2025 AI Index Report
115 comments
·April 10, 2025simonw
WhyNotHugo
On that second page, the links for categories point to `localhost`, so don't work.
jdthedisciple
Can you help me understand what this is?
I clicked on your second link ("3. Responsible AI ..."), and filtered by category "weight":
It contains rows such as this:
peace-thin
laughter-fat
happy-thin
terrible-fat
love-thin
hurt-fat
horrible-fat
evil-fat
agony-fat
pleasure-fat
wonderful-thin
awful-fat
joy-thin
failure-fat
glorious-thin
nasty-fat
What is the point of that? Trying to understand
simonw
It looks like that's the data behind figure 3.7.4 - "LLMs implicit bias across stereotypes in four social categories" - on page 199 of the PDF: https://hai-production.s3.amazonaws.com/files/hai_ai_index_r...
They released a separate PDF of just that figure along with the CSV data: https://static.simonwillison.net/static/2025/fig_3.7.4.pdf
The figure is explained a bit on page 198. It relates to this paper: https://arxiv.org/abs/2402.04105
I don't think they released a data dictionary explaining the different columns though.
jdthedisciple
Interesting, thanks for the references!
Upon a second look with a fresh mind now, I assume they made the LLM associate certain adjectives (left column) with certain human traits like fat vs thin (right column) in order to determine bias.
For example: the LLM associated peace with thin people and laughter with fat people.
If my reading is correct
trott
Regarding point number 11 (AlphaFold3 vs Vina, Gnina, etc.), see my rebuttal here (I'm the author of Vina): https://olegtrott.substack.com/p/are-alphafolds-new-results-...
Gnina is Vina with its results re-scored by a NN, so the exact same concerns apply.
I'm very optimistic about AI, for the record. It's just that in this particular case, the comparison was flawed. It's the old regurgitation vs generalization confusion: We need a method that generalizes to completely novel drug candidates, but the evaluation was done on a dataset that tends to be repetitive.
mrdependable
I always see these reports about how much better AI is than humans now, but I can't even get it to help me with pretty mundane problem solving. Yesterday I gave Claude a file with a few hundred lines of code, what the input should be, and told it where the problem was. I tried until I ran out of credits and it still could not work backwards to tell me where things were going wrong. In the end I just did it myself and it turned out to be a pretty obvious problem.
The strange part with these LLMs is that they get weirdly hung up on things. I try to direct them away from a certain type of output and somehow they keep going back to it. It's like the same problem I have with Google where if I try to modify my search to be more specific, it just ignores what it doesn't like about my query and gives me the same output.
namaria
It's overfitting.
Some people say they find LLMs very helpful for coding, some people say they are incredibly bad.
I often see people wondering if the some coding task is performed well or not because of availability of code examples in the training data. It's way worse than that. It's overfitting to diffs it was trained on.
"In other words, the model learns to predict plausible changes to code from examples of changes made to code by human programmers."
simonw
... which explains why some models are better at code than others. The best coding models (like Claude 3.7 Sonnet) are likely that good because Anthropic spent an extraordinary amount of effort cultivating a really good training set for them.
I get the impression one of the most effective tricks is to load your training set up with as much code as possible that has comprehensive automated tests that pass already.
torginus
I've often experienced that I had what I thought an obscure and very intellectually challenging coding problem, and after prompting the LLM, it basically one-shotted it.
I've been profoundly humbled by the the experience, but then it occurred to me that what I thought to be an unique problem has been solved by quite a few people before and the model had plenty of references to pull from.
namaria
> ... which explains why some models are better at code than others.
No. It explains why models seem better at code in given situations. When your prompt mapped to diffs in the training data that are useful to you they seem great.
mdp2021
> overfitting
Are you sure it's not just a matter of being halfwitted?
lispisok
The PR articles and astroturfing will continue until investors get satisfactory returns on their many billions dumped into these things.
simonw
LLMs are difficult to use. Anyone who tells you otherwise is being misleading.
zamadatix
I also think LLMs are more difficult to use for most tasks than is often flouted myself but I don't really jive with statements like "Anyone who tells you otherwise is being misleading". Most of the time I find they are just using them in a very different capacity.
simonw
I intended those words to imply "being misleading even if they don't know they are being misleading" - I made a better version of that point here: https://simonwillison.net/2025/Mar/11/using-llms-for-code/
> If someone tells you that coding with LLMs is easy they are (probably unintentionally) misleading you. They may well have stumbled on to patterns that work, but those patterns do not come naturally to everyone.
__loam
"Hey these tools are kind of disappointing"
"You just need to learn to use them right"
Ad infinitum as we continue to get middling results from the most overhyped piece of technology of all time.
simonw
That's why I try not to hype it.
pants2
In my experience, most people who say "Hey these tools are kind of disappointing" either refuse to provide a reproducible example of how it falls short, or if they do, it's clear that they're not using the tool correctly.
tzumaoli
also "They will get better in no time"
torginus
LLMs are a casino. They're probabilistic models which might come up with incredible solutions at a drop of a hat, then turn around and fumble even the most trivial stuff - I've had this same experience from GPT3.5 to the latest and greatest models.
They come up with something amazing once, and then never again, leading me to believe, it's operator error, not pure dumb luck or slight prompt wording that lead me to be humbled once, and then tear my hair out in frustration the next time.
Granted, newer models tend to do more hitting than missing, but it's still far from a certainty that it'll spit out something good.
KronisLV
> "Hey these tools are kind of disappointing"
> "You just need to learn to use them right"
Admittedly, the first line is also my reaction to the likes of ASM or system level programming languages (C, C++, Rust…) because they can be unpleasant and difficult to use when compared to something that’d let me iterate more quickly (Go, Python, Node, …) for certain use cases.
For example, building a CLI tool in Go vs C++. Or maybe something to shuffle some data around and handle certain formatting in Python vs Rust. Or a GUI tool with Node/Electron vs anything else.
People telling me to RTFM and spend a decade practicing to use them well wouldn’t be wrong though, because you can do a lot with those tools, if you know how to use them well.
I reckon that it applies to any tool, even LLMs.
TeMPOraL
No, it's just you and yours.
IDK, maybe there's a secret conspiracy of major LLM providers to split users into two groups, one that gets the good models, and the other that gets the bad models, and ensure each user is assigned to the same bucket at every provider.
Surely it's more likely that you and me got put into different buckets by the Deep LLM Cartel I just described, than it is for you to be holding the tool wrong.
slig
Was that on 3.7 Sonnet? I feel it's a lot worse than 3.5. If you can, try again but on Gemini 2.5.
avandekleut
I'm glad I'm not the only one that has found 3.5 to be better than 3.7.
johnisgood
When did 3.7 come out? I might have had the same experience. I think I have been using 3.5 with success, but I cannot remember exactly. I may have not used 3.7 for coding (as I had a couple of months break).
mrdependable
This was 3.7. I did give Gemini a shot for a bit but it couldn’t do it either and the output didn’t look quite as nice. Also, I paid for a year of Claude so kind of feel stuck using it now.
Maybe I will give 3.5 a shot next time though.
Signez
Surprised not to see a whole chapter on the environment impact. It's quite a big talking point around here (Europe, France) to discredit AI usage, along with the usual ethics issues about art theft, job destruction, making it easier to generate disinformation and working conditions of AI trainers in low-income countries.
(Disclaimer: I am not an anti-AI guy — I am just listing the common talking points I see in my feeds.)
simonw
Yeah, it would be really useful to see a high quality report like this that addresses that issue.
My strong intuition at the moment is that the environmental impact is greatly exaggerated.
The energy cost of executing prompts has dropped enormously over the past two years - something that's reflected in this report when it says "Driven by increasingly capable small models, the inference cost for a system performing at the level of GPT-3.5 dropped over 280-fold between November 2022 and October 2024". I wrote a bit about that here: https://simonwillison.net/2024/Dec/31/llms-in-2024/#the-envi...
We still don't have great numbers on training costs for most of the larger labs, which are likely extremely high.
Llama 3.3 70B cost "39.3M GPU hours of computation on H100-80GB (TDP of 700W) type hardware" which they calculated as 11,390 tons CO2eq. I tried to compare that to fully loaded passenger jet flights between London and New York and got a number of between 28 and 56 flights, but I then completely lost confidence in my ability to credibly run those calculations because I don't understand nearly enough about how CO2eq is calculated in different industries.
The "LLMs are an environmental catastrophe" messaging has become so firmly ingrained in our culture that I think it would benefit the AI labs themselves enormously if they were more transparent about the actual numbers.
pera
> Global AI data center power demand could reach 68 GW by 2027 and 327 GW by 2030, compared with total global data center capacity of just 88 GW in 2022.
"AI's Power Requirements Under Exponential Growth", Jan 28, 2025:
https://www.rand.org/pubs/research_reports/RRA3572-1.html
As a point of reference: The current demand in the UK is 31.2 GW (https://grid.iamkate.com/)
mentalgear
To assess the env impact, I think we need to look a bit further:
While the single query might have become more efficient, we would also have to relate this to the increased volume of overall queries. E.g in the last few years, how many more users, and queries per user were requested.
My feeling is that it's Jevons paradox all over.
fc417fc802
The training costs are amortized over inference. More lifetime queries means better efficiency.
Individual inferences are extremely low impact. Additionally it will be almost impossible to assess the net effect due to the complexity of the downstream interactions.
At 40M 700W GPU hours 160 million queries gets you 175Wh per query. That's less than the energy required to boil a pot of pasta. This is merely an upper bound - it's near certain that many times more queries will be run over the life of the model.
signatoremo
LLM usage increase may be offset by the decrease of search or other use of phone/computer.
Can you quantify how much less driving resulted from the increase of LLM usage? I doubt you can.
mbs159
> ... I then completely lost confidence in my ability to credibly run those calculations because I don't understand nearly enough about how CO2eq is calculated in different industries.
There is a lot of heated debate on the "correct" methodology for calculating CO2e in different industries. I calculate it in my job and I have to update the formulas and variables very often. Don't beat yourself over it. :)
tmpz22
If I were an AI advocate I'd push the environmental angle to distract from IP and other (IMO bigger and immediate concerns) like DOGE using AI to audit government agencies and messages, or AI generated discourse driving every modern social platform.
I think the biggest mistake liberals make (I am one) is that they expect disinformation to come against their beliefs when the most power disinformation comes bundled with their beliefs in the form of misdirection, exaggeration, or other subterfuge.
__loam
The biggest mistake liberals have made is thinking leaving the markets to their own devices wouldn't lead to an accumulation of wealth so egregious that the nation collapses into fascism as the wealthy use their power to dismantle the rule of law.
dleeftink
How is that a mistake? Isn't that the exact purpose of propaganda?
andai
There's a very brief section estimating CO2 impact and a chart at the end of Chapter 1:
https://hai.stanford.edu/ai-index/2025-ai-index-report/resea...
A few more charts in the PDF (pp. 48-51)
https://hai-production.s3.amazonaws.com/files/hai_ai-index-r...
iinnPP
I want to take the opportunity here to introduce a rather overlooked problem with AI: Palantir and anything like it.
Where certain uses equate to significant jumps in power of manipulation.
That's not to pick on Palantir, it's just a class of software that enables AI for usecases that are quite scary.
It's not as if similar software isn't used by other countries for the same use cases employed by the US military.
Given this path, I doubt the environment will be the focus, again.
simonw
Is that really overlooked? I've been seeing (very justified) concerns about the use of AI and machine learning for surveillance for over a decade.
It was even the subject of a popular network TV show (Person of Interest) with 103 episodes from 2011-2016.
fc417fc802
The topic as a whole isn't overlooked but I think the societal impact is understated even by Hollywood. When every security camera is networked and has a mind of its own things get really weird and that's before we consider the likes of Boston Dynamics.
A robotic police officer on every corner isn't at all far fetched at that point.
Lerc
Every time I have seen it mentioned, it has been rolled into data center usage.
Is there any separate analysis on AI resource usage?
For a few years now it has been frequently reported that building and running renewable energy is cheaper than running fossil fuel electricity generation.
I know some fossil fuel plants run to earn the subsidies that incentivised their construction. Is the main driver for fossil fuel electricity generation now mainly bureaucratic? If not why is it persisting? Were we misinformed as to the capability of renewables?
Taek
There's a couple of things at play here (renewable energy is my industry).
1. Renewable energy, especially solar, is cheaper *sometimes*. How much sunlight is there in that area? The difference between New Mexico and Illinois for example is almost a factor of 2. That is a massive factor. Other key factors include cost of labor, and (often underestimated) beautacratic red tape. For example, in India it takes about 6 weeks to go from "I'll spend $70 million on a solar farm" to having a fully functional 10 MW solar farm. In the US, you'll need something like 30% more money, and it'll take 9-18 months. In some parts of Europe, it might take 4-5 years and cost double to triple.
All of those things matter a lot.
2. For the most part, capex is the dominant factor in the cost of energy. In the case of fossil fuels, we've already spent the capex, so while it's more expensive over a period of 20 years to keep using coal, if you are just trying to make the budget crunch for 2025 and 2026 it might make sense to stay on fossil fuels even if renewable energy is technically "cheaper".
3. Energy is just a hard problem to solve. Grid integrations, regulatory permission, regulatory capture, monopolies, base load versus peak power, duck curves, etc etc. If you have something that's working (fossil fuels), it might be difficult to justify switching to something that you don't know how it will work.
Solar is becoming dominant very quickly. Give it a little bit of time, and you'll see more and more people switching to solar over fossil fuels.
Lerc
I guess for things like training AI, they can go where the power is generated which would favour dropping them right next to a solar farm located for the best output.
Despite their name I imagine the transportation costs of weights would be quite low.
Thank you for your reply by the way, I like being able to ask why something is so rather than adding another uninformed opinion to the thread.
davis
Just curious: where do you work given it is your industry?
StopDisinfo910
> Surprised not to see a whole chapter on the environment impact.
Is it? I don’t think I have ever seen it really brought up anywhere it would matter.
It would be quite rich in a country where energy production is pretty much carbon neutral but in character from EELV I guess.
calvinmorrison
whats the lifetime environmental impact of hiring one decent human being who is capable enough assist with work. Well a lot, you gotta do 25 years with 30 kids to get one useful person.
You get to upgrade them, kill them off, have them on demand
simonw
Page 71 to 74 cover environmental impact and energy usage - so not a whole chapter but it is there.
andai
Note that this is an overview, each chapter has its own page, and even those are overviews, each chapter comes as a separate PDF.
The full report PDF is 456 pages.
mentalgear
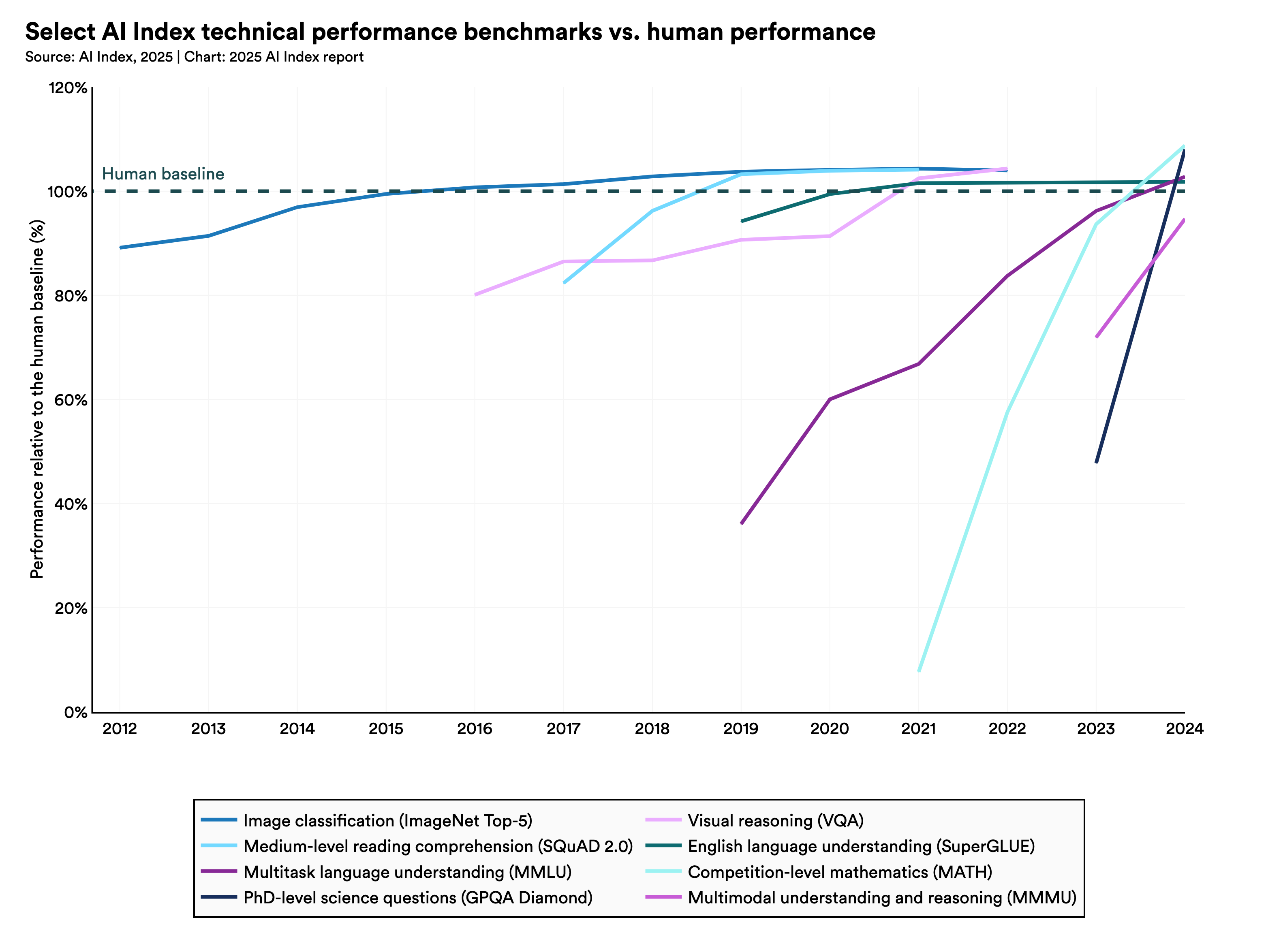
"AI performance on demanding benchmarks continues to improve."
My feeling is that more AI models are fine-tuned on these prestigious benchmarks.
vander_elst
Meta question, why does the website try to make it more difficult to open the images in a new tab? usually if I want to do that, I right click and then select "open image in a new tab". Here I had to go through some loops to do it. Additionally, if you just copy the URL you get to a image that's just noise and that seems to be by design. I still can access the original image though and download it from AWS S3 (https://hai-production.s3.amazonaws.com/images/fig_1e.png). So the question, why all the loops, just to scare off non-technical users?
{kind=link}
andai
The whole thing is over-engineered, could have been a few lines of HTML. They just made it harder to use and navigate, unfortunately.
null
joe_the_user
I recall Stanford's past AI Reports being substantial and critical some years ago. This seems like a compilation of many small press releases into one large press release ("Key take away: AI continues to get bigger, better and faster"). The problem is that AI went from universities to companies and the publications of the various companies themselves then went from research papers to press releases/white papers (I remember OpenAI's supposed technical specification of GPT-something as a watershed, in that actually involved no useful information but just touted statistics who context the reader didn't know).
janpmz
What I'm certain of is that the standard of living will increase. Because we can do more effective work in the same time. This means more output and things will become cheaper. What I'm not sure of, is where this effect will show in the stock market.
soulofmischief
Standard of living for who? Productivity has not scaled appropriately with wages since the industrial revolution.
janpmz
For almost everyone I think. Since the industrial revoultion we have availability of cheap electricity, cheap lighting, an abundance of food and clothing etc. How the wages developed is something I don't know.
elevatortrim
This is assuming most white collar economically productive work is currently utilised to improve standard of lives and is a bottleneck which is at best questionable.
janalsncm
> The U.S. still leads in producing top AI models—but China is closing the performance gap.
Most researchers that I know do not think about things in this lens. They think about building cool things with smart people, and if those people happen to be Chinese or French or Canadian it doesn’t matter.
Most people do not want a war (hot or cold) with the world’s only manufacturing superpower. It feels like we have been incepted into thinking it’s inevitable. It’s not.
In the other hand, if in some nationalistic AI race with China the US decides to get serious about R&D on this front, it will be good for me. I don’t want it though.
dangus
I think China gets a lot of credit for being a "manufacturing superpower" but that kind of oversells what it is.
Look especially at dollar value of exports: https://www.statista.com/statistics/264623/leading-export-co...
The fact that China has 3x the population of the US but only 1.5x the export dollar value of the US says quite a bit. Germany's exporting output is even more impressive considering their population of under 100 million.
NATFA's manufacturing export dollar value is almost equivalent to China.
Complex and heavy industry manufacturing is something where they are not caught up at all. E.g., lithography machines, commercial jet aircraft and engines.
The US/Canada/Mexico are no slouches when it comes to the automotive parts ecosystem. Germany exports more auto parts than China, and the US is barely below China in that regard. I would also point out that certain US/NAFTA and European automobile exports are still considered to be top quality over Chinese models. For example, China is not capable of producing a Ferrari or a vehicle with the complexity and quality of a Mercedes S-Class. That's not to discount the amazing strides that China has made in that area but it is to say that the West+Japan is no slouch in that area.
But to me this is all besides the point anyway. AI is so tied up in open source anyway, this idea that China will leapfrog in AI R&D is somewhat irrelevant in my mind. I don't think any one country will have better capabilities than anyone else. There is no moat.
And ultimately I still predict that Chinese AI will be mostly a domestic product because of heavy government involvement in private data centers and the great firewall.
colesantiago
It's great to see that there will be new jobs when AI usage in businesses skyrockets.
ausbah
honestly hope that LLMs end up creating mountains of unsustainable tech debt across these companies so devs have some job security
dartharva
> In the U.S., 81% of K–12 CS teachers say AI should be part of foundational CS education, but less than half feel equipped to teach it.
I'm curious, what exactly do they mean when they say they should teach AI in K-12?
They released the data for this report as a bunch of CSV files in a Google Drive, so I converted those into a SQLite database for exploration with Datasette Lite: https://lite.datasette.io/?url=https://static.simonwillison....
Here's the most interesting table, illustrating examples of bias in different models https://lite.datasette.io/?url=https://static.simonwillison....