Embeddings are underrated (2024)
154 comments
·May 12, 2025kaycebasques
theletterf
Perhaps you should make the post more appealing to tech writers and less to ML experts. That would help increase the reach for the intended target audience. For example, you can expand on "the ability to discover connections between texts at previously impossible scales". There's an applications section, but it's easy to overlook. Frontload value for tech writers with examples.
kaycebasques
Yes, definitely need to follow through on the follow-up posts and projects that show exactly how we apply embeddings to TW. Examples (in all their forms) are truly magical in how effective they are as a teaching aid.
sgbeal
> I know that the post is light on details regarding how exactly we apply embeddings in TW.
More significantly, after having read the first 6 or 8 paragraphs, i still have no clue what an "embedding" is. From the 3rd paragraph:
> Here’s an overview of how you use embeddings and how they work.
But no mention of what they are (unless perhaps it's buried far deeper in the article).
kaycebasques
I was worried that introducing the formal concept too quickly would feel a bit overwhelming for my fellow technical writers who are learning about embeddings for the first time, but I know that it's also annoying when a post makes you wait too long to get an answer to a question. So I'll find a way to provide a quick answer upfront. Thanks for the feedback.
kadushka
A word embedding is a representation of a word using many numbers, where each numbers represents some property of the word. Usually we do not know what those properties are because the numbers are learned by a model during processing of a large number of texts.
_bramses
> Discoveryness. Even if the needed content exists, it’s hard to guarantee that users will find it.
I'm curious as to what you'll think of the UX layer I applied to embeddings for public perusal. I call it "semantic scrolling" since it's not searching exactly, but moving through the cluster by using <summary>/<details> as a tree.
[1] is a single starting point (press the animated arrow to "wiki-hole") and [2] is the entire collection (books, movies, music, animations, etc.)
[1] - https://www.sharecommonbase.com/synthesize/1009?id=1009 [2] - https://www.sharecommonbase.com/
kaycebasques
Cool. I kinda grok the idea of semantic scrolling but I'm having trouble seeing it in action in the site. I think it would be useful in cases where I want to become an expert in a given topic and therefore I want to peruse lots of related ideas and create the possibility of serendipitous new neural connections. As for technical documentation, usually people want to find certain information as quickly as possible so that they can get on with their work, so I don't think semantic scrolling would be a good fit on most docs sites. I.e. they won't have the patience to semantically scroll in order to find the info they need.
luckydata
a small nit: while I understand this is an introductory article, I think it's a bit TOO introductory. You should at least give a preview of a "killer app" of embeddings to make me want to read the next installments, I read the entire article and I'm not sure I learned anything useful or insightful that I didn't know before. I feel you held back too much, but thanks for sharing that's appreciated.
kaycebasques
Yes, as a standalone post I can totally see how this is not persuasive because it's too vague and doesn't spell out specific applications. My only excuse is that I never intended this to be a standalone post; it was intended to be a conceptual primer supplemented by follow-up posts and projects exploring different applications of embeddings in technical writing. Hopefully the renewed attention on this post will motivate me to follow through on the follow-up content ;)
kaycebasques
Also, re: direct applications of embeddings in technical writing, see https://www.tdcommons.org/dpubs_series/8057/
rybosome
Thanks for the write-up!
I’m curious how you found the quality of the results? This gets into evals which ML folks love, but even just with “vibes” do the results eyeball as reasonable to you?
kaycebasques
By results I assume that you're asking about the related pages experiment? The results were definitely promising. A lot of the calculated related pages were totally reasonable. E.g. if I'm reading https://www.sphinx-doc.org/en/master/development/html_themes... then it's very reasonable to assume that I may also be interested in https://www.sphinx-doc.org/en/master/usage/theming.html
jasonjmcghee
Another very cool attribute of embeddings and embedding search is that they are resource cheap enough that you can perform them client side.
ONNX models can be loaded and executed with transformer.js https://github.com/huggingface/transformers.js/
You can even build and statically host indices like hnsw for embeddings.
I put together a little open source demo for this here https://jasonjmcghee.github.io/portable-hnsw/ (it's a prototype / hacked together approximation of hnsw, but you could implement the real thing)
Long story short, represent indices as queryable parquet files and use duckdb to query them.
Depending on how you host, it's either free or nearly free. I used Github Pages so it's free. R2 with cloudflare would only cost the size what you store (very cheap- no egress fees).
kaycebasques
Oh cool, client-side JS-powered embeddings were not on my radar. That opens up a lot of applications for docs sites. Thanks for sharing.
Parquet and Polars are definitely on my radar, though, after reading this: https://minimaxir.com/2025/02/embeddings-parquet/
jasonjmcghee
Great article!
qq99
I was wondering about this. I was hesitant to add embedding-based search to my app because I didn't want to incur the latency to the embedding API provider blocking every search on initial render. Granted, you can cache the embeddings for common searches. OTOH, I also don't want to render something without them, perform the embedding async, and then have to reify the results list once the embedding arrives. Seems hard to sensibly do that from a UX perspective.
To render locally, you need access to the model right? I just wonder how good those embeddings will be compared to those from OpenAI/Google/etc in terms of semantic search. I do like the free/instant aspect though
jasonjmcghee
checkout MTEB (https://huggingface.co/spaces/mteb/leaderboard) many of the open source ones are actually _better_.
I've had a particularly good experiences with nomic, bge, gte, and all-MiniLM-L6-v2. All are hundreds of MB (except all-minilm which is like 87MB)
simonw
I love all-MiniLM-L6-v2 - 87MB is tiny enough that you could just load it into RAM in a web application process on a small VM. From my experiments with it the results are Good Enough for a lot of purposes. https://simonwillison.net/2023/Sep/4/llm-embeddings/#embeddi...
rrr_oh_man
Can you elaborate what is happening? The results don't really make sense to me.
jasonjmcghee
You should be able to search for vibes and get text with similar vibes.
Try like "I'm scared" or "running fast" - whatever you want, and the results will be of passages that are semantically similar.
---
It's an embedding search using heirarchical navigable small worlds.
I chunked up a few corpora of text (books, blogs, etc) and embedded them and indexed them.
But the indexing strategy split things into a nodes parquet file and an edges parquet file, so that they could be served from a cdn and searched client side. (No running vector database)
ubj
> Because we always get back the same amount of numbers no matter how big or small the input text, we now have a way to mathematically compare any two pieces of arbitrary text to each other.
I think there needs to be some more clarification here. Hash functions also return the same sized output no matter how big or small the input text. However, mathematically comparing two hashes is going to have a much different meaning than mathematically comparing two embeddings.
I'd recommend emphasizing that embeddings are training dependent--the quality of comparison will depend on the quality and type of training used to produce the embedding. There isn't some single "universal embedding" that allows for meaningful comparison of arbitrary text.
kaycebasques
Thanks for the feedback. I've been reading the research papers behind how these models are created e.g. Gecko [1] and NV-Embed [2] and Gemini Embedding [3] so I'm starting to grok what you're getting at and will find a way to make the post more accurate on this front
[1] https://arxiv.org/abs/2403.20327
jas8425
If embeddings are roughly the equivalent of a hash at least insofar as they transform a large input into some kind of "content-addressed distillation" (ignoring the major difference that a hash is opaque whereas an embedding has intrinsic meaning), has there been any research done on "cracking" them? That is, starting from an embedding and working backwards to generate a piece of text that is semantically close by?
I could imagine an LLM inference pipeline where the next token ranking includes its similarity to the target embedding, or perhaps instead the change in direction towards/away from the desired embedding that adding it would introduce.
Put another way, the author gives the example:
> embedding("king") - embedding("man") + embedding("woman") ≈ embedding("queen")
What if you could do that but for whole bodies of text?
I'm imagining being able to do "semantic algebra" with whole paragraphs/articles/books. Instead of just prompting an LLM to "adjust the tone to be more friendly", you could have the core concept of "friendly" (or some more nuanced variant thereof) and "add" it to your existing text, etc.
luke-stanley
"starting from an embedding and working backwards to generate a piece of text that is semantically close by?" Apparently this is called embedding inversion and Universal Zero-shot Embedding Inversion https://arxiv.org/abs/2504.00147 Going incrementally closer and closer to the target with some means to vary seems to be the most general way, there are lots of ways to be more optimal though. Image diffusion with CLIP embeddings and such is kinda related too.
luke-stanley
I meant to say: Apparently this is called "embedding inversion", and that "Universal Zero-shot Embedding Inversion" is a related paper that covers a lot of the basics. Recently I learned that a ArXiv RAG agent by ArXiv Labs is a really cool way for people wanting to find out about research: https://www.alphaxiv.org/assistant Though I had ran into "inversion" before, the AlphaXiv Assistant introduced me to "embedding inversion".
smokel
Not an expert in the field, but apparently there has been some research into this. It's called inference-time intervention [1], [2].
[1] "Steering Language Models With Activation Engineering", 2023, https://arxiv.org/abs/2308.10248
[2] "Multi-Attribute Steering of Language Models via Targeted Intervention", 2025, https://arxiv.org/pdf/2502.12446
jerjerjer
> If embeddings are roughly the equivalent of a hash
Embeddings are roughly the equivalent of fuzzy hashes.
quantadev
A hash is a way of mapping a data array to a more compact representation that only has one output with the attribute of uniqueness and improbability of collision. This is the opposite of what embeddings are for, and what they do.
Embeddings are a way of mapping a data array to a different (and yes smaller) data array, but the goal is not to compress into one thing, but to spread out into an array of output, where each element of the output has meaning. Embeddings are the exact opposite of hashes.
Hashes destroy meaning. Embeddings create meaning. Hashes destroy structure in space. Embeddings create structures in space.
nighthawk454
A hash function in general is only a function that maps input to a fixed-length output. So embeddings are hash functions.
You’re probably thinking of cryptographic hashes, where avoiding collisions is important. But it’s not intrinsic. For example, Locality Sensitive Hashing where specific types of collisions are encouraged.
kaycebasques
Follow-up question based on your semantic algebra idea. If you can start with an embedding and generate semantically similar text, does that mean that "length of text" is also one of the properties that embeddings capture?
jas8425
I'm 95% sure that it does not, at least as far as the the essence of any arbitrary concept does or doesn't relate to the "length of text". Theoretically you should just as easily be able to add or subtract embeddings from a book as a tweet, though of course the former would require more computation than the latter.
bawolff
> I could tell you exactly how I think we might advance the state of the art in technical writing with embeddings, but where’s the fun in that? You now know why they’re such an interesting and useful new tool in the technical writer toolbox… go connect the rest of the dots yourself!
Wow, that's bold. I guess "good" technical writing no longer includes a thesis statement.
Seriously though, why would this be useful for technical writing? Sure you could make some similar pages widget however i dont think i've ever wanted that when reading technical docs, let alone writing them.
kaycebasques
> I guess "good" technical writing no longer includes a thesis statement.
Thesis is outlined in the second paragraph:
> What embeddings offer to technical writers is the ability to discover connections between texts at previously impossible scales.
I think it's fair, however, to say that this post is ineffective because it does not provide concrete examples of the thesis in action. My only excuse is that I never intended for this to be a standalone post but life got in the way (in the best possible way!) https://news.ycombinator.com/item?id=43964584
> why would this be useful for technical writing?
You're not going to like this answer, because it's also vague. There are 3 intractable challenges in technical writing. Embeddings can help us make progress on all 3: https://technicalwriting.dev/strategy/challenges.html
simonw
Related documents aside, technical documentation benefits from really great search.
Embeddings are a _very_ useful tool for building better search - they can handle "fuzzy" matches, where a user can say things like "that feature that lets me run a function against every column of data" because they can't remember the name of the feature.
With embeddings you can implement a hybrid approach, where you mix both keyword search (still necessary because embeddings can miss things that use jargon they weren't trained on) and vector similarity search.
I wish I had good examples to point to for this!
kaycebasques
In-site search is super important. I suspect that many docs maintainers don't realize how heavily it's used. Many docs sites don't even track in-site search queries!
One of the things I love about Sphinx is that it has a decent, client-side, JS-powered offline search. I recently hacked together a workflow for making it search-as-you-type [1]. jasonjmcghee's comment [2] has got me pondering whether we can augment it with transformer.js embeddings.
tyho
> The 2D map analogy was a nice stepping stone for building intuition but now we need to cast it aside, because embeddings operate in hundreds or thousands of dimensions. It’s impossible for us lowly 3-dimensional creatures to visualize what “distance” looks like in 1000 dimensions. Also, we don’t know what each dimension represents, hence the section heading “Very weird multi-dimensional space”.5 One dimension might represent something close to color. The king - man + woman ≈ queen anecdote suggests that these models contain a dimension with some notion of gender. And so on. Well Dude, we just don’t know.
nit. This suggests that the model contains a direction with some notion of gender, not a dimension. Direction and dimension appear to be inextricably linked by definition, but with some handwavy maths, you find that the number of nearly orthogonal dimensions within n dimensional space is exponential with regards to n. This helps explain why spaces on the order of 1k dimensions can "fit" billions of concepts.
PaulHoule
Note you don't see arXiv papers where somebody feeds in 1000 male gendered words into a word embedding and gets 950 correct female gendered words. Statistically it does better than chance, but word embeddings don't do very well.
In
https://nlp.stanford.edu/projects/glove/
there are a number of graphs where they have about N=20 points that seem to fall in "the right place" but there are a lot of dimensions involved and with 50 dimensions to play with you can always find a projection that makes the 20 points fall exactly where you want them fall. If you try experiments with N>100 words you go endlessly in circles and produce the kind of inconclusively negative results that people don't publish.
The BERT-like and other transformer embeddings far outperform word vectors because they can take into account the context of the word. For instance you can't really build a "part of speech" classifier that can tell you "red" is an adjective because it is also a noun, but give it the context and you can.
In the context of full text search, bringing in synonyms is a mixed bag because a word might have 2 or 3 meanings and the the irrelevant synonyms are... irrelevant and will bring in irrelevant documents. Modern embeddings that recognize context not only bring in synonyms but the will suppress usages of the word with different meanings, something the IR community has tried to figure out for about 50 years.
yorwba
> there are a lot of dimensions involved and with 50 dimensions to play with you can always find a projection that makes the 20 points fall exactly where you want them fall.
While it would certainly have been possible to choose a projection where the two groups of words are linearly separable, that isn't even the case for https://nlp.stanford.edu/projects/glove/images/man_woman.jpg : "woman" is inside the "nephew"-"man"-"earl" triangle, so there is no way to draw a line neatly dividing the masculine from the feminine words. But I think the graph wasn't intended to show individual words classified by gender, but rather to demonstrate that in pairs of related words, the difference between the feminine and masculine word vectors points in a consistent direction.
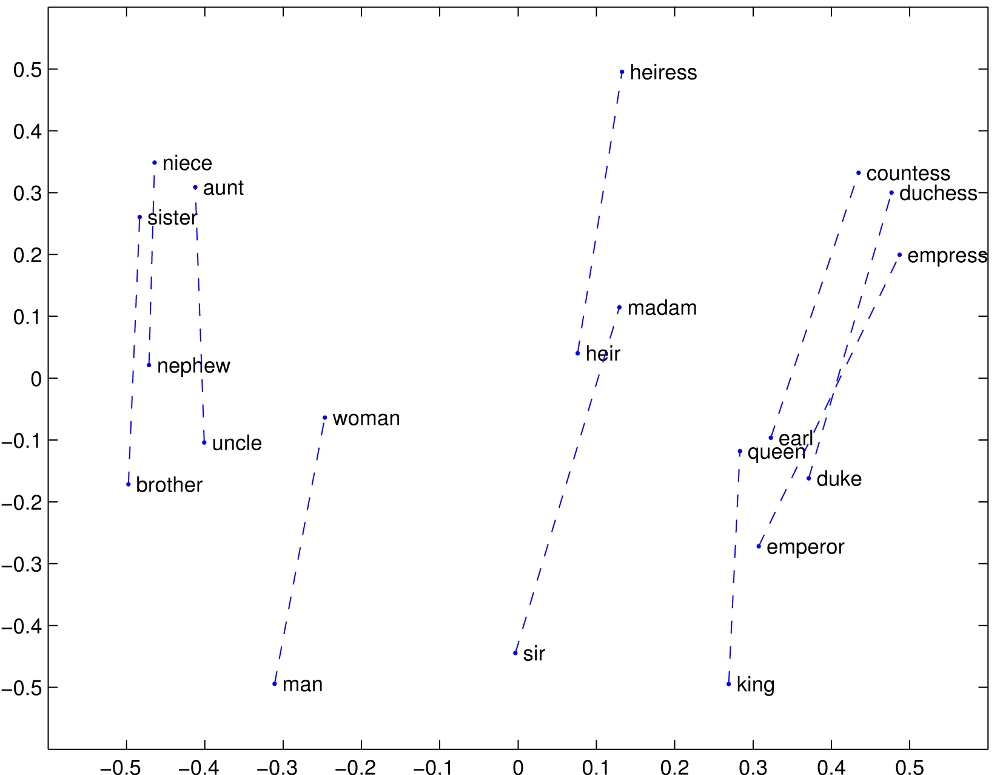{kind=link}
Of course that is hardly useful for anything (if you could compare unrelated words, at least you would've been able to use it to sort lists...) but I don't think the GloVe authors can be accused of having created unrealistic graphs when their graph actually very realistically shows a situation where the kind of simple linear classifier that people would've wanted doesn't exist.
avidiax
> the two groups of words are linearly separable
This is missing the point. What we have is two dimensions* of hundreds, but those two dimensions chosen show that the vector between a masculine word and its feminine counterpart is very nearly constant, at least across these words and excluding other dimensions.
What you're saying, a line/plane/hyper-plane that separates a dimension of gender into male and female, might also exist. But since gender neutral terms also exist, we would expect that to be a plane at which gender neutral terms have a 50/50% chance of falling to either side of the plane, and ideally nearby.
* Possibly a pseudo dimension that's a composite of multiple dimensions; IDK, I didn't read the paper.
minimaxir
> The BERT-like and other transformer embeddings far outperform word vectors because they can take into account the context of the word.
In addition to being able to utilize attention mechanisms, modern embedding models use a form of tokenization such as BPE which a) includes punctuation which is incredibly important for extracting semantic meaning and b) includes case, without as much memory requirements as a cased model.
The original BERT used an uncased, SentencePiece tokenizer which is out of date nowadays.
PaulHoule
I was working at a startup that was trying to develop foundation models around at time and BPE was such a huge improvement over everything else we'd tried at that time. We had endless meetings where people proposed that we use various embeddings that would lose 100% of the information for out-of-dictionary words and I'd point out that out-of-dictionary words (particularly from the viewpoint of the pretrained model) frequently meant something critical and if we lost that information up front we couldn't get it back.
Little did I know that people were going to have a lot of tolerance for "short circuiting" of LLMs, that is getting the right answer by the wrong path, so I'd say now that my methodology of "predictive evaluation" that would put an upper bound on what a system could do was pessimistic. Still I don't like giving credit for "right answer by wrong means" since you can't count on it.
manmal
Don’t the high end embedding services use a transformer with attention to compute embeddings? If so, I thought that would indeed capture the semantic meaning quite well, including the trait-is-described-by-direction-vector.
realbenpope
You are correct. https://deepmind.google/research/publications/157741/
philipwhiuk
> In https://nlp.stanford.edu/projects/glove/ there are a number of graphs where they have about N=20 points that seem to fall in "the right place" but there are a lot of dimensions involved and with 50 dimensions to play with you can always find a projection that makes the 20 points fall exactly where you want them fall.
Ramsey theory (or 'the Woolworths store alignment hypothesis')
kaycebasques
Oh yes, this makes a lot of sense, thank you for the "nit" (which doesn't feel like a nit to me, it feels like an important conceptual correction). When I was writing the post I definitely paused at that part, knowing that something was off about describing the model as having a dimension that maps to gender. As you said, since the models are general-purpose and work so well in so many domains, there's no way that there's a 1-to-1 correspondence between concepts and dimensions.
I think your comment is also clicking for me now because I previously did not really understand how cosine similarity worked, but then watched videos like this and understand it better now: https://youtu.be/e9U0QAFbfLI
I will eventually update the post to correct this inaccuracy, thank you for improving my own wetware's conceptual model of embeddings
manmal
This video explains the direction-encodes-trait topic very well IMO: https://youtu.be/wjZofJX0v4M
It’s the first in a series of three that I can very highly recommend.
> there's no way that there's a 1-to-1 correspondence between concepts and dimensions.
I don’t know about that! Once you go very high dimensional, there is a lot of direction vectors that are almost perfectly perpendicular to each other (meaning they can cleanly encode a trait). Maybe they don’t even need to be perfectly perpendicular, the dot product just needs to be very close to zero.
OJFord
I would think of it as the whole embedding concept again on a finer grained scale: you wouldn't say the model 'has a dimension of whether the input is king', instead the embedding expresses the idea of 'king' with fewer dimensions than would be needed to cover all ideas/words/tokens like that.
So the distinction between a direction and a dimension expressing 'gender' is that maybe gender isn't 'important' (or I guess high-information-density) enough to be an entire dimension, but rather is expressed by a linear combination of two (or more) yet more abstract dimensions.
benatkin
> Machine learning (ML) has the potential to advance the state of the art in technical writing. No, I’m not talking about text generation models like Claude, Gemini, LLaMa, GPT, etc. The ML technology that might end up having the biggest impact on technical writing is embeddings.
This is maybe showing some age as well, or maybe not. It seems that text generation will soon be writing top tier technical docs - the research done on the problem with sycophancy will likely result something significantly better than what LLMs had before the regression to sycophancy. Either way, I take "having the biggest impact on technical writing" to mean in the near term. If having great search and organization tools (ambient findability and such) is going to steal the thunder from LLMs writing really good technical docs, it's going to need to happen fast.
kaycebasques
Realistically, it's probably the combination of both embeddings and text generation models. Embeddings are a crucial technology for making more progress on the intractable challenges of technical writing [1] but then text generation models are key for applying automated updates.
aaronblohowiak
>nearly orthogonal dimensions within n dimensional space
nit within a nit: I believe you intended to write "nearly orthogonal directions within n dimensional space" which is important as you are distinguishing direction from dimension in your post.
tyho
FFS, it's too late for me to edit. You are of course correct.
ohxh
Johnson-lindenstrauss lemma [1] for anyone curious. But you can only map to k>8(\ln N)/\varepsilon ^{2}} if you want to preserve distances within a factor of \varepsilon with a JL-transform. This is tight up to a constant factor too.
I always wondered: if we want to preserve distances between a billion points within 10%, that would mean we need ~18k dimensions. 1% would be 1.8m. Is there a stronger version of the lemma for points that are well spread out? Or are embeddings really just fine with low precision for the distance?
[1] https://en.wikipedia.org/wiki/Johnson%E2%80%93Lindenstrauss_...
gweinberg
It's not at all a nit. If one of the dimensions did indeed correspond to gender, you might find "king" and "queen" pretty much only differed in one dimension. More generally, if these dimensions individually refer to human-meaningful concepts, you can find out what these concepts are just by looking at words that pretty much differ only along one dimension.
otabdeveloper4
That's the layman intuition, but actual models can give surprising results.
You can test this hypothesis with some clever LLM prompting. When I did this I got "male monarch" for "king" but "British ruler" for "queen".
Oops!
gweinberg
I'm sorry, I don't get your point at all, and have no idea what you mean by "did this". If you asked for an embedding, you would have gotten a 768 (or whatever) dimensional array right?
pletnes
There’s absolutely no reason to believe that the coordinate system of the embeddings would be aligned along the directions of individual concepts, even if they were linear and one dimensional in the embedding space.
rdtsc
> you find that the number of nearly orthogonal dimensions within n dimensional space is exponential with regards to n.
nit for the nit (micro nit!): Is it meant to be "a number of nearly orthogonal directions within n dimensional space"? Otherwise n dimensional space will have just n dimensions.
kaycebasques
Yes, confirmed here: https://news.ycombinator.com/item?id=43966937
rdtsc
Ah perfect! Thanks for sharing the article.
rahimnathwani
Nice article related to the last point (nearly orthogonal vectors):
drc500free
Is this because we can essentially treat each dimension like a binary digit, so we get 2^n directions we can encode? Or am I barking up totally the wrong tree?
emaro
Basically, but it gets even better. If you allow directions of 'meaning' do wiggle a little bit (say, between 89 and 91 degrees to all other directions), you get a lot more degrees of freedom. In 3 dimensions, you still only get 3 meaningful directions with that wiggle-freedom. However in high-dimensional spaces, this small additional freedom allows you to fit a lot more almost orthogonal directions than the number of strictly orthogonal ones. That means in a 1000-dimensional space you can fit a huge number >> 1000 of binary concepts.
jacobr1
I may have missed it ... but were any direct applications to tech writers discussed in this article? Embeddings are fascinating and very important for things like LLMs or semantic search, but the author seems to imply more direct utility.
kaycebasques
> were any direct applications to tech writers discussed in this article
No, it was supposed to be a teaser post followed up by more posts and projects exploring the different applications of embeddings in technical writing (TW). But alas, life happened, and I'm now a proud new papa with a 3-month old baby :D
I do have other projects and embeddings-related posts in the pipeline. Suffice to say, embeddings can help us make progress on all 3 of the "intractable" challengs of TW mentioned here: https://technicalwriting.dev/strategy/challenges.html
kaycebasques
Also re: a direct application I forgot to mention this: https://www.tdcommons.org/dpubs_series/8057/
(It finally published last week after being in review purgatory for months)
jacobr1
Thanks for sharing regardless. It was a good overview for those less familiar with the material.
PaulHoule
Semantic search and classification and clustering. For the first, there is a substantial breakthrough in IR every 10 years or so you take what you can get. (I got so depressed reading TREC proceedings which seemed to prove that "every obvious idea to improve search relevance doesn't work" and it wasn't until I found a summary of the first ten years that I learned that the first ten years had turned up one useful result, BM2.5)
As for classification, it is highly practical to put a text through an embedding and then run the embedding through a classical ML algorithm out of
https://scikit-learn.org/stable/supervised_learning.html
This works so consistently that I'm considering not packing in a bag-of-words classifier in a text classification library I'm working on. People who hold court on Huggingface forums tends to believe you can do better with fine-tuned BERT, and I'd agree you can do better with that, but training time is 100x and maybe you won't.
20 years ago you could make bag-of-word vectors and put them through a clustering algorithm
https://scikit-learn.org/stable/modules/clustering.html
and it worked but you got awful results. With embeddings you can use a very simple and fast algorithm like
https://scikit-learn.org/stable/modules/clustering.html#k-me...
and get great clusters.
I'd disagree with the bit that it takes "a lot of linear algebra" to find nearby vectors, it can be done with a dot product so I'd say it is "a little linear algebra"
sansseriff
It would be great to semantically search through literature with embeddings. At least one person I know if is trying to generate a vector database of all arxiv papers.
The big problem I see is attribution and citations. An embedding is just a vector. It doesn't contain any citation back to the source material or modification date or certificate of authenticity. So when using embeddings in RAG, they only serve to link back to a particular page of source material.
Using embeddings as links doesn't dramatically change the way citation and attribution are handled in technical writing. You still end up citing a whole paper or a page of a paper.
I think GraphRAG [1] is a more useful thing to build on for technical literature. There's ways to use graphs to cite a particular concept of a particular page of an academic paper. And for the 'citations' to act as bidirectional links between new and old scientific discourse. But I digress
kaycebasques
IMO, for technical writing, citing a page or section within a page is usually good enough. I rarely need to cite a particular concept. But I've never even thought of the possibility of more granular concept-level citations and will definitely be pondering it more!
podgietaru
I built an rss aggregator with semantic search using embeddings. The main usage was being able to categorise based on any randomly created category. So you could have arbitrary categories
https://github.com/aws-samples/rss-aggregator-using-cohere-e...
Unfortunately I no longer work at AWS so the infrastructure that was running it is down.
petesergeant
I wrote an embeddings explainer a few days ago if anyone is interested: https://sgnt.ai/p/embeddings-explainer/
Very little maths and lots of dogs involved.
jonathanrmumm
Embeddings are a new jump to universality, like the alphabet or numbers. https://thebeginningofinfinity.xyz/Jump%20to%20Universality
paulnovacovici
Completely agree. I’ve been experimenting with embeddings by building Recallify, primarily to help me quickly retrieve obscure things I’ve read online. Even at just 1024 dimensions, it’s impressive how effectively embeddings capture and surface ideas based purely on semantic similarity, rather than exact keyword recall (which I’m pretty terrible at remembering). It’s been a game changer for turning fuzzy mental concepts into actionable insights.
Beta testing an iOS app for it if anyone is interested: https://recallify.app/
gweinberg
I don't understand why some people consider the concept of many dimensions to be so mysterious. It's numbers specifying something like degrees of freedom. If I wanted to specify the position of my body sitting at my desk, I might say use two angles to specify the what is happening at each joint, and so would probably need a couple hundred to fully specify my position. A human being probably could not look at the numbers and see "he's sitting at a desk", but I don't see the conceptual difficulty".
JohnKemeny
You're right that higher dimensions are just more degrees of freedom, and mathematically it's just more numbers. But what's counterintuitive is how geometry behaves differently as dimensions grow. Things like distance, volume, and angles don’t scale the way we expect. For example, in high dimensions, almost all the volume of a sphere concentrates near its surface, and random vectors tend to be nearly orthogonal—something that rarely happens in 2D or 3D.
These effects matter in practice. In high-dimensional spaces like word embeddings, even unrelated points can seem equidistant, making basic tasks like clustering or similarity search much harder. So it's not that higher dimensions are mysterious per se, but that they defy the spatial intuitions we've developed from living in three.
lblume
Semantic search seems like a more promising usecase than simple related articles. A big problem with classical keyword-based search is that synonyms are not reflected at all. With semantic search you can search for what you mean, not what words you expect to find on the site you are looking for.
PaulHoule
A case related to that is "more like this" which in my mind breaks down into two forks:
(1) Sometimes your query is a short document. Say you wanted to know if there were any patents similar to something you invented. You'd give a professional patent searcher a paragraph or a few paragraphs describing the invention, you can give a "semantic search engine" the paragraph -- I helped build one that did about as well as the professional using embeddings before this was cool.
(2) Even Salton's early works on IR talked about "relevance feedback" where you'd mark some documents in your results as relevant, some as irrelevant. With bag-of-words this doesn't really work well (it can take 1000 samples for a bag-of-words classifier to "wake up") but works much better with embeddings.
The thing is that embeddings are "hunchy" and not really the right data structure to represent things like "people who are between 5 feet and 6 feet tall and have been on more than 1000 airplane flights in their life" (knowledge graph/database sorts of queries) or "the thread that links the work of Derrida and Badiou" (could be spelled out logically in some particular framework but doing that in general seems practically intractable)
ted_dunning
Regarding item (2), Salton did talk about this and many systems from the early TREC times implemented them.
In my own work, I found that relevance feedback worked very well with only a few dozen judgements. See Chapter 7 starting on page 83 in my dissertation: https://arxiv.org/abs/1207.1847
Note also that the evaluation of Luduan in that chapter compared against state-of-the-art (for the time) back-of-words systems but also an early word embedding retrieval system (Convectis from HNC).
kgeist
In my benchmarks for a service which is now running in production, hybrid search based on both keywords and embeddings performed the best. Sometimes you need exact keyword matches; other times, synonyms are more useful. Hybrid search combines both sets of results into a single, unified set. OpenSearch has built-in support for this approach.
jbellis
they're both useful
search is an active "I'm looking for X"
related articles is a passive "hey thanks for reading this article, you might also like Y"
Hello, I wrote this. Thank you for reading!
The post was previously discussed 6 months ago: https://news.ycombinator.com/item?id=42013762
To be clear, when I said "embeddings are underrated" I was only arguing that my fellow technical writers (TWs) were not paying enough attention to a very useful new tool in the TW toolbox. I know that the statement sounds silly to ML practitioners, who very much don't "underrate" embeddings.
I know that the post is light on details regarding how exactly we apply embeddings in TW. I have some projects and other blog posts in the pipeline. Short story long, embeddings are important because they can help us make progress on the 3 intractable challenges of TW: https://technicalwriting.dev/strategy/challenges.html