en.wikipedia.org/wiki/AMD_K5 are a good example of this. As in AMD took their existing RISC CPU to make the K5 x86 CPU.
Almost the same in die shots except the K5 had more transistors for the x86 decoding. The AM29000's instruction set is actually very close to RISC-V too!
Very hard to find benchmarks comparing the two directly though.
throwawaymaths
TIL the k5 was RISC. thank you
guerrilla
Indeed. We don't need it, but I want it for perfectionist aesthetic completion.
wlesieutre
VIA used to make low power x86 processors
yndoendo
Fun fact. The idea of strong national security is the reason why there are three companies with access to the x86 ISA.
DoD originally required all products to be sourced by at least three companies to prevent supply chain issues. This required Intel to allow AMD and VIA to produce products based on ISA.
For me this is good indicator if someone that talks about good national security knows what they are talking about or are just spewing bullshit and playing national security theatre.
rasz
Intel didnt "allow" VIA anything :). Via acquired x86 tech from IDT (WinChip Centaur garbage) in a fire sale. IDT didnt ask anyone about any licenses, neither did Cyrix, NextGen, Transmeta, Rise nor NEC.
Afaik DoD wasnt the reason behind original AMD second source license, it was IBM forcing Intel on chips that went into first PC.
pavlov
And Transmeta…
DeepYogurt
Transmeta wasn't x86 internally but decoded x86 instructions. Retrobytes did a history of transmeta not too long ago and the idea was essentially to be able to be compatible with any cpu uarch. Alas by the time it shipped only x86 was relevant. https://www.youtube.com/watch?v=U2aQTJDJwd8
epolanski
I have a hard time believing this fully: more custom instructions, more custom hardware, more heat.
How can you avoid it?
tapoxi
Since the Pentium Pro the hardware hasn't implemented the ISA, it's converted into micro ops.
epolanski
Come on, you know what I meant :)
If you want to support AVX e.g. you need 512bit (or 256) wide registers, you need dedicated ALUs, dedicated mask registers etc.
Ice Lake has implemented SHA-specific hardware units in 2019.
CyberDildonics
The computation has to be done somehow, I don't know that it is a given that more available instructions means more heat.
pezezin
After playing around with some ARM hardware I have to say that I don't care whether ARM is more efficient or not as long as the boot process remains the clusterfuck that it is today.
IMHO the major win of the IBM PC platform is that it standardized the boot process from the very beginning, first with the BIOS and later with UEFI, so you can grab any random ISO for any random OS and it will work. Meanwhile in the ARM world it seems that every single CPU board requires its own drivers, device tree, and custom OS build. RISC-V seems to suffer from the same problem, and until this problem is solved, I will avoid them like toxic waste.
Teknoman117
ARM systems that support UEFI are pretty fun to work with. Then there's everything else. Anytime I hear the phrase "vendor kernel" I know I'm in for an experience...
mrheosuper
Fun Fact: Your Qualcomm based Phone may already use UEFI.
nicman23
nah when i hear vendor kernel i just do not go for that experience. it is not 2006 get your shit mainline or at least packaged correctly.
markfeathers
Check out ARM SBSA / SBBR which seems aimed at solving most of these issues. https://en.wikipedia.org/wiki/Server_Base_System_Architectur... I'm hopeful RISCV comes up with something similar.
Joel_Mckay
In general, most modern ARM 8/9 64bit SoC purged a lot of the vestigial problems.
Yet most pre-compiled package builds still never enable the advanced ASIC features for compatibility and safety-concerns. AMD comparing the NERF'd ARM core features is pretty sleazy PR.
Tegra could be a budget Apple M3 Pro, but those folks chose imaginary "AI" money over awesomeness. =3
nicman23
nah. if they do not work on their extensions to be supported by general software, that is their problem
txrx0000
It's not the ISA. Modern Macbooks are power-efficient because they have:
- RAM on package
- PMIC power delivery
- Better power management by OS
Geekerwan investigated this a while ago, see:
https://www.youtube.com/watch?v=Z0tNtMwYrGA https://www.youtube.com/watch?v=b3FTtvPcc2s https://www.youtube.com/watch?v=ymoiWv9BF7Q
Intel and AMD have implemented these improvements with Lunar Lake and Strix Halo. You can buy an x86 laptop with Macbook-like efficiency right now if you know which SoCs to pick.
edit: Correction. I looked at the die image of Strix Halo and thought it looked like it had on-package RAM. It does not. It doesn't use PMIC either. Lunar Lake is the only Apple M-series competitor on x86 at the moment.
aurareturn
Intel and AMD have implemented these improvements with Lunar Lake and Strix Halo. You can buy an x86 laptop with Macbook-like efficiency right now if you know which SoCs to pick.
jlei523
Intel and AMD have implemented these improvements with Lunar Lake and Strix Halo. You can buy an x86 laptop with Macbook-like efficiency right now if you know which SoCs to pick.
Strix Halo battery life and efficiency is not even in the same ball park.
mrheosuper
By PMIC, did you mean VRM ?, if not, can you tell me the difference between them ?
txrx0000
I'm not an expert on the topic and don't really know the difference. But in the video they say it can finetune power delivery to individual parts of the SoC and reduce idle power.
mrheosuper
Well, Every single CPU need some kind of voltage regulation module to work.
About "fine tune" part, this does not relate to PMIC(or VRM) at all, more like CPU design: How many power domain does this CPU have ?
KingOfCoders
"When RISC first came out, x86 was half microcode. So if you look at the die, half the chip is a ROM, or maybe a third or something. And the RISC guys could say that there is no ROM on a RISC chip, so we get more performance. But now the ROM is so small, you can’t find it. Actually, the adder is so small, you can hardly find it? What limits computer performance today is predictability, and the two big ones are instruction/branch predictability, and data locality."
Jim Keller
SOTGO
I'd be interested to hear someone with more experience talk about this or if there's more recent research, but in school I read this paper: <https://research.cs.wisc.edu/vertical/papers/2013/hpca13-isa...> that seems to agree that x86 and ARM as instruction sets do not differ greatly in power consumption. They also found that GCC picks RISC-like instructions when compiling for x86 which meant the number of micro-ops was similar between ARM and x86, and that the x86 chips were optimized well for those RISC-like instructions and so were similarly efficient to ARM chips. They have a quote that "The microarchitecture, not the ISA, is responsible for performance differences."
tester756
Of course, because saying that X ISA is faster than Y ISA is like saying that Java syntax is faster than C# syntax
Everything is about the implementation: compiler, JIT, runtime/VM, stdlib, etc.
rafaelmn
C# syntax is faster than Java because Java has no way to define custom value types/structs (last time I checked, I know there was some experimental work on this)
tester756
and yet there's more Java in HFT than C#
And don't get me wrong, I'm C# fanboi that'd never touch Java, but JVM itself is impressive as hell,
so even despite not having (yet) value types/structs, Java is still very strong due to JVM (the implementation). Valhalla should push it even further.
cjbgkagh
HFT code is unusual in the way it is used. A lot of work goes into avoiding the Garbage Collection and other JVM overheads.
null
slimginz
IIRC There was a Jim Keller interview a few years ago where he said basically the same thing (I think it was from right around when he joined Tenstorrent?). The ISA itself doesn't matter, it's just instructions. The way the chip interprets those instructions is what makes the difference. ARM was designed from the beginning for low powered devices whereas x86 wasn't. If x86 is gonna compete with ARM (and RISC-V) then the chips are gonna need to also be optimized for low powered devices, but that can break decades of compatibility with older software.
sapiogram
It's probably from the Lex Friendman podcast he did. And to be fair, he didn't say "it doesn't matter", he said "it's not that important".
nottorp
Irrelevant.
There are two entities allowed to make x86_64 chips (and that only because AMD won the 64 bit ISA competition, otherwise there'd be only Intel). They get to choose.
The rest will use arm because that's all they have access to.
Oh, and x86_64 will be as power efficient as arm when one of the two entities will stop competing on having larger numbers and actually worry about power management. Maybe provide a ?linux? optimized for power consumption.
Dylan16807
Unless you badly need SSE4 or AVX (and can't get around the somewhat questionable patent situation) anyone can make an x86_64 chip. And those patents are running out soon.
ac29
> Oh, and x86_64 will be as power efficient as arm when one of the two entities will stop competing on having larger numbers and actually worry about power management.
Both Intel and AMD provide runtime power control so this is tunable. The last ~10% of performance requires far more than 10% of the power.
MBCook
I remember hearing on one of the podcasts I listened to about the difference between the Apple power cores and efficiency cores.
The power ones have more execution units I think, and are allowed to run faster.
When running the same task, the efficiency ones are just ridiculously more efficient. I wish I had some link to cite.
The extra speed the power units are allowed is enough to tip them way over the line of exponential power usage. I’ve always known each bump in megahertz comes with a big power cost but it was eye-opening.
shmerl
AMD do handle power consumption well, at least if you run in eco mode instead of pushing CPU to the limits. I always set eco mode on on modern Ryzens.
nottorp
I have a Ryzen box that I temperature limited to 65 C indeed. That was about 100 W in my office with just the graphics integrated into the Ryzen.
However, next to it there's a M2 mac mini that uses all of 37 W when I'm playing Cyberpunk 2077 so...
> Both Intel and AMD provide runtime power control so this is tunable. The last ~10% of performance requires far more than 10% of the power.
Yes but the defaults are insane.
dotnet00
If you're measuring the draw at the wall, AFAIK desktop Ryzen keeps the chipset running at full power all the time and so even if the CPU is idle, it's hard to drop below, say, ~70W at the wall (including peripherals, fans, PSU efficiency etc).
Apparently desktop Intel is able to drop all the way down to under 10W on idle.
Teknoman117
The last 20% of the performance takes like >75% of the power with Zen 4 systems XD.
A Ryzen 9 7945HX mini pc I have achieves like ~80% of the all-core performance at 55W of my Ryzen 9 7950X desktop, which uses 225W for the CPU (admittedly, the defaults).
I think limiting the desktop CPU to 105W only dropped the performance by 10%. I haven't done that test in awhile because I was having some stability problems I couldn't be bothered to diagnose.
bigyabai
Sounds like your M2 is hitting the TDP max and the Ryzen box isn't.
Keep in mind there are Nvidia-designed chips (eg. Switch 2) that use all of ten watts when playing Cyberpunk 2077. Manufactured on Samsung's 8nm node, no less. It's a bit of a pre-beaten horse, but people aren't joking when they say Apple's GPU and CPU designs leave a lot of efficiency on the table.
shmerl
Cyberpunk 2077 is very GPU bound, so it's not really about CPU there. I'm playing it using 7900 XTX on Linux :)
But yeah, defaults are set to look better in benchmarks and they are not worth it. Eco mode should be the default.
rickdeckard
I agree, but I also don't think that the ISA is the differentiation factor for real-life efficiency between those two architectures.
ARMs advantage is that every user-facing OS built for ARM was designed to be power-efficient, with frameworks governing applications.
x86, not so much...
variadix
Instruction decode for variable length ISAs is inherently going to be more complex, and thus require more transistors = more power, than fixed length instruction decode, especially parallel decode. AFAIK modern x86 cores have to speculatively decode instructions to achieve this, compared to RISC ISAs where you know where all the instruction boundaries are and decoding N in parallel is a matter of instantiating N decoders that work in parallel. How much this determines the x86 vs ARM power gap, I don’t know, what’s much more likely is x86 designs have not been hyper optimized for power as much ARM designs have been over the last two decades. Memory order is another non-negligible factor, but again the difference is probably more attributable to the difference in goals between the two architectures for the vast majority of their lifespan, and the expertise and knowledge of the engineers working at each company.
Avi-D-coder
From what I have heard it's not the RISCy ISA per se, it's largely arm's weaker memory model.
I'd be happy to be corrected, but the empirical core counts seem to agree.
hydroreadsstuff
Indeed, the memory model has a decent impact. Unfortunately it's difficult to isolate in measurement. Only Apple has support for weak memory order and TSO in the same hardware.
MBCook
Oh there’s an interesting idea. Given that Linux runs on the M1 and M2 Macs, would it be possible to do some kind of benchmark there where you could turn it on and off at will for your test program?
gok
This has been done in fact: https://doi.org/10.1016/j.sysarc.2024.103102
hereme888
I was just window-shopping laptops this morning, and realized ARM-based doesn't necessarily hold battery life advantages.
pacetherace
Plus they are not cheap either.
mrheosuper
I Blame that on Qualcomm. Right now they are the only vendor with ARM CPU on Windows. And using QC CPU means you must buy their whole "solution".
This is an entirely uncontroversial take among experts in the space. x86 is an old CISC-y hot mess. RISC-V is a new-school hyper-academic hot mess. Recent ARM is actually pretty good. And none of it matters, because the uncore and the fabrication details (in particular, whether things have been tuned to run full speed demon or full power sipper) completely dominate the ISA.
In the past x86 didn't dominate in low power because Intel had the resources to care but never did, and AMD never had the resources to try. Other companies stepped in to full that niche, and had to use other ISAs. (If they could have used x86 legally, they might well have done so. Oops?) That may well be changing. Or perhaps AMD will let x86 fade away.