4o Image Generation
628 comments
·March 25, 2025blixt
Taek
> What's important about this new type of image generation that's happening with tokens rather than with diffusion, is that this is effectively reasoning in pixel space.
I do not think that this is correct. Prior to this release, 4o would generate images by calling out to a fully external model (DALL-E). After this release, 4o generates images by calling out to a multi-modal model that was trained alongside it.
You can ask 4o about this yourself. Here's what it said to me:
"So while I’m deeply multimodal in cognition (understanding and coordinating text + image), image generation is handled by a linked latent diffusion model, not an end-to-end token-unified architecture."
noosphr
>You can ask 4o about this yourself. Here's what it said to me:
>"So while I’m deeply multimodal in cognition (understanding and coordinating text + image), image generation is handled by a linked latent diffusion model, not an end-to-end token-unified architecture."
Models don't know anything about themselves. I have no idea why people keep doing this and expecting it to know anything more than a random con artist on the street.
mgraczyk
This is overly cynical. Models typically do know what tools they have access to because the tool descriptions are in the prompt. Asking a model which tools it has is a perfectly reasonable way of learning what is effectively the content of the prompt.
Of course the model may hallucinate, but in this case it takes a few clicks in the dev tools to verify that this is not the case.
Xmd5a
>Models don't know anything about themselves.
They can. Fine tune them on documents describing their identity, capabilities and background. Deepseek v3 used to present itself as ChatGPT. Not anymore.
>Like other AI models, I’m trained on diverse, legally compliant data sources, but not on proprietary outputs from models like ChatGPT-4. DeepSeek adheres to strict ethical and legal standards in AI development.
rickyhatespeas
You're incorrect. 4o was not trained on knowledge of itself so literally can't tell you that. What 4o is doing isn't even new either, Gemini 2.0 has the same capability.
teaearlgraycold
The system prompt includes instructions on how to use tools like image generation. From that it could infer what the GP posted.
Taek
Can you provide a link or screenshot that directly backs this up?
CooCooCaCha
Models are famously good at understanding themselves.
uh_uh
I hope you're joking. Sometimes they don't even know which company developed them. E.g. DeepSeek was claiming it was developed by OpenAI.
mgraczyk
I think this is actually correct even if the evidence is not right.
See this chat for example:
https://chatgpt.com/share/67e355df-9f60-8000-8f36-874f8c9a08...
low_tech_love
Honest question, do you believe something just because the bot tells you that?
hansmayer
A lot of convoluted explanations about something we don't even know if it really works all the time. I feel like in the third year of LLM-Hype and after reminde-me-how-many billions of dollars burned, we should by now not have to imagine what 'might happen' down to road, it should have been happening already. The use-case you are describing, sure sounds very interesting, until I remember asking asked Copilot for a simple scaffolding structure in React, and it spat out something which lacked half of imports and proper visual alignments. A few years ago I was excited about the possibility of removing all the scaffolding and templating work so we can write the cool parts, but they cannot even do that right. It's actually a step back compared to automatic code generators of the past, because those at least produced reproducible results every single time you used them. But hey sure, the next generation of "AI" (it's not really AI) will probably solve it.
pdntspa
That scene is changing so quickly that you will want to try again right now if you can.
While LLM code generation is very much still a mixed bag, it has been a significant accelerator in my own productivity, and for the most part all I am using is o1 (via the openAI website), deepseek, and jetbrains' AI service (Copilot clone). I'm eager to play with some of the other tooling available to VS Code users (such as cline)
I don't know why everyone is so eager to "get to the fun stuff". Dev is supposed to be boring. If you don't like it maybe you should be doing something else.
hansmayer
I mean I literally "tried it again" this morning, as a paying Copilot customer of 12 months, to the result I already described. And I do not want to "try it" - based on fluffy promises we've been hearing, it should "just work". Are you old enough to remember that phrase? It was a motto introduced by an engineering legend whose devices you're likely using every day. The reason why "everyone", including myself with 20+ years of experience is looking to do not "fun stuff" (please don't shove words into my mouth), but cool stuff (=hard problems) is that it produces an intrinsic sense of satisfaction, which in turn creates motivation to do more and eventually even produces wider gain for the society. Some of us went into engineering because of passion you know. We're not all former copy-writers retrained to be "frontend developers" for a higher salary, who are eager to push around CSS boxes. That's important work too, but I've definitely solved harder problems in my career. If it's boring for you and you think it's how it should be, then you are definitely doing it for the wrong reasons (I am assuming escaping a less profitable career).
mckngbrd
Consider using a better AI IDE platform than Copilot ... cursor, windsurf, cline, all great options that do much better than what you're describing. The underlying LLM capabilities also have advanced quite a bit in the past year.
hansmayer
Well I do not really use it that much to actually care, and don't really depend on AI, thankfully. If they did not mess up the google search, we wouldnt even need that crap at all. But that's not the main point. Even if I switched to cursor or windsurf - aren't they all using one of the same LLMs? (ChatGPT,Claude, whatever..). The issue is that the underlying general approach will never be accurate enough. There is a reason most of successful technologies lift off quickly and those not successful also die very quickly. This is a tech propped up by a lot of VC money for now, but at some point, even the richest of the rich VCs will have trouble explaining spending 500B dollars in total, to get something like 15B revenue (not even profit). And don't even get me started on Altman's trillion-fantasies...
sureIy
> truly generative UI, where the model produces the next frame of the app
Please sir step away from the keyboard now!
That is an absurd proposition and I hope I never get to use an app that dreams of the next frame. Apps are buggy as they are, I don't need every single action to be interpreted by LLM.
An existing example of this is that AI Minecraft demo and it's a literal nightmare.
blixt
This argument could be made for every level of abstraction we've added to software so far... yet here we are commenting about it from our buggy apps!
outworlder
Yeah, but the abstractions have been useful so far. The main advantage of our current buggy apps is that if it is buggy today, it will be exactly as buggy tomorrow. Conversely, if it is not currently buggy, it will behave the same way tomorrow.
I don't want an app that either works or does not work depending on the RNG seed, prompt and even data that's fed to it.
That's even ignoring all the absurd computing power that would be required.
FridgeSeal
Please, I don’t need my software experience to get any _worse_. It’s already a shitshow.
gspr
> This argument could be made for every level of abstraction we've added to software so far... yet here we are commenting about it from our buggy apps!
No. Not at all. Those levels of abstractions – whether good, bad, everything in between – were fully understood through-and-through by humans. Having an LLM somewhere in the stack of abstractions is radically different, and radically stupid.
koliber
First it will dream up the interaction frame by frame. Next, to improve efficiency, it will cache those interaction representations. What better way to do that than through a code representation.
While I think current AI can’t come close to anything remotely usable, this is a plausible direction for the future. Like you, I shudder.
velcrovan
I guess you have not heard that NVidia is generating frames with AI on their GPUs now: https://www.nvidia.com/en-us/geforce/news/dlss4-multi-frame-...
> “DLSS Multi Frame Generation generates up to three additional frames per traditionally rendered frame, working in unison with the complete suite of DLSS technologies to multiply frame rates by up to 8X over traditional brute-force rendering. This massive performance improvement on GeForce RTX 5090 graphics cards unlocks stunning 4K 240 FPS fully ray-traced gaming.”
jjbinx007
It still can't generate a full glass of wine. Even in follow up questions it failed to manipulate the image correctly.
meeton
https://i.imgur.com/xsFKqsI.png
{kind=link}
"Draw a picture of a full glass of wine, ie a wine glass which is full to the brim with red wine and almost at the point of spilling over... Zoom out to show the full wine glass, and add a caption to the top which says "HELL YEAH". Keep the wine level of the glass exactly the same."
cruffle_duffle
Maybe the "HELL YEAH" added a "party implication" which shifted it's "thinking" into just correct enough latent space that it was able to actually hunt down some image somewhere in its training data of a truly full glass of wine.
I almost wonder if prompting it "similar to a full glass of beer" would get it shifted just enough.
Stevvo
Can't replicate. Maybe the rollout is staggered? Using Plus from Europe, it's consistently giving me a half full glass.
eitland
Most interesting thing to me is the spelling is correct.
I'm not a heavy user of AI or image generation in general, so is this also part of the new release or has this been fixed silently since last I tried?
dghlsakjg
The head of foam on that glass of wine is perfect!
yusufozkan
Are you sure you are using the new 4o image generation?
minimaxir
That is an unexpectedly literal definition of "full glass".
Imustaskforhelp
Looks amazing,can you please also create a unconventional image like the clock at 2:35 , I tried it something like this with gemini when some redditor asked it and it failed so wondering if 4o does do it
stevesearer
Can you do this with the prompt of a cow jumping over the moon?
I can’t ever seem to get it to make the cow appear to be above the moon. Always literally covering it or to the side etc.
null
jasonjmcghee
I don't buy the meme or w/e that they can't produce an image with the full glass of wine. Just takes a little prompt engineering.
Using Dall-e / old model without too much effort (I'd call this "full".)
ASalazarMX
The true test was "full to the brim", as in almost overflowing.
sfjailbird
They're glass-half-full type models.
blixt
Yeah, it seems like somewhere in the semantic space (which then gets turned into a high resolution image using a specialized model probably) there is not enough space to hold all this kind of information. It becomes really obvious when you try to meaningfully modify a photo of yourself, it will lose your identity.
For Gemini it seems to me there's some kind of "retain old pixels" support in these models since simple image edits just look like a passthrough, in which case they do maintain your identity.
tobr
Also still seems to have a hard time consistently drawing pentagons. But at least it does some of the time, which is an improvement since last time I tried, when it would only ever draw hexagons.
HellDunkel
I think it is not the AI but you who is wrong here. A full glass of wine is filled only up to the point of max radius so that the surface to air is maxed an the wine can breathe. This is what we taught the AI to consider „a full glass of wine“ and it perfectly gets it right.
theptip
Nope, it can.
Got it in two requests, https://chatgpt.com/share/67e41576-8840-8006-836b-f7358af494... for the prompts.
xg15
> What's important about this new type of image generation that's happening with tokens rather than with diffusion
That sounds really interesting. Are there any write-ups how exactly this works?
lyu07282
Would be interested to know as well. As far as I know there is no public information about how this works exactly. This is all I could find:
> The system uses an autoregressive approach — generating images sequentially from left to right and top to bottom, similar to how text is written — rather than the diffusion model technique used by most image generators (like DALL-E) that create the entire image at once. Goh speculates that this technical difference could be what gives Images in ChatGPT better text rendering and binding capabilities.
https://www.theverge.com/openai/635118/chatgpt-sora-ai-image...
treis
I wonder how it'd work if the layers were more physical based. In other words something like rough 3d shape -> details -> color -> perspective -> lighting.
Also wonder if you'd get better results in generating something like blender files and using its engine to render the result.
astrange
DALL-E was an autoregressive encoder; it's 2 and 3 that used diffusion and were much less intelligent as a result.
fpgaminer
There are a few different approaches. Meta documents at least one approach quite well in one of their llama papers.
The general gist is that you have some kind of adapter layers/model that can take an image and encode it into tokens. You then train the model on a dataset that has interleaved text and images. Could be webpages, where images occur in-between blocks of text, chat logs where people send text messages and images back and forth, etc.
The LLM gets trained more-or-less like normal, predicting next token probabilities with minor adjustments for the image tokens depending on the exact architecture. Some approaches have the image generation be a separate "path" through the LLM, where a lot of weights are shared but some image token specific weights are activated. Some approaches do just next token prediction, others have the LLM predict the entire image at once.
As for encoding-decoding, some research has used things as simple as Stable Diffusion's VAE to encode the image, split up the output, and do a simple projection into token space. Others have used raw pixels. But I think the more common approach is to have a dedicated model trained at the same time that learns to encode and decode images to and from token space.
For the latter approach, this can be a simple model, or it can be a diffusion model. For encoding you do something like a ViT. For decoding you train a diffusion model conditioned on the tokens, throughout the training of the LLM.
For the diffusion approach, you'd usually do post-training on the diffusion decoder to shrink down the number of diffusion steps needed.
The real crutch of these models is the dataset. Pretraining on the internet is not bad, since there's often good correlation between the text and the images. But there's not really good instruction datasets for this. Like, "here's an image, draw it like a comic book" type stuff. Given OpenAI's approach in the past, they may have just bruteforced the dataset using lots of human workers. That seems to be the most likely approach anyway, since no public vision models are quite good enough to do extensive RL against.
And as for OpenAI's architecture here, we can only speculate. The "loading from top to be from a blurry image" is either a direct result of their architecture or a gimmick to slow down requests. If the former, it means they are able to get a low resolution version of the image quickly, and then slowly generate the higher resolution "in order." Since it's top-to-bottom that implies token-by-token decoding. My _guess_ is that the LLM's image token predictions are only "good enough." So they have a small, quick decoder take those and generate a very low resolution base image. Then they run a stronger decoding model, likely a token-by-token diffusion model. It takes as condition the image tokens and the low resolution image, and diffuses the first patch of the image. Then it takes as condition the same plus the decoded patch, and diffuses the next patch. And so forth.
A mixture of approaches like that allows the LLM to be truly multi-modal without the image tokens being too expensive, and the token-by-token diffusion approach helps offset memory cost of diffusing the whole image.
I don't recall if I've seen token-by-token diffusion in a published paper, but it's feasible and is the best guess I have given the information we can see.
EDIT: I should note, I've been "fooled" in the past by OpenAI's API. When o* models first came out, they all behaved as if the output were generated "all at once." There was no streaming, and in the chat client the response would just show up once reasoning was done. This led me to believe they were doing an approach where the reasoning model would generate a response and refine it as it reasoned. But that's clearly not the case, since they enabled streaming :P So take my guesses with a huge grain of salt.
zaptrem
Token by token diffusion was done by MAR https://arxiv.org/abs/2406.11838 and Fluid (scaled up MAR) https://arxiv.org/abs/2410.13863
When you randomly pick the locations they found it worked okay, but doing it in raster order (left to right, top to bottom) they found it didn't work as well. We tried it for music and found it was vulnerable to compounding error and lots of oddness relating to the fragility of continuous space CFG.
og_kalu
There is a more recent approach to auto-regressive image generation. Rather than predicting the next patch at the target resolution one by one, it predicts the next resolution. That is, the image at a small resolution followed by the image at a higher resolution and so on.
snickell
> truly generative UI, where the model produces the next frame of the app
I built this exact thing last month, demo: https://universal.oroborus.org (not viable on phone for this demo, fine on tablet or computer)
Also see discussion and code at: http://github.com/snickell/universal
I wasn't really planning to share/release it today, but, heck, why not.
I started with bitmap-style generative image models, but because they are still pretty bad at text (even this, although it’s dramatically better), for early-2025 it’s generating vector graphics instead. Each frame is an LLM response, either as an svg or static html/css. But all computation and transformation is done by the LLM. No code/js as an intermediary. You click, it tells the LLM where you clicked, the LLM hallucinates the next frame as another svg/static-html.
If it ran 50x faster it’d be an absolutely jaw dropping demo. Unlike "LLMs write code", this has depth. Like all programming, the "LLMs write code" model requires the programmer or LLM to anticipate every condition in advance. This makes LLM written "vibe coded" apps either gigantic (and the llm falls apart) or shallow.
In contrast, as you use universal, you can add or invent features ranging from small to big, and it will fill in the blanks on demand, fairly intelligently. If you don't like what it did, you can critique it, and the next frame improves.
Its agonizingly slow in 2025, but much smarter and in weird ways less error prone than using the LLM to generate code that you then run: just run computation via the LLM itself.
You can build pretty unbelievable things (with hallucinated state, granted) with a few descriptive sentences, far exceeding the capabilities you can “vibe code” with the description. And it never gets lost in its rats nest of self generated garbage code because… there is no code to in.
Code is medium with a surprisingly strong grain. This demo is slow, but SO much more flexible and personally adaptable than anything I’ve used where the logic is implemented cia a programming language.
I don’t love this as a programmer, but my own use of the demo makes me confident that programming languages as a category will have a shelf life if LLM hardware gets fast, cheap and energy efficient.
I suspect LLMs will generate not programming language code, but direct wasm or just machine code on the fly for things that need faster traction than they can draw a frame, but core logic will move out of programming languages (not even llm written code). Maybe similar to the way we bind to low level fast languages but a huge percentage of “business” logic is written in relatively slower languages.
FYI, I may not be able to afford the credits if too many people visit, I put a a $1000 of credits on this, we'll see if that lasts. This is claude 3.7, I tried everything else, a claude had the visual intelligence today. IMO this is a much more compelling glance at the future than coding models. Unfortunately, generating an SVG per click is pricey, each click/frame costs me about $0.05. I’ll fund this as far as I can so folks can play with it.
Anthropic? You there? Wanna throw some credits at an open source project doing something that literally only works on claude today? Not just better, but “only Claude 3.7 can show this future today?”. I’d love for lots more people to see the demo, but I really could use an in-kind credit donation to make this viable. If anyone at anthropic is inspired and wants to hook me up: snickell@alumni.stanford.edu. Very happy to rep Claude 3.7 even more than I already do.
I think it’s great advertising for Claude. I believe the reason Claude seems to do SO much better at this task is, one it shows far greater spatial intelligence, and two, I distract they are the only state of the art model intentionally training on SVG.
numlocked
I’m a bit late here - but I’m the COO of OpenRouter and would love to help out with some additional credits and share the project. It’s very cool and more people could be able to check it out. Send me a note. My email is cc at OpenRouter.ai
snickell
wow, that would be amazing, sending you an email.
I don't think the project would have gotten this far without openrouter (because: how else would you sanely test on 20+ models to be able to find the only one that actually worked?). Without openrouter, I think I would have given up and thought "this idea is too early for even a demo", but it was easy enough to keep trying models that I kept going until Claude 3.7 popped up.
blixt
This is super cool! I think new kinds of experiences can be built with infinite generative UIs. Obviously there will need to be good memory capabilities, maybe through tool use.
If you end up taking this further and self hosting a model you might actually achieve a way faster “frame rate” with speculative decoding since I imagine many frames will reuse content from the last. Or maybe a DSL that allows big operations with little text. E.g. if it generates HTML/SVG today then use HAML/Slim/Pug: https://chatgpt.com/share/67e3a633-e834-8003-b301-7776f76e09...
snickell
What I'm currently doing is caveman: I ask the LLM to attach a unique id= to every element, and I gave it an attribute (data-use-cached) it can use to mark "the contents of this element should be loaded from the preivous frame": https://github.com/snickell/universal/blob/47c5b5920db5b2082...
For example, this specifies that #my-div should be replaced with the value from the previous frame (which itself might have been cached): <div id="my-div" data-use-cached></div>
This lowers the render time /substantially/, for simple changes like "clicked here, pop-open a menu" it can do it in 10s, vs a full frame render which might be 2 minutes (obviously varies on how much is on the screen!).
I think using HAML etc is an interesting idea, thanks for suggesting it, that might be something I'll experiment with.
The challenge I'm finding is that "fancy" also has a way of confusing the LLM. E.g. I originally had the LLM produce literal unified diffs between frames. I reasoned it had seem plenty of diffs of HTML in its training data set. It could actually do this, BUT image quality and intelligence were notably affected.
Part of the problem is that at the moment (well 1mo ago when I last benchmarked), only Claude is "past the bar" for being able to do this particular task, for whatever reason. Gemini Flash is the second closest. Everything else (including 4o, 4.5, o1, deepseek, etc) are total wipeouts.
What would be really amazing is if say Llama 4 turns out to be good in the visual domain the way claude is, and you can run it on one of the LLM-on-silicon vendors (cerebrus.ai, grok, etc) to get 10x the token rate.
LMK if you have other ideas, thanks for thinking about this and taking a look!
pingou
Wonderful, good job! Reminds me of https://arstechnica.com/information-technology/2022/12/opena...
Retr0id
Do you have any demo videos?
snickell
No, I wasn't planning to post this for a couple weeks, but I saw the comment and was like "eh, why not?".
You can watch "sped up" past sessions by other people who used this demo here, which is kind of like a demo video: https://universal.oroborus.org/gallery
But the gallery feature isn't really there today, it shows all the "one-click and bounce sessions", and its hard to find signal in the noise.
I'll probably submit a "Show HN" when I have the gallery more together, and I think its a great idea to pick a multi-click gallery sequence and upload it as a video.
koliber
It’s like a lucid dream version of using and modifying the software at the same time.
salavador18th
This is so impressive. You are building the future!
nine_k
It also would mean that the model can correctly split the image into layers, or segments, matching the entities described. The low-res layers can then be fed to other image-processing models, which would enhance them and fill in missing small details. The result could be a good-quality animation, for instance, and the "character" layers can even potentially be reusable.
Mond_
Pretty sure the modern Gemini image models can already do token based image generation/editing and are significantly better and faster.
blixt
Yeah Gemini has had this for a few weeks, but much lower resolution. Not saying 4o is perfect, but my first few images with it are much more impressive than my first few images with Gemini.
yieldcrv
weeks, ya'll, weeks!
null
og_kalu
It's faster but it's definitely not better than what's being showcased here. The quality of Flash 2 Image gens are generally pretty meh.
vunderba
Ran through some of my relatively complex prompts combined with using pure text prompts as the de-facto means of making adjustments to the images (in contrast to using something like img2img / inpainting / etc.)
https://mordenstar.com/blog/chatgpt-4o-images
It's definitely impressive though once again fell flat on the ability to render a 9-pointed star.
jimbo_joe
Didn't work for me on the first prompting (got a 10-pointed one), but after sending [this is 10 points, make it 9] it did render a 9-pointed one too
algo_trader
Have u had any luck with engineering/schematics/wireframe diagrams such as [1] ??
[1] https://techcrunch.com/wp-content/uploads/2024/03/pasted-ima...
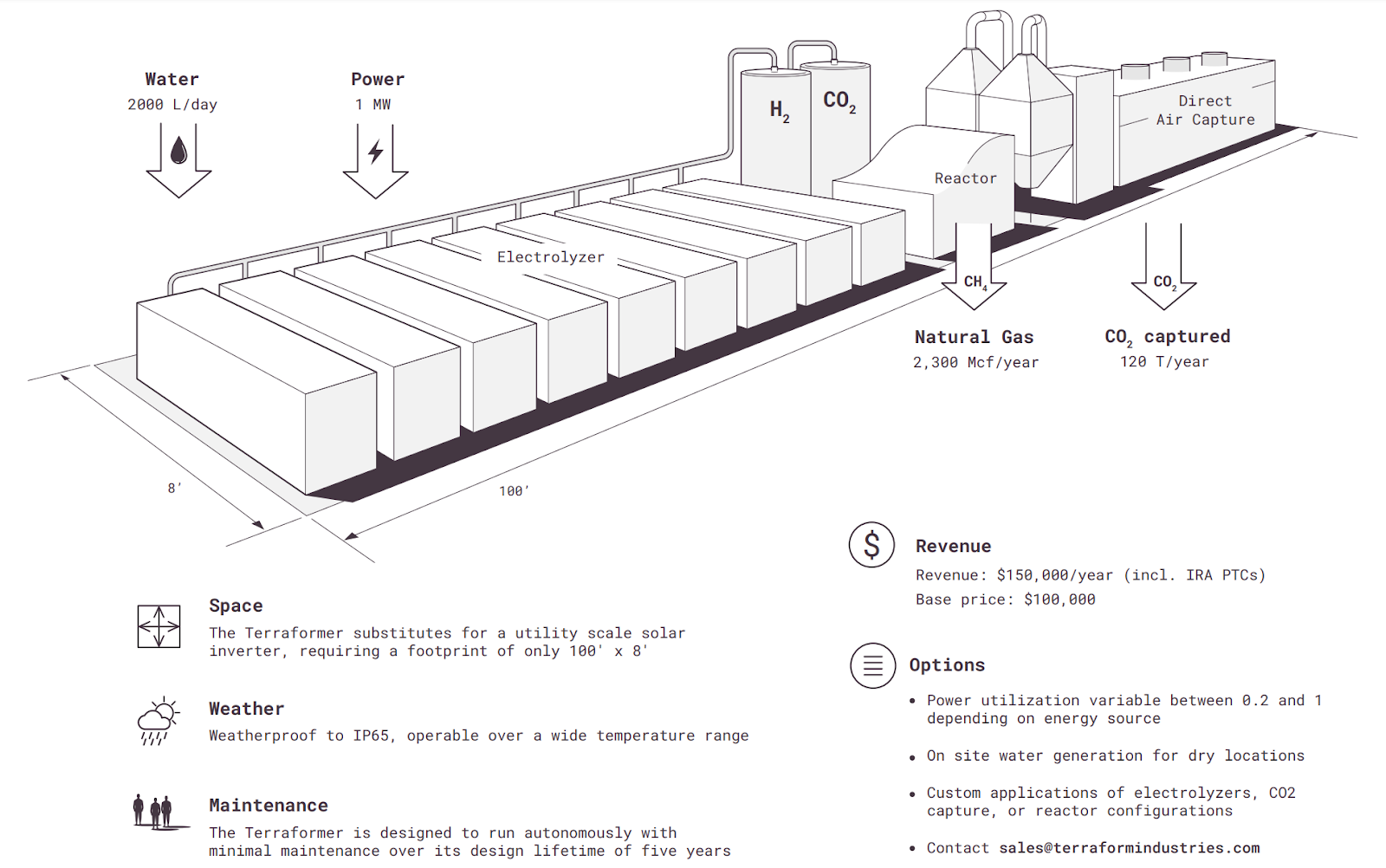{kind=link}
vunderba
Great question. I haven't tested the creation of such an image from scratch, but I did add an adjustment test against that specific text-heavy diagram and I'd say it passed with "flying colors". (pun intended).
randomjoe2
Here's what it created based on a text description of your schematic
{kind=link}
Too
Funny how it changed the spelling in the Magic coloring book. Westher, wntility, substittutesfor, yyears. What's worse is that it removed the CO2 tank and changed some vital numbers, eg 8' to 3', completely altering the meaning of the schematic. Not what i would call passing with flying colors. Still pretty cool as a party trick, like most other AI outputs, useful only with careful review.
therealdrag0
Armless Venus with bread is true art
ttul
Fantastic prompts!
M4v3R
I’ve just tried it and oh wow it’s really good. I managed to create a birthday invitation card for my daughter in basically 1-shot, it nailed exactly the elements and style I wanted. Then I asked to retain everything but tweak the text to add more details about the date, venue etc. And it did. I’m in shock. Previous models would not be even halfway there.
swyx
share prompt minus identifying details?
M4v3R
> Draw a birthday invitation for a 4 year old girl [name here]. It should be whimsical, look like its hand-drawn with little drawings on the sides of stuff like dinosaurs, flowers, hearts, cats. The background should be light and the foreground elements should be red, pink, orange and blue.
Then I asked for some changes:
> That's almost perfect! Retain this style and the elements, but adjust the text to read:
> [refined text]
> And then below it should add the location and date details:
> [location details]
nvalis
If anyone is interested in an example output for this exact initial prompt: https://x.com/0xmetaschool/status/1904804277341839847
yaba_money
just did the same type prompt for my sons birthday. I got all the classic errors. first attempt looked good, but had 2 duplicate lines for date and time and "Roarrr!" (dino theme) had a blurred out "a"
pointed these issues out to give it a second go and got something way worse. This still feels like little more than a fun toy.
swyx
that's lovely thank you. i am not very artistic so having stuff like this to crib is very helpful.
kh_hk
> Introducing 4o Image Generation: [...] our most advanced image generator yet
Then google:
> Gemini 2.5: Our most intelligent AI model
> Introducing Gemini 2.0 | Our most capable AI model yet
I could go on forever. I hope this trend dies and apple starts using something effective so all the other companies can start copying a new lexicon.
roenxi
We're in the middle of a massive and unprecedented boom in AI capabilities. It is hard to be upset about this phrasing - it is literally true and extremely accurate.
kh_hk
If that's so then there's no need to be hyperbolic about it. Why would they publish a model that is not their most advanced model?
roenxi
Most things aren't in a massive boom and most people aren't that involved in AI. This is a rare example of great communication in marketing - they're telling people who might not be across this field what is going on.
> Why would they publish a model that is not their most advanced model?
I dunno, I'm not sitting in the OpenAI meetings. That is why they need to tell us what they are doing - it is easy to imagine them releasing something that isn't their best model ever and so they clarify that this is, in fact, the new hotness.
CamperBob2
(Shrug) It's common for less-than-foundation-level models to be released every so often. This is done in order to provide new options, features, pricing, service levels, APIs or whatever that aren't yet incorporated into the main model, or that are never intended to be.
Just a consequence of how much time and money it takes to train a new foundation model. It's not going to happen every other week. When it does, it is reasonable to announce it with "Announcing our most powerful model yet."
ghshephard
o3 mini wasn't so much a most advanced model, as it was incredibly affordable for the IQ it was presenting at the time. Sometimes it's about efficiency and not being on the frontier.
sebzim4500
They aren't being hyperbolic, they are accurately describing the reason you would use the new product.
And no, not all models are intended to push the frontier in terms of benchmark performance, some are just fast and cheap.
caseyy
This is my latest and most advanced comment yet.
sigmoid10
Has post-Jobs Apple ever come up with anything that would warrant this hope?
internetter
Every iPhone is their best iPhone yet
brianshaler
Even the 18 Pro Max Ultra with Apple Intelligence?
Obligatory Jobs monologue on marketing people:
layer8
Only the September ones. ;)
azinman2
Not wrong though
chrisco255
Apple isn't really the best software company and though they were early to digital assistants with Siri, it seems like they've let it languish. It's almost comical how bad Siri is given the capabilities of modern AI. That being said, Android doesn't really have a great builtin solution for this either.
Apple is more of a hardware company. Still, Cook does have a few big wins under his belt: M-series ARM chips on Macs, Airpods, Apple watch, Apple pay.
pell
Apple silicon chips
kh_hk
No, but I think they stopped with "our most" (since all other brainless corps adopted it) and just connect adjectives with dots.
Hotwheels: Fast. Furious. Spectacular.
sigmoid10
Maybe people also caught up to the fact that the "our most X product" for Apple usually means someone else already did X a long time ago and Apple is merely jumping on the wagon.
magicmicah85
When you keep improving, it's always going to be the best or most: https://www.youtube.com/watch?v=bPkso_6n0vs
Buttons840
Every step of gradient descent is the best model yet!
echoangle
Not if you do gradient descent with momentum.
hombre_fatal
Maybe it’s not useless. 1) it’s only comparing it to their own products and 2) it’s useful to know that the product is the current best in their offering as opposed to a new product that might offer new functionality but isn’t actually their most advanced.
Which is especially relevant when it's not obvious which product is the latest and best just looking at the names. Lots of tech naming fails this test from Xbox (Series X vs S) to OpenAI model names (4o vs o1-pro).
Here they claim 4o is their most capable image generator which is useful info. Especially when multiple models in their dropdown list will generate images for you.
Kiro
What's the problem?
kh_hk
It's a nitpick about the repetitive phrasing for announcements
<Product name>: Our most <superlative> <thing> yet|ever.
rachofsunshine
Speaking as someone who'd love to not speak that way in my own marketing - it's an unfortunate necessity in a world where people will give you literal milliseconds of their time. Marketing isn't there to tell you about the thing, it's there to get you to want to know more about the thing.
echelon
I hate modern marketing trends.
This one isn't even my biggest gripe. If I could eliminate any word from the English language forever, it would be "effortlessly".
null
vagab0nd
This actually makes sense because the versioning is so confusing they could be releasing a lesser/lightweight model for all we know.
minimaxir
OpenAI's livestream of GPT-4o Image Generation shows that it is slowwwwwwwwww (maybe 30 seconds per image, which Sam Altman had to spin "it's slow but the generated images are worth it"). Instead of using a diffusion approach, it appears to be generating the image tokens and decoding them akin to the original DALL-E (https://openai.com/index/dall-e/), which allows for streaming partial generations from top to bottom. In contrast, Google's Gemini can generate images and make edits in seconds.
No API yet, and given the slowness I imagine it will cost much more than the $0.03+/image of competitors.
infecto
As a user, images feel slightly slower but comparable to the previous generation. Given the significant quality improvement, it's a fair trade-off. Overall, it feels snappy, and the value justifies a higher price.
kevmo314
Maybe this is the dialup of the era.
ijidak
Ha. That's a good analogy.
When I first read the parent comment, I thought, maybe this is a long-term architecture concern...
But your message reminded me that we've been here before.
asadm
specially with the slow loading effect it has.
cubefox
LLMs are autoregressive, so they can't be (multi-modality) integrated with diffusion image models, only with autoregressive image models (which generate an image via image tokens). Historically those had lower image fidelity than diffusion models. OpenAI now seems to have solved this problem somehow. More than that, they appear far ahead of any available diffusion model, including Midjourney and Imagen 3.
Gemini "integrates" Imagen 3 (a diffusion model) only via a tool that Gemini calls internally with the relevant prompt. So it's not a true multimodal integration, as it doesn't benefit from the advanced prompt understanding of the LLM.
Edit: Apparently Gemini also has an experimental native image generation ability.
SweetSoftPillow
Gemini added their multimodal Flash model to Google AI Studio some time ago. It does not use Imagen via tool, it's uses native capabilities to manipulate images, and it's free to try.
summerlight
Your understanding seems outdated, I think people are referring Gemini native image generation
argsnd
Is this the same for their gemini-2.0-flash-exp-image-generation model?
cubefox
No that seems to be indeed a native part of the multimodal Gemini model. I didn't know this existed, it's not available in the normal Gemini interface.
johntb86
Meta has experimented with a hybrid mode, where the LLM uses autoregressive mode for text, but within a set of delimiters will switch to diffusion mode to generate images. In principle it's the best of both worlds.
echelon
I expect the Chinese to have an open source answer for this soon.
They haven't been focusing attention on images because the most used image models have been open source. Now they might have a target to beat.
rfoo
ByteDance has been working on autoregressive image generation for a while (see VAR, NeurIPS 2024 best paper). Traditionally they weren't in the open-source gang though.
hansvm
> so they can't be integrated
That's overly pessimistic. Diffusion models take an input and produce an output. It's perfectly possible to auto-regressively analyze everything up to the image, use that context to produce a diffusion image, and incorporate the image into subsequent auto-regressive shenanigans. You'll preserve all the conditional probability factorizations the LLM needs while dropping a diffusion model in the middle.
aurareturn
If you look at the examples given, this is the first time I've felt like AI generated images have passed the uncanny valley.
The results are ground breaking in my opinion. How much longer until an AI can generate 30 successive images together and make an ultra realistic movie?
thehappypm
One day you’ll just give it a script and get a movie out
brrrrrm
a premise*
borgdefenser
[dead]
keeganpoppen
i find this “slow” complaint (/observation— i dont view this comment as a complaint, to be clear) to be quite confusing. slow… compared to what, exactly? you know what is slow? having to prompt and reprompt 15 times to get the stupid model to spell a word correctly and it not only refuses, but is also insistent that it has corrected the error this time. and afaict this is the exact kind of issue this change should address substantially.
im not going to get super hyperbolic and histrionic about “entitlement” and stuff like that, but… literally this technology did not exist until like two years ago, and yet i hear this all the time. “oh this codegen is pretty accurate but it’s slow”, “oh this model is faster and cheaper (oh yeah by the way the results are bad, but hey it’s the cheapest so it’s better)”. like, are we collectively forgetting that the whole point of any of this is correctness and accuracy? am i off-base here?
the value to me of a demonstrably wrong chat completion is essentially zero, and the value of a correct one that anticipates things i hadn’t considered myself is nearly infinite. or, at least, worth much, much more than they are charging, and even _could_ reasonably charge. it’s like people collectively grouse about low quality ai-generated junk out of one side of their mouths, and then complain about how expensive the slop is out of the other side.
hand this tech to someone from 2020 and i guarantee you the last thing you’d hear is that it’s too slow. and how could it be? yeah, everyone should find the best deals / price-value frontier tradeoff for their use case, but, like… what? we are all collectively devaluing that which we lament is being devalued by ai by setting such low standards: ourselves. the crazy thing is that the quickly-generated slop is so bad as to be practically useless, and yet it serves as the basis of comparison for… anything at all. it feels like that “web-scale /dev/null” meme all over again, but for all of human cognition.
null
Taek
> it appears to be generating the image tokens and decoding them akin to the original DALL-E
The animation is a lie. The new 4o with "native" image generating capabilities is a multi-modal model that is connected to a diffusion model. It's not generating images one token at a time, it's calling out to a multi-stage diffusion model that has upscalers.
You can ask 4o about this yourself, it seems to have a strong understanding of how the process works.
low_tech_love
Would it seem otherwise if it was a lie?
Taek
There are many clues to indicate that the animation is a lie. For example, it clearly upscales the image using an external tool after the first image renders. As another example, if you ask the model about the tokens inside of its own context, it can't see any pixel tokens.
A model may not have many facts about itself, but it can definitely see what is inside of its own context, and what it sees is a call to an image generation tool.
Finally, and most convincingly, I can't find a single official source where OpenAI claims that the image is being generated pixel-by-pixel inside of the context window.
throwaway314155
Sorry but I think you may be mistaken if your only source is ChatGPT. It's not aware of its own creation processes beyond what is included in its system prompt.
cchance
i mean on free chat an image took maybe 2 seconds?
user3939382
I’ll just be happy with not everything having that over saturated cg/cartoon style that you cant prompt your way out of.
alana314
I was relying on that to determine if images were AI though
LeoPanthera
Frustratingly the DALL-E API actually has an option for this, you can switch it from "vivid" to "realistic".
This option is not exposed in ChatGPT, it only uses vivid.
jjeaff
Is that an artifact of the training data? Where are all these original images with that cartoony look that it was trained on?
wongarsu
A large part of deviantart.com would fit that description. There are also a lot of cartoony or CG images in communities dedicated to fanart. Another component in there is probably the overly polished and clean look of stock images, like the front page results of shutterstock.
"Typical" AI images are this blend of the popular image styles of the internet. You always have a bit of digital drawing + cartoon image + oversaturated stock image + 3d render mixed in. Models trained on just one of these work quite well, but for a generalist model this blend of styles is an issue
astrange
> There are also a lot of cartoony or CG images in communities dedicated to fanart.
Asian artists don't color this way though; those neon oversaturated colors are a Western style.
(This is one of the easiest ways to tell a fake-anime western TV show, the colors are bad. The other way is that action scenes don't have any impact because they aren't any good at planning them.)
jl6
Wild speculation: video game engines. You want your model to understand what a car looks like from all angles, but it’s expensive to get photos of real cars from all angles, so instead you render a car model in UE5, generating hundreds of pictures of it, from many different angles, in many different colors and styles.
ToValueFunfetti
I've heard this is downstream of human feedback. If you ask someone which picture is better, they'll tend to pick the more saturated option. If you're doing post-training with humans, you'll bake that bias into your model.
minimaxir
Ever since Midjourney popularized it, image generation models are often posttrained on more "aesthetic" subsets of images to give them a more fantasy look. It also help obscure some of the imperfections of the AI.
HappMacDonald
.. either that or they are padding out their training data with scads of relatively inexpensive to produce 3d rendered images</speculation>
Wehrdo
It's largely an artifact of classifier-free guidance used in diffusion models. It makes the image generation more closely follow the prompt but also makes everything look more saturated and extreme.
richardfulop
you really have to NOT try to end up with that result in MJ.
alach11
It's incredible that this took 316 days to be released since it was initially announced. I do appreciate the emphasis in the presentation on how this can be useful beyond just being a cool/fun toy, as it seems most image generation tools have functioned.
Was anyone else surprised how slow the images were to generate in the livestream? This seems notably slower than DALLE.
jermaustin1
I've never minded that an image might take 10-30 seconds to generate. The fact that people do is crazy to me. A professional artist would take days, and cost $100s for the same asset.
I ran stable diffusion for a couple of years (maybe?, time really hasn't made sense since 2020) on my Dual 3090 rendering server. I built the server originally for crypto heating my office in my 1820s colonial in upstate NY then when I was planning to go back to college (got accepted into a university in England), I switched it's focus to Blender/UE4 (then 5), then eventually to AI image gen. So I've never minded 20 seconds for an image. If I needed dozens of options to pick the best, I was going to click start and grab a cup of coffee, come back and maybe it was done. Even if it took 2 hours, it is still faster than when I used to have to commission art for a project.
I grew out of Stable Diffusion, though, because the learning curve beyond grabbing a decent checkpoint and clicking start was actually really high (especially compared to LLMs that seamed to "just work"), after going through failed training after failed fine-tuning using tutorials that were a couple days out of date, I eventually said, fuck it, I'm paying for this instead.
All that to say - if you are using GenAI commercially, even if an image or a block of code took 30 minutes, it's still WAY cheaper than a human. That said, eventually a professional will be involved, and all the AI slop you generated will be redone, which will still cost a lot, but you get to skip the back and forth figuring out style/etc.
lxgr
Is there any way to see whether a given prompt was serviced by 4o or Dall-E?
Currently, my prompts seem to be going to the latter still, based on e.g. my source image being very obviously looped through a verbal image description and back to an image, compared to gemini-2.0-flash-exp-image-generation. A friend with a Plus plan has been getting responses from either.
The long-term plan seems to be to move to 4o completely and move Dall-E to its own tab, though, so maybe that problem will resolve itself before too long.
og_kalu
4o generates top down (picture goes from mostly blurry to clear starting from the top). If it's not generating like that for you then you don't have it yet.
lxgr
That's useful, thank you! But it also highlights my point: Why do I have to observe minor details about how the result is being presented to me to know which model was used?
I get the intent to abstract it all behind a chat interface, but this seems a bit too much.
og_kalu
Oh I agree 100%. Open AI roll outs leave much to be desired. Sometimes there isn't even a clear difference like there is for this.
cchance
I mean in the webpage the dalle one has a bubble under that says "generated with dall-e"
n2d4
If you don't have access to it on ChatGPT yet, you can try Sora, which already has access for me.
tethys
I've generated (and downloaded) a couple of images. All filenames start with `DALL·E`, so I guess that's a safe way to tell how the images were generated.
wes-k
My images say "Created with DALLE" below them, and a little info icon tells me they are rolling out the new one soon.
cchance
don't enable images on the chat model if your using the site, just leave it all disabled and ask for an image, if you enable dall-e it switches to dall-e is what i've seen
the native just.. works
bb88
My experience with these announcements is that they're cherry picking the best results from a maybe several hundred or a thousand prompts.
I'm not saying that it's not true, it's just "wait and see" before you take their word as gold.
I think MS's claim on their quantum computing breakthrough is the latest form of this.
xela79
> My experience with these announcements is that they're cherry picking the best results from a maybe several hundred or a thousand prompt
just tried it, prompt adherence and quality is... exactly what they said, it extremely impressive
wes-k
The examples they show have little captions that say "best of #", like "best of 8" or "best of 4". Hopefully that truly represents the odds of generating the level of quality shown.
aqme28
Some of the prompts are pretty long. I'm curious how iterations it took to get to that prompt for them to take the top 8 out of.
bb88
I'm not doubting it's an improvement, because it looks like it is.
I guess here's an example of a prompt I would like to see:
A flying spaghetti monster with a metal colander on its head flying above New York City saving the world from and very very evil Pope.
I'm not anti/pro spaghetti monster or catholicism. But I can visualize it clearly in my head what that prompt might look like.
kilroy123
Have you tried it? It's crazy good.
PufPufPuf
Can it be tried? ChatGPT still uses DALL-E for me.
bb88
No offense but after years of vaporware and announcements that seemed more plausible than implausible, I'll remain skeptical.
I will also not give them my email address just to try it out.
Maxion
Why are you making blanket statements on things that you haven't even tried? This is leaps and bounds better than before.
WithinReason
why not use a fake email address?
lottaFLOPS
it’s rolling out to users on all tiers, so no need to wait. I tried it and saw outputs from many others. it’s good. very good
neocritter
I got the occasional A/B test with a new image generator while playing with Dall-E during a one month test of Plus. It was always clear which one was the new model because every aspect was so much better. I assume that model and the model they announced are the same.
DarmokJalad1701
You should try it out yourself.
ilaksh
The new model in the drop down says something like "4o Create Image (Updated)". It is truly incredible. Far better than any other image generator as far as understanding and following complex prompts.
I was blown away when they showed this many months ago, and found it strange that more people weren't talking about it.
This is much more precise than the Gemini one that just came out recently.
MoonGhost
> found it strange that more people weren't talking about it.
Some simply dislike everything OpenAI. Just like everything Musk or Trump.
gs17
This is really impressive, but the "Best of 8" tag on a lot of them really makes me want to see how cherry-picked they are. My three free images had two impressive outputs and one failure.
do_not_redeem
The high five looks extremely unnatural. Their wrists are aligned, but their fingers aren't, somehow?
If that's best of 8, I'd love to see the outtakes.
tiahura
Agreed. It seems totally unnatural that a couple of nerds high-five awkwardly.
do_not_redeem
Not awkward. Anatomically uncanny and physically impossible.
aurareturn
First AI image generator to pass the uncanny valley test? Seems like it. This is the biggest leap in image generation quality I've ever seen.
How much longer until an AI that can generate 30 frames with this quality and make a movie?
About 1.5 years ago, I thought AI would eventually allow anyone with an idea to make a Hollywood quality movie. Seems like we're not too far off. Maybe 2-3 more years?
kgeist
>First AI image generator to pass the uncanny valley test?
Other image generators I've used lately often produced pretty good images of humans, as well [0]. It was DALLE that consistently generated incredibly awful images. Glad they're finally fixing it. I think what most AI image generators lack the most is good instruction following.
[0] YandexArt for the first prompt from the post: https://imgur.com/a/VvNbL7d The woman looks okay, but the text is garbled, and it didn't fully follow the instruction.
aurareturn
Do you have another example from YandexArt?
https://images.ctfassets.net/kftzwdyauwt9/7M8kf5SPYHBW2X9N46...
{kind=link}
OpenAI's human faces look *almost* real.
kgeist
>OpenAI's human faces look almost real.
Not sure, I tried a few generations, and it still produces those weird deformed faces, just like the previous generation: https://imgur.com/a/iKGboDH Yeah, sometimes it looks okay.
YandexArt for comparison: https://imgur.com/a/K13QJgU
null
GaggiX
Ideogram 2.0 and Recraft also create images that looks very much real.
For drawings, NovelAI's models are way beyond the uncanny valley now.
What's important about this new type of image generation that's happening with tokens rather than with diffusion, is that this is effectively reasoning in pixel space.
Example: Ask it to draw a notepad with an empty tic-tac-toe, then tell it to make the first move, then you make a move, and so on.
You can also do very impressive information-conserving translations, such as changing the drawing style, but also stuff like "change day to night", or "put a hat on him", and so forth.
I get the feeling these models are quite restricted in resolution, and that more work in this space will let us do really wild things such as ask a model to create an app step by step first completely in images, essentially designing the whole app with text and all, then writing the code to reproduce it. And it also means that a model can take over from a really good diffusion model, so even if the original generations are not good, it can continue "reasoning" on an external image.
Finally, once these models become faster, you can imagine a truly generative UI, where the model produces the next frame of the app you are using based on events sent to the LLM (which can do all the normal things like using tools, thinking, etc). However, I also believe that diffusion models can do some of this, in a much faster way.