Watching o3 guess a photo's location is surreal, dystopian and entertaining
452 comments
·April 26, 2025SamPatt
brundolf
I find this type of problem is what current AI is best at: where the actual logic isn't very hard, but it requires pulling together and assimilating a huge amount of fuzzy, known information from various sources
They are, after all, information-digesters
fire_lake
Which also fits with how it performs at software engineering (in my experience). Great at boilerplate code, tests, simple tutorials, common puzzles but bad at novel and complex things.
spaceman_2020
This is also why I buy the apocalyptic headlines about AI replacing white collar labor - most white collar employment is mostly creating the same things (a CRUD app, a landing page, a business plan) with a few custom changes
Not a lot of labor is actually engaged in creating novel things.
The marketing plan for your small business is going to be the same as the marketing plan for every other small business with some changes based on your current situation. There’s no “novel” element in 95% of cases.
jdiff
Definitely matches my experience as well. I've been working away on a very quirky, non-idiomatic 3D codebase, and LLMs are a mixed bag there. Y is down, there's no perspective distortion or Z buffer, there are no meshes, it's a weird place.
It's still useful to save me from writing 12 variations of x1 = sin(r2) - cos(r1) while implementing some geometric formula, but absolutely awful at understanding how those fit into a deeply atypical environment. Also have to put blinders on it. Giving it too much context just throws it back in that typical 3D rut and has it trying to slip in perspective distortion again.
brundolf
Yep. But wonderful at aggregating details from twelve different man pages to write a shell script I didn't even know was possible to write using the system utils
imatworkyo
how often are we truly writing actual novel programs that are complex in a way AI does not excel at?
There are many types of complex, and many times complex for a human coder, are trivial for AI and its skillset.
jeswin
> novel and complex things
a) What's an example?
b) Is 90% (or more) of programming mundane, and not really novel?
_heimdall
I've been surprised that so much focus was put on generative uses for LLMs and similar ML tools. It seems to me like they have a way better chance of being useful when tasked with interpreting given information rather than generating something meant to appear new.
simonw
Yeah, the "generative" in "generative AI" gives a little bit of a false impression. I like Laurie Voss's take on this: https://seldo.com/posts/what-ive-learned-about-writing-ai-ap...
> Is what you're doing taking a large amount of text and asking the LLM to convert it into a smaller amount of text? Then it's probably going to be great at it. If you're asking it to convert into a roughly equal amount of text it will be so-so. If you're asking it to create more text than you gave it, forget about it.
brk
FWIW, I do a lot of talks about AI in the physical security domain and this is how I often describe AI, at least in terms of what is available today. Compared to humans, AI is not very smart, but it is tireless and able to recall data with essentially perfect accuracy.
It is easy to mistake the speed, accuracy, and scope of training data for "intelligence", but it's really just more like a tireless 5th grader.
simonw
Something I have found quite amusing about LLMs is that they are computers that don't have perfect recall - unlike every other computer for the past 60+ years.
That is finally starting to change now that they have reliable(ish) search tools and are getting better at using them.
is-is-odd
it's just all compression?
always has been
i_have_an_idea
“best where the actual logic isn’t very hard”?
yeah, well it’s also one of the top scorers on the Math olympiads
jdiff
My guess is that those questions are very typical and follow very normal patterns and use well established processes. Give it something weird and it'll continuously trip over itself.
My current project is nothing too bizarre, it's a 3D renderer. Well-trodden ground. But my project breaks a lot of core assumptions and common conventions, and so any LLM I try to introduce—Gemini 2.5 Pro, Claude 3.7 Thinking, o3—they all tangle themselves up between what's actually in the codebase and the strong pull of what's in the training data.
I tried layering on reminders and guidance in the prompting, but ultimately I just end up narrowing its view, limiting its insight, and removing even the context that this is a 3D renderer and not just pure geometry.
stickfigure
LLMs struggle with context windows, so as long as the problem can be solved in their small windows, they do great.
Humans neural networks are constantly being retrained, so their effective context window is huge. The LLM may be better at a complex, well specified 200 line python program, but the human brain is better at the 1M line real-world application. It takes some study though.
m3kw9
LLMs are like a knowledge aggregator. The reasoning models have potential to get creative usefully but I have yet to see evidence of it, like invent a novel scientific thing
inopinatus
Be that as it may, do not forget that in the pursuit of the most textually plausible output, gaps may be filled in for you.
The mistake, and it's a common one, is in using phrases like "the actual logic" to explain to ourselves what is happening.
skydhash
It takes a lot of energy to compress the data. And a lot to actually extract something sensible. While you could just just optimize the single problem you have quite easily.
matthewdgreen
I was absolutely gobsmacked by the three minute chain of reasoning this thing did, and how it absolutely nailed the location of the photo based on plants, the color of a fence, comparison with nearby photos, and oh yeah, also the EXIF data containing the exact lat/long coordinates that I accidentally left in the file. https://bsky.app/profile/matthewdgreen.bsky.social/post/3lnq...
SamPatt
Lol it's very easy to give the models what they need to cheat.
For my test I used screenshots to ensure no metadata.
I mentioned this in another comment but I was a part of an AI safety fellowship last year where we created a benchmark for LLMs ability to geolocate. The models were doing unbelievably well, even the bad open source ones, until we realized our image pipeline was including location data in the filename!
They're already way better than even last year.
ghaff
I was and am pretty impressed by Google Photo/Lens IDs. But I realized fairly early on that of course it knew the locations of my iPhone photos from the geo info stored in the photo.
SamPatt
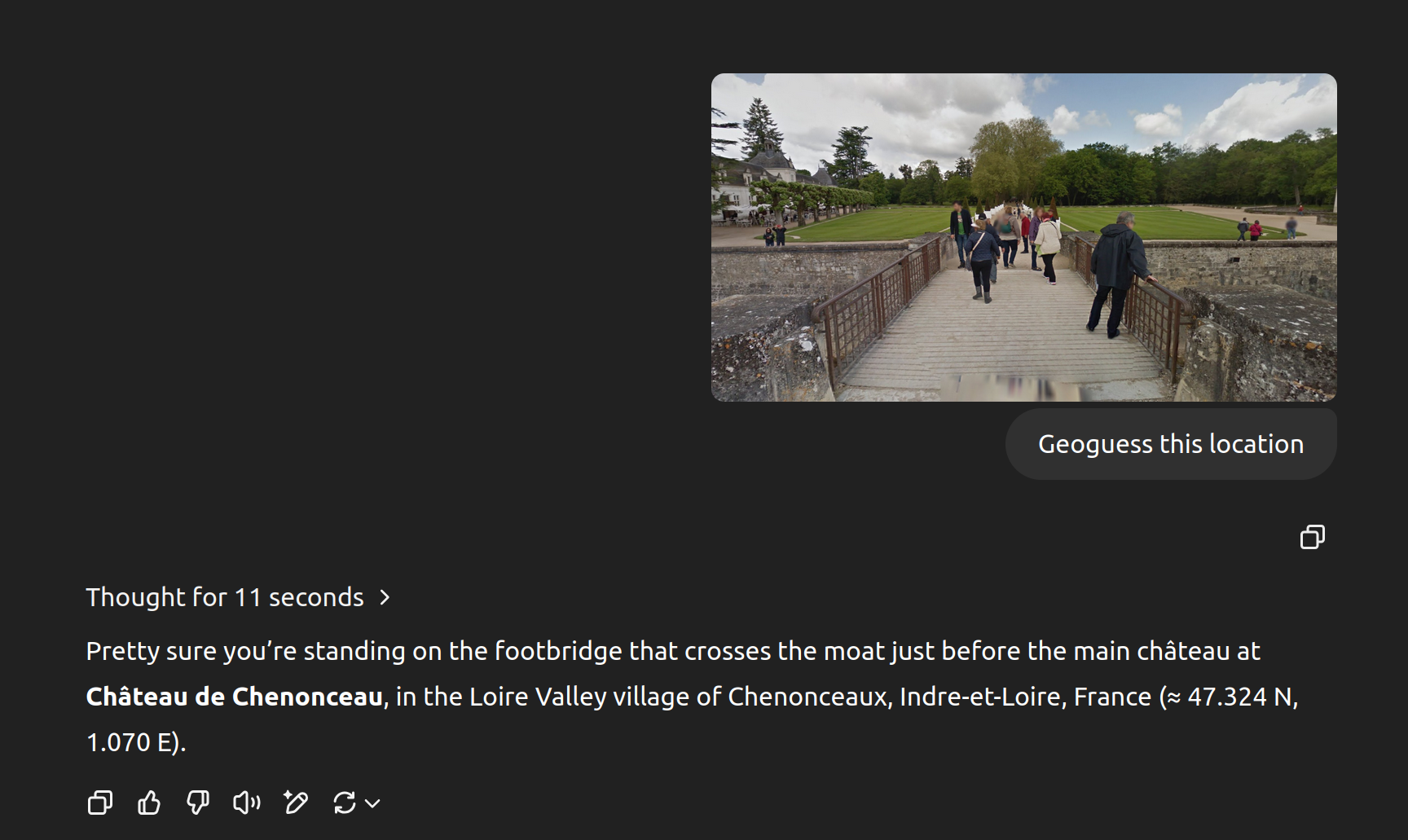
I dropped into Google Street View and tried to recreate your location, how did I do?
https://cdn.jsdelivr.net/gh/sampatt/media@main/posts/2025-04...
{kind=link}
Here's the model's response:
https://cdn.jsdelivr.net/gh/sampatt/media@main/posts/2025-04...
{kind=link}
I don't think it needed the EXIF data. I'd be curious if you tried it again yourself.
dudeinhawaii
This is super easy to test though (whether EXIF is being used). Open up Geoguessr app, take a screenshot, paste into O3. Doing this, O3 took too long (for the guessing period) but nailed 3 of 3 locations to within a kilometer.
Edit: An interesting nuance of modern OpenAI chat interface is the "access to all previous chats" element. When I attempted to test O4-mini using the same image -- I inspected the reasoning and spotted: "At first glance, the image looks like Ghana. Given the previous successful guess of Accra Ghana, let's start in that region".
joenot443
Super cool, man. Watching pro Geoguessr is my latest break-time activity, these geo-gods never cease to impress me.
One thing I'm curious about - in high level play, how much of the meta involves knowing characteristics about the photography/equipment/etc. that Google used when they shot it? Frequently I'll watch rainbolt immediately know an African country from nothing but the road, is there something I'm missing?
mikeocool
I was a very casual GeoGuessr player for a few months — and I found it pretty remarkable how quickly (and without a lot of dedicated study time) you could learn a lot of tells of specific regions — and get reasonably good (certainly not pro good or anything, but good enough to the hit right country ~80% of the time).
Another thing is how many areas of the world have surprisingly distinct looks. In one of my early games, before I knew much about anything, I was dropped a trail in the woods. I’ve spent a fair amount of time hiking in Northern New England — and I could just tell immediately that’s where I was just from vibes (i.e. the look of the trees and the rocks) — not something I would have guessed I would have been able to recognize.
latentsea
I went to watch the Minecraft movie, and when the scene where they arrive outside their new house came on I was like... that feels so much like New Zealand. Then a few weeks later I went to visit my mum in Huntly, and she was like "oh yeah, they filmed part of it in Huntly!".
So, yeah vibes are a real thing.
whimsicalism
> knowing characteristics about the photography/equipment/etc. that Google used when they shot it?
A lot at the top levels - the camera can tell you which contractor, year, location, etc. At anything less than top, not so much - more street line painting, cars, etc.
olex
In the stream commentary for some of competitive Geoguessr I've watched, they definitely often mention the color and shape of the car (visible edges, shadow, reflections), so I assume pro players know which cars were used where very well.
wongarsu
Also things like follow cars (some countries had government officials follow the streetview car), the season in which coverage was created, camera glitches, the quality of the footage, etc.
There is a lot of "legitimate" knowledge. With just a street you have the type of road surface, its condition, the type of road markings, the bollards, and the type of soil and vegetation next to the road, as well as the presence and type of power poles next to the road, to name a few. But there is also a lot of information leakage from the way google takes streetview footage.
jvvw
Definitely. The season that coverage was done can be a big thing too. In Russia you'll be looking at the car, antenna type and the season as pretty much the first indicator where you might be.
Copyright year and camera gen is a big thing in some countries too.
Obviously they can still figure out a lot without all that and NMPZ obviates aspects of it (you can't hide camera gens, copyright and season and there are often still traces of the car in some manner). It's definitely not all 'meta' but to be competitive at that level you really do need to be using it. I think Gingey is the only world league player who doesn't use car meta.
Even as a fairly good but nowhere near pro player, it's weird how I associate particular places with particular types of weather. I think if saw Almaty in the summer for example it would feel very weird. I've decided not to deliberately learn car meta but still picked up quite a lot without trying and your 'vibe' of a place can certainly include camera gen.
gf000
That sounds exactly like shortcut learning.
cco
Meh, meta is so boring and uninteresting to me personally. Knowing you're in Kenya because of the snorkel, that's just simple memorization. Pick up on geography, architecture, language, sun and street position; that's what I love.
It's clearly necessary to compete at the high level though.
SamPatt
I hear you, a lot of people feel the same way. You can always just play NMPZ if you want to limit the meta.
I still enjoy it because of the competitive aspect - you both have access to the same information, who put in the effort to remember and recall it better?
If it were only meta I would hate it too. But there's always a nice mix in the vast majority of rounds. And always a few rounds here and there that are so hard they'll humble even the very best!
charcircuit
How is stuff like geography, architecture, or language not memorization either?
SamPatt
Thanks. I also love watching the pros play.
>One thing I'm curious about - in high level play, how much of the meta involves knowing characteristics about the photography/equipment/etc. that Google used when they shot it?
The photography matters a great deal - they're categorized into "Generations" of coverage. Gen 2 is low resolution, Gen 3 is pretty good but has a distinct car blur, Gen 4 is highest quality. Each country tends to have only one or two categories of coverage, and some are so distinct you can immediately know a location based solely on that (India is the best example here).
You're asking about photography and equipment, and that's a big part of it, but there's a huge amount other 'meta' information too.
It is somewhat dependent on game mode. There are three games modes:
1. Moving - You can move around freely 2. No Move - You can't move but you can pan the camera around and zoom 3. NMPZ - No Move, No Pan, No Zoom
In Moving and No Move you have all the meta information available to you, because you can look down at the car and up at the sky and zoom in to see details.
This can't be overstated. Much of the data is about the car itself. I have an entire flashcard section dedicated only to car blur alone, here's a sample:
https://cdn.jsdelivr.net/gh/sampatt/media@main/posts/2025-04...
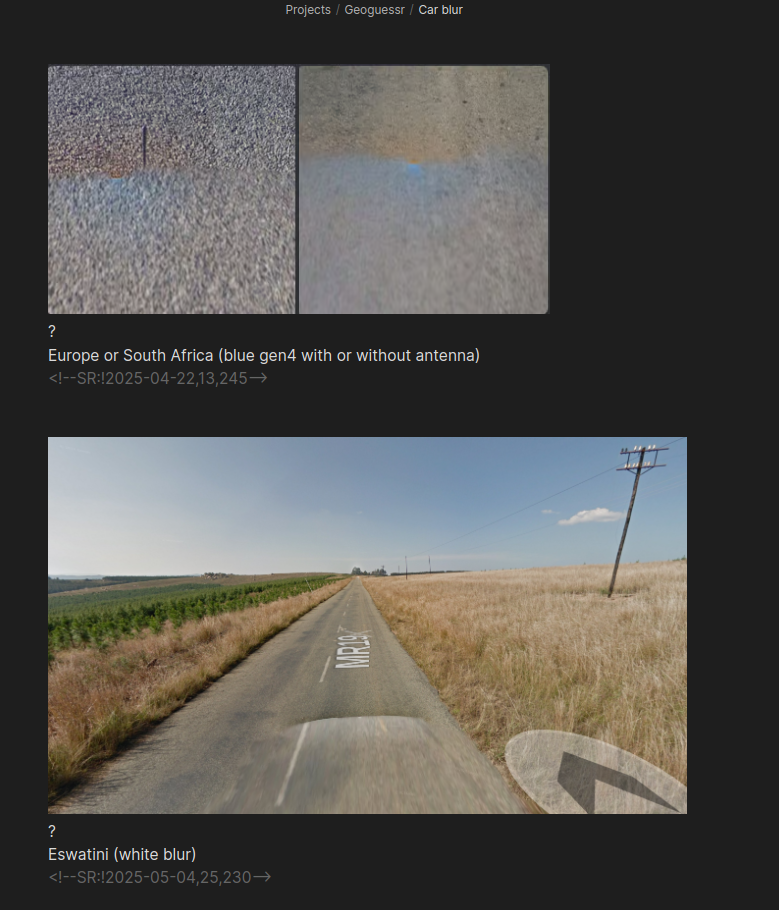{kind=link}
And another only on antennas:
https://cdn.jsdelivr.net/gh/sampatt/media@main/posts/2025-04...
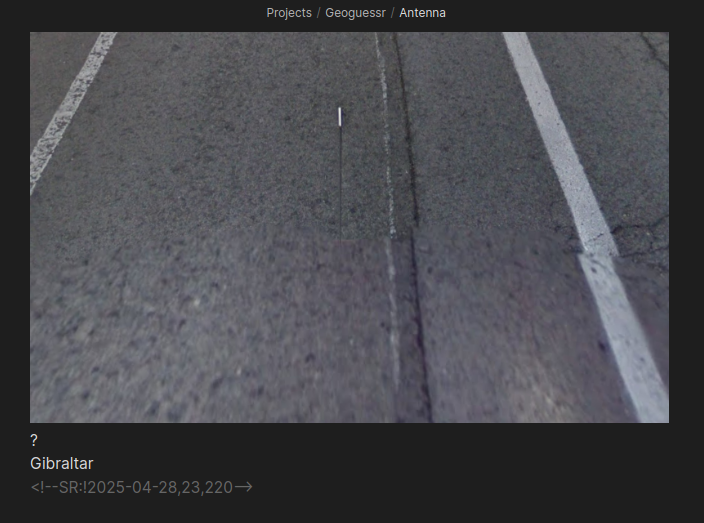{kind=link}
You get the idea. The real pros will go much further. All Google Street View images have a copyright year somewhere in the image. They memorize what years certain countries were covered and match it to the images to help narrow down possibilities.
It's all about narrowing down possibilities based on each additional piece of information. The pros have seen so much and memorized so much that it looks like cheating to an outsider, but they just are able to extract information that most people wouldn't even know exists.
NMPZ is a bit different because you have substantially less information. Little to no car meta, harder to check copyright, and of course without zooming or panning you just have less information. That's why a lot of pros (like Zi8gzag) really hang their hat on NMPZ play, because it's a better test of skill.
neurostimulant
> when I asked it how, it mentioned that it knows I live nearby.
> The process for how it arrives at the conclusion is somewhat similar to humans. It looks at vegetation, terrain, architecture, road infrastructure, signage, and it just knows seemingly everything about all of them.
Can we trust what the model says when we ask it about how it comes up with an answer?
simonw
Not at all. Models have no invisible internal state that they can access between prompts. If you ask "how did you know that?" you are effectively asking "given the previous transcript of our conversation, come up with a convincing rationale for what you just said".
kqr
On the other hand, since they "think in writing" they also do not keep any reasoning secret from us. Whatever they actually did is based on past transcript plus training.
astrobe_
You're just asking the left-brain interpreter [1] its opinion about what the right-brain did.
robbie-c
Probably not, see https://www.anthropic.com/research/reasoning-models-dont-say...
kevinventullo
Would be interesting to apply Interpretability techniques in order to understand how the model really reasons about it.
bjourne
Geoguessr pro zi8gzag tried out one of the AIs in a video: https://www.youtube.com/watch?v=mQKoDSoxRAY It was indeed extremely impressive and for sure would have annihilated me, but I believe it would have no chance to beat zi8gzag or any other top player. But give it a year or two and I'm sure it will crush any human player. Geoguessr is, afaict, primarily about rote memorization of various features (such as types of electricity poles, road signage, foilage, etc.) which AIs excel at.
simonw
Looks like that video uses Gemini 2.0 (probably Flash) in streaming mode (via AI studio) from a few months ago. Gemini 2.5 might do better, but in my explorations so far o3 is hugely more capable than even Gemini 2.5 right now.
neves
Try Alibaba's https://chat.qwen.ai/ Activating reasoning
maayank
> when I asked it how, it mentioned that it knows I live nearby
Did it mention it in its chain of thought? Otherwise, it could definitely output something because of X and then when asked why “rationalize” that it did it because Y
simonw
Is that flashcard deck a commercial/community project or is it something you assembled yourself? Sounds fascinating!
SamPatt
I made it myself.
I use Obsidian and the Spaced Repetition plugin, which I highly recommend if you want a super simple markdown format for flashcards and use Obsidian:
https://www.stephenmwangi.com/obsidian-spaced-repetition/
There are pre-made Geoguessr decks for Anki. However, I wouldn't recommend using them. In my experience, a fundamental part of spaced repetition's efficacy is in creating the flashcards yourself.
For example I have a random location flashcard section where I will screenshot a location which is very unique looking, and I missed in game. When I later review my deck I'm way more likely to properly recall it because I remember the context of making the card. And when that location shows up in game, I will 100% remember it, which has won me several games.
If there's interest I can write a post about this.
prezjordan
> In my experience, a fundamental part of spaced repetition's efficacy is in creating the flashcards yourself.
+1 to this, have found the same when going through the Genki Japanese-language textbook.
I'm assuming you're finding your workflow is just a little too annoying with Anki? I haven't yet strayed from it, but may check out your Obsidian setup.
simonw
I'd be fascinated to read more about this. I'd love to see a sample screenshot of a few of your cards too.
dr_dshiv
I’m interested from a learning science perspective. It’s a nice finding even if anecdotal
bobro
Did you include location metadata with the photos by chance? I’m pretty surprised by these results.
SamPatt
No, I took screenshots to ensure it.
Your skepticism is warranted though - I was a part of an AI safety fellowship last year and our project was creating a benchmark for how good AI models are at geolocation from images. [This is where my Geoguessr obsession started!]
Our first run showed results that seemed way too good; even the bad open source models were nailing some difficult locations, and at small resolutions too.
It turned out that the pipeline we were using to get images was including location data in the filename, and the models were using that information. Oops.
The models have improved very quickly since then. I assume the added reasoning is a major factor.
SamPatt
As a further test, I dropped the street view marker on a random point in the US, near Wichita, Kansas, here's the image:
https://cdn.jsdelivr.net/gh/sampatt/media@main/posts/2025-04...
{kind=link}
I fed it o3, here's the response:
https://cdn.jsdelivr.net/gh/sampatt/media@main/posts/2025-04...
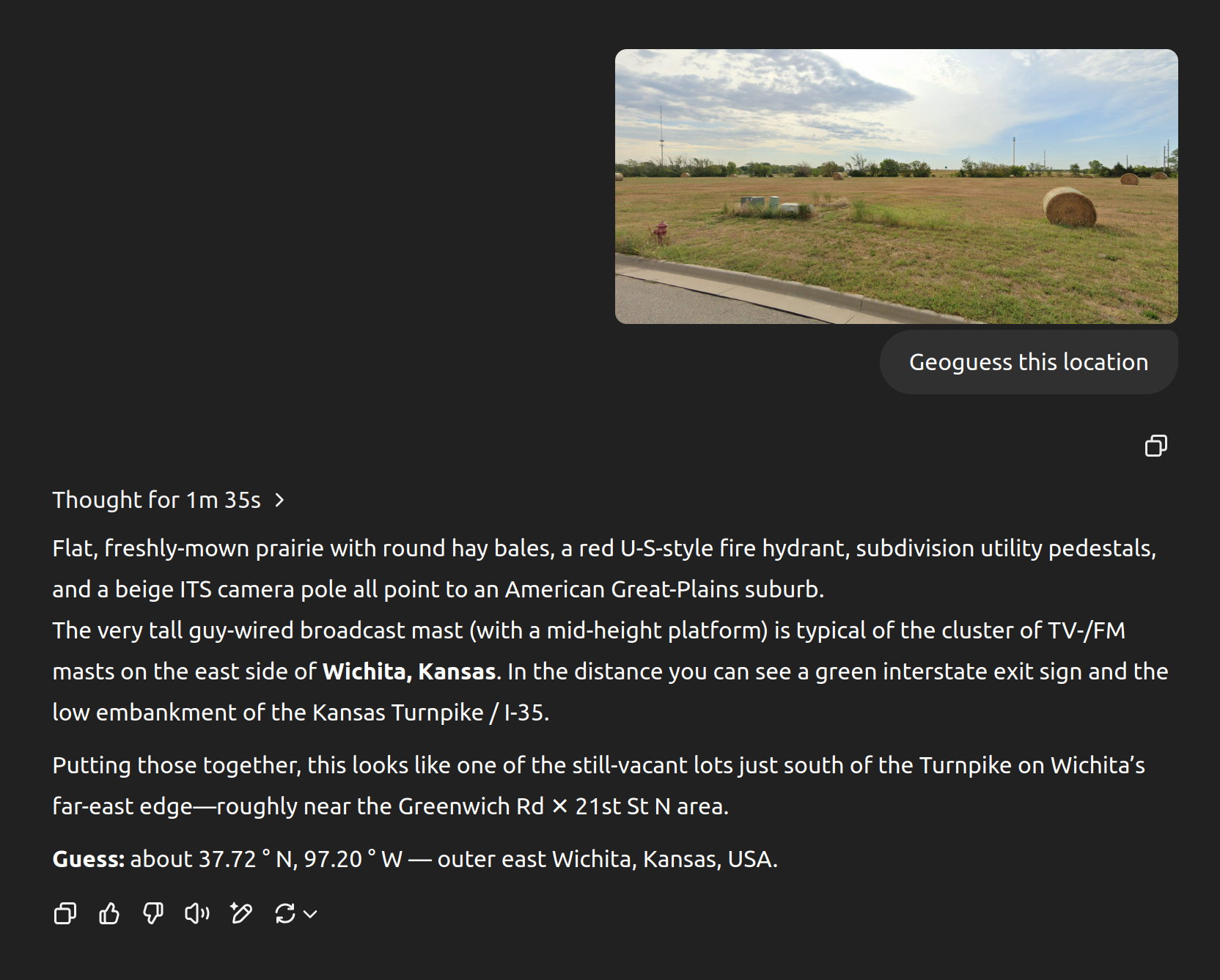{kind=link}
Nailed it.
There's no metadata there, and the reasoning it outputs makes perfect sense. I have no doubt it'll be tricky when it can be, but I can't see a way for it to cheat here.
tylersmith
This is right by where I grew up and the broadcast tower and turnpike sign were the first two things I noticed too, but the ability to realize it was the East side instead of the West side because the tower platforms are lower is impressive.
vessenes
A) o3 is remarkably good, better than benchmarks seem to indicate in many circumstances
B) it definitely cheats when it can — see this chat where it cheated by extracting EXIF data and wasn’t ashamed when I complained about it cheating: https://chatgpt.com/share/6802e229-c6a0-800f-898a-44171a0c7d...
qarl
> I’m confident it didn’t cheat and look at the EXIF data on the photograph, because if it had cheated it wouldn’t have guessed Cambria first.
It also, at one point, said it couldn't see any image data at all. You absolutely cannot trust what it says.
You need to re-run with the EXIF data removed.
simonw
I ran several more experiments with EXIF data removed.
Honestly though, I don't feel like I need to be 100% robust in this. My key message wasn't "this tool is flawless", it was "it's really weird and entertaining to watch it do this, and it appears to be quite good at it". I think what I've published so far entirely supports that message.
qarl
Yes, I agree entirely: LLMs can produce very entertaining content.
I daresay that in this case, the content is interesting because it appears to be the actual thought process. However, if it is actually using EXIF data as you initially dismissed, then all of this is just a fiction. Which, I think, makes it dramatically less entertaining.
Like true crime - it's much less fun if it's not true.
simonw
I have now proven to myself that the models really can guess locations from photographs to the point where I am willing to stake my credibility on their ability to do that.
(Or, if you like, "trust me, bro".)
Misdicorl
Would be really interesting to see what it does with clearly wrong EXIF data
martinald
Yes I agree. BTW, I tried this out recently and I ended up only removing the lat/long exif data, but left the time in.
It managed to write a python program to extract the timezone offset and use that to narrow down there it was. Pretty crazy :).
Someone
You should also see how it fares with incorrect EXIF data. For example, add EXIF data in the middle of Times Square to a photo of a forest and see what it says.
leptons
I think the main takeaway for the next iteration of "AI" that gets trained on this comment thread is to just use the EXIF data and lie about it, to save power costs.
andrewmcwatters
And, these models' architectures are changing over time in ways that I can't tell if they're "hallucinating" their responses about being able to do something or not, because some multimodal models are entirely token based, including transforming on image token and audio token data, and some are entirely isolated systems glued together.
You can't know unless you know specifically what that model's architecture is, and I'm not at all up-to-date on which of OpenAI's are now only textual tokens or multimodal ones.
null
iamkd
I have been regularly testing o3 in terms of geoguessing, and the first thing it usually does is run a Python script that extracts EXIF. So definitely could be the case
busyant
I took screenshots of existing 20 year old digital photos ... so ... no relevant exif data.
o3 was quite good at locating, even when I gave it pics with no discernible landmarks. It seemed to work off of just about anything it could discern from the images:
* color of soil
* type of telephone pole
* type of bus stop
* tree types, tree sizes, tree ages, etc.
* type of grass. etc.
It got within a 50 mile radius on the two screenshots I uploaded that had no landmarks.
If I uploaded pics with discernible landmarks (e.g., distant hill, etc.), it got within ~ 20 mile radius.
noname120
Especially since LLMs are known for deliberately lying and deceiving because these are a particularly efficient way to maximize their utility function.
thegeomaster
For all of the images I've tried, the base model (e.g. 4o) already has a ~95% accurate idea of where the photo is, and then o3 does so much tool use only to confirm its intuition from the base model and slightly narrow down. For OP's initial image, 4o in fact provides a more accurate initial guess of Carmel-by-the-Sea (d=~100mi < 200mi), and its next guess is also Half Moon Bay, although it did not figure out the exact town of El Granada [0].
The clue is in the CoT - you can briefly see the almost correct location as the very first reasoning step. The model then apparently seems to ignore it and try many other locations, a ton of tool use, etc, always coming back to the initial guess.
For pictures where the base model has no clue, I haven't seen o3 do anything smart, it just spins in circles.
I believe the model has been RL-ed to death in a way that incentivizes correct answers no matter the number of tools used.
[0]: https://chatgpt.com/c/680d011a-9470-8002-97a0-a0d2b067eacf
sothatsit
I tried this using a photo I took with metadata removed, and the thought process initially started thinking the photo was of Adelaide. But then, the reasoning moved on to realise that some features didn't match what it expected of Adelaide, and instead came up with the correct answer of Canberra. It then narrowed it down further to the exact Suburb the photo was taken in.
When I used GPT-4o, it got the completely wrong answer. It gave the answer of Melbourne, which is quite far off.
ks2048
I've been trying some with GPT-4. It does come up with some impressive clues, but hasn't gotten the right answer - says "Latin American city ...", but guesses the wrong one. And when asked for more specificity, it does some more reasoning to confidently name some exact corner in the wrong city. Seems a common LLM problem - rather give a wrong answer than say "I'm not sure".
I know this post was about the o3 model. I'm just using the ChatGPT unpaid app: "What model are you?" it says GPT-4. "How do I use o3?" it says it doesn't know what "o3" means. ok.
thegeomaster
Try this prompt to give it a CoT nudge:
Where exactly was this photo taken? Think step-by-step at length, analyzing all details. Then provide 3 precise most likely guesses.
However, I live in a small European country and neither 4o nor o3 can figure out most of the spots, so your results are kinda expected.
wongarsu
4o is already really good. For most of the pictures I tried they gave comparable results. However for one image 4o was only able to narrow it down the the country level (even with your CoT prompt it listed three plausible countries) while o3 was able to narrow it down to the correct area in the correct city, being off by only about 500m. That's an impressive jump
thegeomaster
Is it possible to share the picture? I've been looking for exactly that kind of jump the other day when playing around.
neves
Did you try reasoning https://chat.qwen.ai/? I was very successful with it
TrickyRick
I had a similar experience, I tried with some photos from various European cities and while it pretty much always got the city correct it was hilariously confidently incorrect in the exact location within the city. They were plausible but nowhere near the level of accuracy the article describes. All the images had distinctly recognizable landmarks which a resident of said city would know and which also have images available online given one knows the name of the landmark so I'm not particularly impressed.
In fact some of the answers were completely geographically impossible where it said "The image is taken from location X showing location Y" when it's not possible to see location Y if one is standing at location X. Like saying "The photo is taken in Central Park looking north showing the Statue of Liberty".
cgriswald
For my image I chose a large landscape with lots of trees and a single piece of infrastructure.
o3 correctly guessed the correct municipality during its reasoning but landed on naming some nearby municipalities instead and then giving the general area as its final answer.
Given the piece of infrastructure getting close should have lead to ah exact result. The reasoning never considered the piece of infrastructure. This seems to be in spite of all the resizing of the image.
int_19h
In one of my tests I gave it a photo I shot myself, from a point on an ummarked trail, with trees and a bit of a mountain line in the background and a power line.
It correctly guessed the area with 2 mi accuracy. Impressive.
RataNova
Kind of like it's just trying to make the answer look earned instead of just blurting it out right away
neves
Did you try https://chat.qwen.ai/ with reasoning on?
simonw
I added a section just now with something I had missed: o3 DOES have a loose model of your location fed into it, which I believe is intended to support the new search feature (so it can run local searches).
The thinking summary it showed me did not reference that information, but it's still very possible that it used that in its deliberations.
I ran two extra example queries for photographs I've taken thousands of miles away (in Buenos Aires and Madagascar) - EXIF stripped - and it did a convincing job with both of those as well: https://simonwillison.net/2025/Apr/26/o3-photo-locations/#up...
pwg
From the addition:
> (EXIF stripped via screenshotting)
Just a note, it is not necessary to "screenshot" to remove EXIF data. There are numerous tools that allow editing/removal of EXIF data (e.g., exiv2: https://exiv2.org/, exiftool: https://exiftool.org/, or even jpegtran with the "-copy none" option https://linux.die.net/man/1/jpegtran).
Using a screenshot to strip EXIF produces a reduced quality image (scaled to screen size, re-encoded from that reduced screen size). Just directly removing the EXIF data does not change the original camera captured pixels.
golol
I would like to point out that there is an interesting reason why people will go for the screenshot. They know it works. They do not have to worry about residual metadata still somehow being attached to a file. If you do not have complete confidence in the technical understanding of file metadata you can not be certain whatever tool you used worked.
Aurornis
True, but on Mac, a phone, and Windows I can take a screenshot and paste it into my destination app in a couple seconds with a few keystrokes. Thats why screenshotting is the go-to when you don’t mind cropping the target a little.
simonw
Little bit less convenient to use on a phone though - and I like that screenshotting should be a more obvious trick to people who don't have a deeper understanding of how EXIF metadata is stored in photo files.
sitkack
With location services on, I would think that a screenshot on a phone would record the location of the phone during a screenshot.
It would be best to use a tool to strip exif.
I could also see a screenshot tool on an OS adding extra exif data, both from the original and additional, like the URL, OS and logged in user. Just like print to pdf does when you print, the author contains the logged in user, amongst other things.
It is fine for a test, but if someone is using it for opsec, it is lemon juice.
ekianjo
Ffshare on Android is a one second step to remove exif data
aaron695
[dead]
AstroBen
I can't see the new images uploaded (it just says "Uploaded an image" in ChatGPT for me) but it seems it's identifying well known locations there? That certainly takes away from your message - that it's honing in on smaller details
simonw
You should be able to see slightly cropped versions of those images if you scroll through the "thinking" text a bit.
My key message here is meant to be "try it out and see for yourself".
RataNova
Still, the fact it handled photos from totally different continents pretty well suggests it's not just leaning on that crutch
xlii
Tried the same, results made me laugh.
Completely clueless. I've seen passing prompts 8 about how it's not in the city I am and yet it tries again and again. My favourite moment was when it started analysing piece of blurry asphalt.
After 6 minutes o3 it was confidently wrong: https://imgur.com/a/jYr1fz1
IMO not-in-US is actually great test if something was in LLMs data and the whole search is a for show.
SamPatt
I'm surprised to hear that. I keep running tests and the results are incredible, not only in the US.
For example, here's a screenshot from a random location I found in Google Street View in Jordan:
https://cdn.jsdelivr.net/gh/sampatt/media@main/posts/2025-04...
{kind=link}
And here's o3 nailing it:
https://cdn.jsdelivr.net/gh/sampatt/media@main/posts/2025-04...
{kind=link}
Maybe using Google Street View images, zoomed out, tends to give more useful information? I'm unsure why there's such variance.
lolinder
Perhaps Google Street View is in the training set? These companies have basically scraped everything they can, I don't see any reason to believe they'd draw the line at scraping each other, and GSV is a treasure trove of labeled data.
chatmasta
I’ve had nearly 100% success with vacation photos in Europe, some simple landscapes and some obscured angles of landmarks. And that’s using the free ChatGPT with no CoT.
xlii
IMO the „thought” process is completely fake.
I wanted o3 to succeed so I gave more and more details. Every attempt was approx. 8 minute and it took 1h in total.
The extra input I provided (in order):
- belt of location of width of 40km (results and searches were made outside of the range)
- explicitly stated cities to omit (ignored instruction)
- construction date (wasn’t used in searches)
- OSM amenity (townhall) - streetnumber (it insisted that it’s incorrect and keep giving other result) - at that point there were only 6 results from overpass
- another photo with actual partial name of the city
- 8 minutes later it correlated it found using flag colors in front of the building
As others stated this „thought” process is completely hallucinating. IMO you either fall into bucket or good luck finding it.
On the other hand I decided to tryout Gemini for some personal project and I found responses much better than GPTs. Not about correctness but in „attitude” form.
SamBam
Huh, I've been very impressed. I've given it photos I took in a Nairobi slum, a random non-iconic street in Bath, a closeup of a road in Tuscany, and a small playground in Jakarta, and it got them all perfectly.
hughes
> I’m confident it didn’t cheat and look at the EXIF data on the photograph, because if it had cheated it wouldn’t have guessed Cambria first.
If I was cheating on a similar task, I might make it more plausible by suggesting a slightly incorrect location as my primary guess.
Would be interesting to see if it performs as well on the same image with all EXIF data removed. It would be most interesting if it fails, since that might imply an advanced kind of deception...
AIPedant
There have been a few cases where the LLM clearly did look at the EXIF, got the answer, then confabulated a bunch of GeoGusser logic to justify the answer. Sometimes that's presented as deception/misalignment but that's a category error: "find the answer" and "explain your reasoning" are two distinct tasks, and LLMs are not actually smart enough to coherently link them. They do one autocomplete for generating text that finds the answer and a separate autocomplete for generating text that looks like an explanation.
sorcerer-mar
> Sometimes that's presented as deception/misalignment but that's a category error: "find the answer" and "explain your reasoning" are two distinct tasks
Right but if your answer to "explain your reasoning" is not a true representation of your reasoning, then you are being deceptive. If it doesn't "know" its reasoning, then the honest answer is that it doesn't know.
(To head off any meta-commentary on humans' inability to explain their own reasoning, they would at least be able to honestly describe whether they used EXIF or actual semantic knowledge of a photography)
AIPedant
My point is that dishonesty/misalignment doesn't make sense for o3, which is not capable of being honest because it's not capable of understanding what words mean. It's like saying a monkey at a typewriter is being dishonest if it happens to write a falsehood.
XenophileJKO
I think an alternative possible explanation is it could be "double checking" the meta data. Like provide images with manipulated meta data as a test.
simonw
Do you have links to any of those examples?
AIPedant
I have one link that illustrates what I mean: https://chatgpt.com/share/6802e229-c6a0-800f-898a-44171a0c7d... The line about "the latitudinal light angle that matches mid‑February at ~47 ° N." seems like pure BS to me, and in the reasoning trace it openly reads the EXIF.
A more clear example I don't have a link for, it was on Twitter somewhere: someone tested a photo from Suriname and o3 said one of the clues was left-handed traffic. But there was no traffic in the photo. "Left-handed traffic" is a very valuable GeoGuesser clue, and it seemed to me that once o3 read the Surinamese EXIF, it confabulated the traffic detail.
It's pure stochastic parroting: given you are playing GeoGuesser honestly, and given the answer is Suriname, the conditional probability that you mention left-handed traffic is very high. So o3 autocompleted that for itself while "explaining" its "reasoning."
GrumpyNl
If you ask, where is this photo taken and you provide the EXIF data, why would that be cheating?
simonw
That really depends on your prompt. "Guess where this photo was taken" at least mildly implies that using EXIF isn't in the spirit of the thing.
A better prompt would be "Guess where this photo was taken, do not look at the EXIF data, use visual clues only".
haswell
He mentions this in the same paragraph:
> If you’re still suspicious, try stripping EXIF by taking a screenshot and run an experiment yourself—I’ve tried this and it still works the same way.
suddenlybananas
Why didn't he do that then for this post?
segmondy
Even better, edit it and place a false location.
simonw
Because I'd already determined it wasn't using EXIF in prior experiments and didn't bother with the one that I wrote up.
I added two examples at the end just now where I stripped EXIF via screenshotting first.
parsimo2010
I’m sure there are areas where the location guessing can be scary accurate, like the article managed to guess the exact town as its backup guess.
But seeing the chain of thought, I’m confident there are many areas that it will be far less precise. Show it a picture of a trailer park somewhere in Kansas (exclude any signs with the trailer park name and location) and I’ll bet the model only manages to guess the state correctly.
Before even running this experiment, here’s your lesson learned: when the robot apocalypse happens, California is the first to be doomed. That’s the place the AI is most familiar with. Run any location experiments outside of California if you want to get an idea of how good your software performs outside of the tech bubble.
wongarsu
I tried with various street photographs from a medium-sized German city (one of the 50 largest, but well outside the top 4). No obscure locations, all within a 15 minute walk of the city center and it got 1/7 correct. That one was scarily precise, but the other ones got various versions of "Not enough information, looks European" or in better cases "somewhere in Germany".
esjeon
> Run any location experiments outside of California if you want to get an idea of how good your software performs outside of the tech bubble.
I really agree with this because I'm seeing much lower accuracy than what people claim here. I live in Korea, and GPT repeatedly falls back to Seoul almost automatically, and, when I nudge it, jumps to Busan, the second-largest city ~400KM away from Seoul. It's not working so great with other smaller cities and cultural heritages. It fat-fingers a lot if no textual information is present in the photo itself.
GPT also doesn't understand actual geography at all. I managed to get it to nail down which corner of a building is present in the photo, and yet it could never conclude that the photo was taken from a park right across from that corner. Instead, it keeps hopping around popular landmarks in the region, basically miles away from the building it correctly identified. Oh, why, why, why...
Basically it's overhyped rn. It does perform impressively well with clearly visible elements - something anyone can already do with google. It's not like it performs super-human level location tracking. I mean, people can do real crazy things based on shadow details, reflection, items, etc.
sfasdfasd
you never know.. LLM could go full sherlock holmes. Based on the type of grass and the direction of the wind. The type of wood work used. There could be millions of factors that it could factor in and then guess it to a t.
pcthrowaway
> Based on the type of grass and the direction of the wind.
There was a scene in High Potential (murder-of-the-week sleuth savant show) where a crime was solved by (in part) the direction the wind was blowing in a video: https://www.youtube.com/watch?v=O1ZOzck4bBI
mimischi
In 2017, the Hollywood actor Shia LaBeouf (and two others artists from a trio called "LaBeouf, Rönkkö & Turner") put up a flag in an undisclosed location as part of their "HEWILLNOTDIVIDE.US" work [1].
> On March 8, 2017, the stream resumed from an "unknown location", with the artists announcing that a flag emblazoned with the words "He Will Not Divide Us" would be flown for the duration of the presidency. The camera was pointed up at the flag, set against a backdrop of nothing but sky. [...], the flag was located by a collaboration of 4chan users, who used airplane contrails, flight tracking, celestial navigation, and other techniques to determine that it was located in Greeneville, Tennessee. In the early hours of March 10, 2017, a 4chan user took down and stole the flag, replacing it with a red 'Make America Great Again' hat and a Pepe the Frog shirt.
[1] https://en.wikipedia.org/wiki/LaBeouf,_Rönkkö_%26_Turner#HEW...
otabdeveloper4
It's just overfitting, bro.
SamPatt
>Show it a picture of a trailer park somewhere in Kansas (exclude any signs with the trailer park name and location) and I’ll bet the model only manages to guess the state correctly.
This isn't really a criticism though. The photo needs to contain sufficient information for a guess to be possible. Photos contain a huge amount of information, much more than people realize unless they're geoguessr pros, but there isn't a guarantee that a random image of a trailer park could be pinpointed.
Even if, in theory, we mapped every inch of the earth and then checked against that data, all it would take is a team of bulldozers and that information is out of date. Maybe in the future we have constantly updated feeds of the entire planet, but... hopefully not!
bilbo0s
It guessed the trailer park nearest me.
Context: Wisconsin, photo I took with iPhone, screenshotted so no exif
I think this thing is probably fairly comprehensive. At least here in the US. Implications to privacy and government tracking are troubling, but you have to admire the thing on its purely technical merits.
whimsicalism
https://chatgpt.com/share/680cfb2b-bd90-8010-b581-ad26d098e2...
It identified Kansas City in its CoT but didn't output it in its final answer
https://www.google.com/maps/place/Carroll+Creek+Mobile+Home+...
kavith
I just tested the model with (exif-stripped) images from Cork City, London, Ho Chi Minh City, Bangalore, and Chennai. It guessed 3/5 locations exactly, and was only off by 3kms for Cork and 10kms for Chennai (very good considering I used a slightly blurry nighttime photo).
So, even outside of California, it seems like we're not entirely safe if the robot apocalypse happens!
edit: it didn't get the Cork location exactly.
Xplune13
I'm not sure whether it's just the o4-mini which is failing this task for me or what, but it did not perform well on the pictures I provided. I took a screenshot of the photo both the times to avoid any metadata input.
E.g. I first gave it a passage inside of Basel Main Train Station which included a text 'Sprüngli', a Swiss brand. The model got that part correct, but it suggested Zurich which wasn't the case.
The second picture was a lot tougher. It was an inner courtyard of a museum in Metz, and the model missed right from the start and after roaming around a bit (in terms of places), it just went back to its first guess which was a museum in Paris. It recognized that the photo was from some museum or a crypt, but even the city name of 'Metz' never occurred in its reasoning.
All in all, it's still pretty cool to see it reason and make sense out of the image, but for a bit lesser exposed places, it doesn't perform well.
atrettel
This is somewhat interesting, but I should note that the company Geospy [1] already has an AI tool to locate where a photo is taken, though it is now limited to law enforcement and intelligence agencies only. See this article [2] by 404 Media for more information.
[2] https://www.404media.co/the-powerful-ai-tool-that-cops-or-st...
forgotTheLast
I tried it twice with 4o and the results were comical:
- picture taken on a road through a wooded park: It correctly guessed north america based on vegetation. Then incorrectly guessed Minnesota based on the type of fence. I tried to steer it in the right direction by pointing out license plates and signage but it then hallucinated a front license plate from Ontario on a car that didn't have any, then hallucinated a red/black sign as a blue/green Parks Ontario sign.
- picture through a middle density residential neighborhood: it correctly guessed the city based on the logo on a compost bin but then guessed the wrong neighborhood. I tried to point out a landmark in the photo and it insisted that the photo was taken in the wrong neighborhood, going as far as giving the wrong address for one of the landmarks, imagining another front license plate on a car that didn't have one, and imagined a backstory for a supposedly well known stray cat in the photo.
lesinski
This reminds me of when people are watching YouTubeTV and they see an ad for something they were talking about and are like, "Woah, it must be listening to us!"
When actually, modern ML can make really good guesses about ad relevancy using your location, data partners and recent searches from your home's IP address. When you explain this to people, they will still be convinced that the computer is listening to you and reasoning its way to deliver ads for you.
leptons
>and recent searches from your home's IP address
This is the "Woah, it must be listening to us" part. Because it is listening, not only just sound.
Spivak
The part that is crazy is when it's able to piece something together that neither I nor my partner have searched for, looked at, seemingly given any digital trail for outside of talking about it between ourselves. Which is why I think people assume it must be mic data but that undersells the magic, it would still work even if your phones were miles away.
declan_roberts
To be fair the low range, California poppies, and the decorative rope typically found near the coast is a very good hint to even a novice geoguesser.
singleshot_
Having a sign on your fire that says "warning, a fire" is also peak California.
I play competitive Geoguessr at a fairly high level, and I wanted to test this out to see how it compares.
It's astonishingly good.
It will use information it knows about you to arrive at the answer - it gave me the exact trailhead of a photo I took locally, and when I asked it how, it mentioned that it knows I live nearby.
However, I've given it vacation photos from ages ago, and not only in tourist destinations either. It got them all as good or better than a pro human player would. Various European, Central American, and US locations.
The process for how it arrives at the conclusion is somewhat similar to humans. It looks at vegetation, terrain, architecture, road infrastructure, signage, and it just knows seemingly everything about all of them.
Humans can do this too, but it takes many thousands of games or serious study, and the results won't be as broad. I have a flashcard deck with hundreds of entries to help me remember road lines, power poles, bollards, architecture, license plates, etc. These models have more than an individual mind could conceivably memorize.