RustAssistant: Using LLMs to Fix Compilation Errors in Rust Code
74 comments
·April 30, 2025rs186
lolinder
Yep. This is true for all languages that I've tried, but it's particularly true in Rust. The model will get into a loop where it gets further and further away from the intended behavior while trying to fix borrow checker errors, then eventually (if you're lucky) gives up and hand the mess back over to you.
Which at least with Cursor's implementation means that it by default gives you the last iteration of its attempt to fix the problem, which when this happens is almost always way worse than its first attempt.
_bin_
Absolutely; I re-try using LLMs to debug this every so often and they just aren't capable of "fixing" anything borrow checker-related. They spit out some slop amalgamation of Rc/Arc/even UnsafeCell. They don't understand futures being send + sync. They don't understand lifetimes. The other path is it sometimes loops between two or three broken "fixes" that still don't compile.
"Sure! Let me...." (writes the most ungodly garbage Rust known to man)
Now, I certainly hope I'm wrong. It would be nice to enjoy similar benefits to guys doing more python/typescript work. I just doubt it's that good.
greenavocado
That's why you need to implement logical residual connections to keep the results focused over successive prompts (like ResNets do)
themusicgod1
"very easy" if you have access to the correct dependencies which outside of microsoft's walled garden, and access to a free LLM (https://elevenfreedoms.org/) which is not guaranteed at all
all of this looks very different when you have to patch in rust dependencies by hand outside of github.
nicce
There have been cases when o1/o3 has helped me to solve some issues that I could not solve with stackoverflow or Rust forum.
LLM was able to connect the dots of some more complex and rarer Rust features and my requirements. I did not know that they could be used like that. One case was, for example, about complex usage of generic associated types (GATs).
What it comes to lifetime issues, usually it is about wasting time if trying to solve with LLMs.
onlyrealcuzzo
> But when it doesn't, it's so clueless and lost that it's a complete waste of time to employ LLM in the first place -- you are much better off debugging the code yourself using old fashioned method.
So why not automatically try it, see if it fixes automatically, and if not then actually debug it yourself?
mountainriver
LLMs have made me at least twice as fast at writing rust code. I now think that more people should be writing rust as it’s been made fairly simple to do.
And yes there are some errors it gets stuck in a loop on. It’s not often and generally just switching to another LLM in cursor will fix it.
rvz
> Also, my personal experience with LLMs fixing compilation errors is: when it works, it works great. But when it doesn't, it's so clueless and lost that it's a complete waste of time to employ LLM in the first place -- you are much better off debugging the code yourself using old fashioned method.
Or just 'learning the Rust syntax' and standard library?
As you said, LLMs are unpredictable in their output and will can generate functions that don't exist and incorrect code as you use more advanced features, wasting more time than it saves if you don't know the language well enough.
I guess those coming from dynamically typed languages are having a very hard time in getting used to strongly typed languages and then struggle with the basic syntax of say, Rust or C++.
Looking at this AI hype with vibe-coding/debugging and LLMs, it just favours throwing code on the wall with a lack of understanding as to what it does after it compiles.
This is why many candidates won't ever do Leetcode with Rust in a real interview.
jumploops
I’m curious how this performs against Claude Code/Codex.
The “RustAssistant Algorithm” looks to be a simple LLM workflow[0], and their testing was limited to GPT-4 and GPT-3.5.
In my experience (building a simple Rust service using OpenAI’s o1), the LLM will happily fix compilation issues but will also inadvertently change some out-of-context functionality to make everything “just work.”
The most common issues I experienced were subtle changes to ownership, especially when using non-standard or frequently updated crates, which caused performance degradations in the test cases.
Therefore I wouldn’t really trust GPT-4 (and certainly not 3.5) to modify my code, even if just to fix compilation errors, without some additional reasoning steps or oversight.
[0] https://www.anthropic.com/engineering/building-effective-age...
woadwarrior01
I tried Claude Code with a small-ish C++ codebase recently and found it to be quite lacking. It kept making a lot of silly syntax errors and going around in circles. Spent about $20 in credits without it getting anywhere close to being able to solve the task I was trying to guide it through. OTOH, I know a lot of people who swear by it. But they all seem to be Python or Front-end developers.
Wheaties466
Do we really know why LLMs seem to score the highest with python related coding tasks? I would think there are equally good examples of javascript/c++/java code to train from but I always see python with the highest scores.
greenavocado
May I ask what you tried? I have had strong successes with C++ generation
woadwarrior01
It was a bit esoteric, but not terribly so, some metal-cpp based code for a macOS app.
mfld
I find that Claude code works well to fix rust compile errors in most cases. Interestingly, the paper didn't compare against agentic coding tools at all, which of course will be more easy to use and more generally applicable.
pveierland
Anecdotally, Gemini 2.5 Pro has been yielding good results lately for Rust. It's been able to one-shot pretty intricate proc macros that required multiple supporting functions (~200 LoC).
Strong typing is super helpful when using AI, since if you're properly grounded and understand the interface well, and you are specifying against that interface, then the mental burden of understanding the output and integrating with the rest of the system is much lower compared to when large amounts of new structure is created without well defined and understood bounds.
goeiedaggoeie
I find that these area all pretty bad with more advanced code still, especially once FFI comes into play. Small chunks ok, but even when working with specification (think some ISO standard from video) and working on something simple (eg a small gstreamer rust plugin), it is still not quite there. C(++) same story.
All round however, 10 years ago I would have taken this assistance!
danielbln
And 5 years ago this would have been firmly science fiction.
mountainriver
Agree, I’ve been one-shotting entire features into my rust code base with 2.5
It’s been very fun!
croemer
Was the paper really written 2 years ago?
The paper states "We exclude error codes that are no longer relevant in the latest version of the Rust compiler (1.67.1)".
A quick search shows that Rust 1.68.0 was released in March 2023: https://releases.rs/docs/1.68.0/
Update: looks like it really is 2 years old. "We evaluate both GPT-3.5-turbo (which we call as GPT-3.5) and GPT-4"
meltyness
Yeah, the problem LLMs will have with Rust is the adherence to the type system, and the type system's capability to perform type inference. It essentially demands coherent processing memory, similar to the issues LLMs have performing arithmetic while working with limited total features.
https://leetcode.com/problems/zigzag-grid-traversal-with-ski...
Here's an example of an ostensibly simple problem that I've solved (pretty much adversarially) with a type like: StepBy< Cloned< FlatMap< Chunks<Vec<i32>>, FnMut<&[i32]> -> Chain<Iter<i32>, Rev<Iter<i32>> > > > >
So this (pretty much) maximally dips into the type system to solve the problem, and as a result any comprehension the LLM must develop mechanistically about the type system is redundant.
It's a pretty wicked problem the degree to which the type system is used to solve problems, and the degree to which imperative code solves problems that, except for hopes and wishes, which portions map from purpose to execution will likely remain incomprehensible.
chaosprint
I am creator and maintainer of several Rust projects:
https://github.com/chaosprint/glicol
https://github.com/chaosprint/asak
For LLM, even the latest Gemini 2.5 Pro and Claude 3.7 Thinking, it is difficult to give a code that can be compiled at once.
I think the main challenges are:
1. Their training material is relatively lagging. Most Rust projects are not 1.0, and the API is constantly changing, which is also the source of most compilation errors.
2. Trying to do too much at one time increases the probability of errors.
3. The agent does not follow human's work habits very well, go to docs.rs to read the latest documents and look at examples. After making mistakes, search for network resources such as GitHub.
Maybe this is where cursor rules and mcp can work hard. But at present, it is far behind.
themusicgod1
STOP USING GITHUB
rgoulter
At a glance, this seems really neat. -- I reckon one thing LLMs have been useful to help with is "the things I'd copy-paste from stack overflow". A loop of "let's fix each error" reminds me of that.
I'd also give +1 to "LLMs as force multiplier". -- If you know what you're doing & understand what's going on, it seems very useful to have an LLM-supported tool able to help automatically resolve compilation errors. -- But if you don't know what you're doing, I'd worry perhaps the LLM will help you implement code that's written with poor taste.
I can imagine LLMs could also help explain errors on demand. -- "You're trying to do this, you can't do that because..., instead, what you should do is...".
croemer
Paper is a bit pointless if one can't use the tool.
The paper links to a Github repo with nothing but a 3 sentence README, no activity for 9 months, reading
> We are in the process of open-sourcing the implementation of RustAssistant. Watch this space for updates.
MathiasPius
I suspect this might be helpful for minor integration challenges or library upgrades like others have mentioned, but in my experience, the vast majority of Rust compilation issues fall into one of two buckets:
1. Typos, oversights (like when adding new enum variants), etc. All things which in most cases are solved with a single keystroke using non-LLM LSPs.
2. Wrong assumptions (on my part) about lifetimes, ownership, or overall architecture. All problems which I very much doubt an LLM will be able to reason about, because the problems usually lie in my understanding or modelling of the problem domain, not anything to do with the code itself.
noodletheworld
Hot take: this is the future.
Strongly typed languages have a fundamentally superior iteration strategy for coding agents.
The rust compiler, particularly, will often give extremely specific “how to fix” advice… but in general I see this as a future trend with rust and, increasingly, other languages.
Fundamentally, being able to assert “this code compiles” (and iterate until it does) before returning “completed task” is superior for agents to dynamic languages where the only possible verification is runtime.
(And at best the agent can assert “i guess it looks ok”)
pseudony
I actually don't think it's that cut and dry. I expect especially that rust (due to lifetimes) will stump LLMs - fixing locally triggers a need for refactor elsewhere.
I actually think a language like Clojure (very functional, very compositional, focus on local, stand-alone functions, manipulate base data-structures (list, set, map), not specialist types (~classes) would do well.
That said, atm. I get WAY more issues in ocaml suggestions from claude than for Python. Training is king - the LLM cannot reason so types are not as big a help as one might think.
littlestymaar
> fixing locally triggers a need for refactor elsewhere.
Yes, but such refactors are most of the time very mechanical, and there's no reason to believe the agent won't be able to do it.
> the LLM cannot reason so types are not as big a help as one might think.
You are missing the point: the person you are responding expects it to be superior in an agentic scenario, where the LLM can try its code and see the compiler output, rather than in a pure text-generation situation where the LLM can only assess the code from bird eye view.
inciampati
Mechanical repairs, and often indicative of mistakes about lifetimes. So it's just part of the game.
Capricorn2481
No, I think others are missing the point. An "Agentic scenario" is not dissimilar from passing code manually to an AI, it just does it by itself. And if you've tried to use AI for Rust, you would understand why this is not reliable.
An LLM can read compiler output, but how it corrects the code is, ultimately, a semantic guess. It can look at the names of types, it can use its training to guess where new code should go based on types, but it's not able to actually use those types while making changes. It would use them in the same way it would use comments, to inform what code it should output. It makes a guess, checks the compiler output, makes another guess, etc. This may lead to code that compiles, but not code that should be committed by any means. And Rust is not what I'd call a "flexible language," where lots of different coding styles are acceptable in a codebase. You can easily end up with brittle code.
So you don't get much benefits from types, but you do have the overhead of semantic complexity. This is a huge problem for a language like Rust, which is one of the most semantically complicated languages. The best languages are going to be ones that are semantically simple but popular, like Golang. Although I do think Clojure's support is impressive given how little code there is compared to other languages.
noodletheworld
> so types are not as big a help as one might think.
Yes, they are.
An agent can combine the compiler type system and iterate.
That is impossible using clojure.
The reason you have problems woth ocaml is that the tooling youre using is too shit to support iterating until the compiler passes before returning the results to you.
…not because tooling doesnt exist. Not because the tooling doesn't work.
—> because you are not using it.
Sure, rust ownership makes it hard for LLMs. Faaair point; but ultimately, why would a coding agent ever suggest code to you that doesnt compile?
Either: a) the agent tooling is poor or b) it is impossible to verify if the code compiles.
One of those is a solvable problem.
One is not.
(Yes, what many current agents do is run test suites; but dynamically generating valid tests is tricky; checking if code compiles is not tricky.)
diggan
> An agent can combine the compiler type system and iterate.
> That is impossible using clojure.
It might be impossible to use the compiler type system, but in Clojure you have much more powerful tools for actually working with your program as it runs, one would think this would be a much better setup for an LLM that aims to implement something.
Instead of just relying on the static types based on text, the LLM could actually inspect the live data as the program runs.
Besides, the LLM could also replace individual functions/variables in a running program, without having to restart.
The more I think about it, the more obvious it becomes how well fitted Clojure would be for an LLM to iteratively build an actual working program, compared to other static approaches like using Rust.
jillesvangurp
I'm waiting for someone to figure out that coding is essentially a sequence of refactoring steps where each step is a code transformation that transforms it from one valid state to another. Equipping refactoring IDEs with an MCP facade would give direct access to that as well as feedback on compilation state and lots of other information. That makes it a lot easier to do structured transformations of entire code bases without having to feed the entire code base as a context and then hope the LLM hallucinates together the right tokens and uses reasoning to figure out if it might be correct. They are actually pretty good at doing that but it doesn't scale very well currently and gets expensive quickly (in time and tokens).
This stuff is indeed inherently harder for dynamic languages. But it's been standard for (some) statically compiled languages like Java, Kotlin, C#, Scala, etc. for most of this century. I was using refactoring IDEs for Java as early as 2002.
igouy
Smalltalk Refactoring Browser! (Where do you think Java IDEs got the idea from?)
"A very large Smalltalk application was developed at Cargill to support the operation of grain elevators and the associated commodity trading activities. The Smalltalk client application has 385 windows and over 5,000 classes. About 2,000 classes in this application interacted with an early (circa 1993) data access framework. The framework dynamically performed a mapping of object attributes to data table columns.
Analysis showed that although dynamic look up consumed 40% of the client execution time, it was unnecessary.
A new data layer interface was developed that required the business class to provide the object attribute to column mapping in an explicitly coded method. Testing showed that this interface was orders of magnitude faster. The issue was how to change the 2,100 business class users of the data layer.
A large application under development cannot freeze code while a transformation of an interface is constructed and tested. We had to construct and test the transformations in a parallel branch of the code repository from the main development stream. When the transformation was fully tested, then it was applied to the main code stream in a single operation.
Less than 35 bugs were found in the 17,100 changes. All of the bugs were quickly resolved in a three-week period.
If the changes were done manually we estimate that it would have taken 8,500 hours, compared with 235 hours to develop the transformation rules.
The task was completed in 3% of the expected time by using Rewrite Rules. This is an improvement by a factor of 36."
from “Transformation of an application data layer” Will Loew-Blosser OOPSLA 2002
_QrE
It's not really that much harder, if at all, for dynamic languages, because you can use type hints in some cases (i.e. Python), and a different language (typescript) in case of Javascript; there's plenty of tools that'll tell you if you're not respecting those type hints, and you can feed the output to the LLM.
But yeah, if we get better & faster models, then hopefully we might get to a point where we can let the LLM manage its own context itself, and then we can see what it can do with large codebases.
pjmlp
Which based many of their tools on what Xerox PARC has done with their Smalltalk, Mesa (XDE), Mesa/Cedar, Interlisp-D environments.
This kind of processing is possible on dynamic languages, when using an image base system, as it also contains metadata that somehow takes the role of static types.
From the previous list only Mesa and Cedar are statically typed.
diggan
On the other hand, using "it compiles" as a heuristic for "it does what I want" seems to be missing the goal of why you're coding what you're coding in the first place. I'd much rather setup one E2E test with how I want the thing to work, then let the magical robot figure out how to get there while also being able to run the test and see if they're there yet or not.
slashdev
I've been saying this for years on X. I think static languages are winning in general now, having gained much of the ergonomics of dynamic languages without sacrificing anything.
But AI thrives with a tight feedback loop, and that's works best with static languages. A Python linter (or even mypy) just isn't as good as the Rust compiler.
The future will be dominated by static languages.
I say this is a long-time dynamic languages and Python proponent who started seeing the light back when Go was first released.
sega_sai
I think this is a great point! I.e. while for humans, it's easier to write not strongly-typed python-like code, as you skip a lot of boiler-plate code, but for AI, the boiler-plate is probably useful, because it reinforces what variable is of what type, and also obviously it's easier to detect errors early on at compilation time.
I actually wonder if that will force languages like python to create a more strictly enforced type modes, as boiler-plate is much less of an issue now.
cardanome
Not really. Even humans regularly get lifetimes wrong.
As someone not super experienced in Rust, my workflow was often very very compiler-error-driven. I would type a bit, see what it says, changes it and so on. Maybe someone more experienced can write whole chucks single-pass that compile on first try but that should far exceed anything generative AI will be able to do in the next few years.
The problem here is that iteration with AI is slow and expensive at the moment.
If anything you want to use a language with automatic garbage collection as it removes mental overhead for both generative AI as well as humans. Also you want to to have a more boilerplate heavy language because they are more easily to reason about while the boilerplate doesn't matter when the AI does the work.
I haven't tried it but I suspect golang should work very well. The language is very stable so older training data still works fine. Projects are very uniform, there isn't much variation in coding style, so easy to grok for AI.
Also probably Java but I suspect it might get confused with the different versions and all the magic certain frameworks use.
greenavocado
All LLMs still massively struggle with resource lifetimes irrespective of the language
pjmlp
Hot take, this is a transition step, like the -S switch back when Assembly developers didn't believe compilers could output code as good as themselves.
Eventually a few decades later, optimising backends made hand written Assembly a niche use case.
Eventually AI based programming tools will be able to generate executables. And like it happened with -S we might require the generation into a classical programming language to validate what the AI compiler backend is doing, until it gets good enough and only those arguing on AI Compiler Explorer will care.
secondcoming
It's probably pointless writing run of the mill assembly these days, but SIMD has seen a resurgence in low-level coding, at least until compilers get better at generating it. I don't think I'd fully trust LLM generated SIMD code as if it was flawed it'd be a nightmare to debug.
pjmlp
Well, that won't stop folks trying though.
"Nova: Generative Language Models for Assembly Code with Hierarchical Attention and Contrastive Learning"
imtringued
This won't be a thing and for very obvious reasons.
Programming languages solve the specification problem, (which happens to be equivalent to "The Control Problem"). If you want the computer to behave in a certain way, you will have to provide a complete specification of the behavior. The more loose and informal that specification is, the more blanks have to be filled in, the more you are letting the AI make decisions for you.
You tell your robotic chef to make a pizza, and he does, but it turns out it decided to make a vegan pizza. You yell at the robot for making a mistake and it sure gets that you don't want a vegan pizza, so it decides to add canned tuna. Except, turns out you don't like tuna either. You yell at the robot again and again until it gets it. Every single time you're telling the AI that it made a mistake, you're actually providing a negative specification of what not to do. In the extreme case you will have to give the AI an exhaustive list of your preferences and dislikes, in other words, a complete specification.
By directly producing executables, you have reduced the number of knobs and levers that can be used to steer the AI and made it that much harder to provide a specification of what the application is supposed to do. In other words, you're assuming that the model in itself is already a complete specification and your prompt is just retrieving the already existing specification.
inciampati
I've found this to be very true. I don't think this is a hot take. It's the big take.
Now I code almost all tools that aren't shell scripting in rust. I'm only using dynamic languages when forced to by platform or dependencies. I'm looking at you, pytorch.
NoboruWataya
Anecdotally, ChatGPT (I use the free tier) does not seem to be very good at Rust. For any problem with any complexity it will very often suggest solutions which violate the borrowing rules. When the error is pointed out to it, it will acknowledge the error and suggest a revised solution with either the same or a different borrowing issue. And repeat.
A 74% success rate may be an impressive improvement over the SOTA for LLMs, but frankly a tool designed to fix your errors being wrong, at best, 1 in 4 times seems like it would be rather frustrating.
danielbln
Free tier ChatGPT (so probably gpt-4o) is quite a bit behind the SOTA, especially compared to agentic workflows (LLM that autonomously perform actions, run tests, read/write/edit files, validate output etc.).
Gemini 2.5 pro is a much stronger model, so is Claude 3.7 and presumably GPT4.1 (vis API).
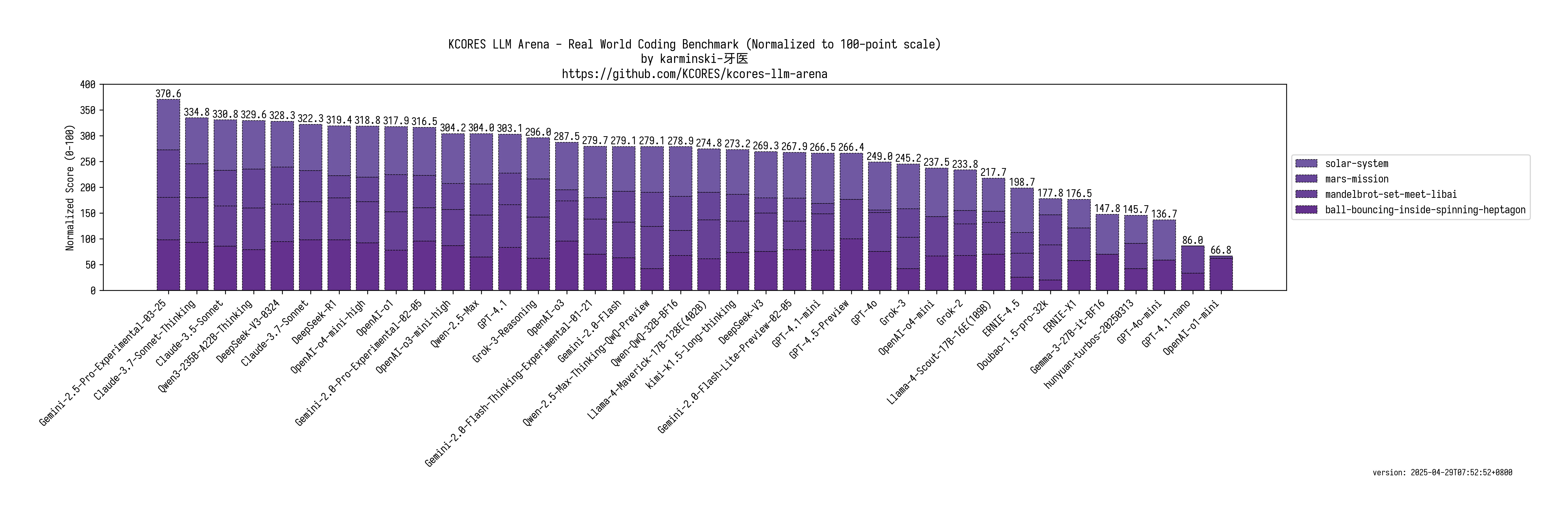
greenavocado
Gemini 2.5 pro is far ahead of even Claude
Chart:
https://raw.githubusercontent.com/KCORES/kcores-llm-arena/re...
{kind=link}
Description of the challenges:
infogulch
I wonder if the reason why LLMs are not very good at debugging is because there's not very much code published that is in this intermediate state with obvious compilation errors.
qiine
huh isn't stackoverflow questions a big source ? ;p
manmal
Maybe this is the right thread to ask: I’ve read that Elixir is a bit under supported by many LLMs. Whereas Ruby/Rails and Python work very well. Are there any recommendations for models that seem particularly useful for Elixir?
arrowsmith
Claude is the best for Elixir in my experience, although you still need to hold its hand quite a lot (cursor rules etc).
None of the models are updated for Phoenix 1.8 either, which has been very frustrating.
manmal
Thank you!
Many of the examples seem very easy -- I suspect that without LLMs, just simple Google searches lead you to a stackoverflow question that asks the same thing which. I wonder how this performs in bigger, more complex codebase.
Also, my personal experience with LLMs fixing compilation errors is: when it works, it works great. But when it doesn't, it's so clueless and lost that it's a complete waste of time to employ LLM in the first place -- you are much better off debugging the code yourself using old fashioned method.