The program is the database is the interface
62 comments
·March 8, 2025hilti
jahewson
Over time I’ve come to see LISP less as the natural collapse of artificial boundaries but the artificial collapse of natural ones. Where and how data is stored is a real concern, but where and how the program is stored isn’t. Security boundaries around data and executable code are of paramount importance. Data storage concerns don’t benefit from being mixed with programming language concerns but from computer and storage architecture concerns (eg column stores).
In toy programs, such as this one, those concerns can all be discarded, so LISP is a good fit. But in serious systems it’s soon discovered that what is offered is in fact “simplistic made easy”. That’s not to say that traditional systems don’t suffer from all the ills Hickey diagnoses in them, but that we differ on what the cure is.
jamii
> it solves the actual problem perfectly
The whole post was about how that doesn't solve the problem perfectly - there is no way to interactively edit the output.
> by embracing LISP principles directly
This could just as easily have been javascript+json or erlang+bert. There's no lisp magic. The core idea in the post was just finding a way for code to edit it's own constants so that I don't need a separate datastore.
Eventually I couldn't get this working the way I wanted with clojure and I had to write a simple language from scratch to embed provenance in values - https://news.ycombinator.com/item?id=43303314.
cogman10
> It doesn't scale to massive collaborative systems where you need rigid interfaces between components. But I suspect many of us are solving problems that don't actually need that complexity.
Here's the issue. Starting out you almost certainly don't need that rigid interface. However, the longer the app grows the more that interface starts to matter and the more costly retrofitting it becomes.
The company I currently worked at started out with a "just get it done" approach which lead to things like any app reaching into any database directly just to get what it needs. That has created a large maintenance issue that to this day we are still trying to deal with. Modifying the legacy database schema in any way takes multiple months of effort due to how it might break the 20 systems that reach into it.
crq-yml
My take on what the issue is, is primarily in the ramifications of Conway's law and how our social structures map to systems.
When the system is small, it makes a great deal of sense to be an artisan and design simple automations that work for exactly that task, which for the most common things is always supported by any production-oriented programming environment - there's a lot of ways in which you can't go wrong because the problem is so small relative to the tools that any approach will crush it. "Just get it done" works because no consequence is felt, and on the time scale of "most businesses fail within five years", it might never be.
When it's large, everyone would prefer to defer to a common format and standard tools. The problems are now complex, have to be discussed and handled by many people, they need documentation and clear boundaries on roles and responsibilities. But common formats and standards are a pyramid of scope creep - eventually it has to support everyone - and along the way, monopolistic organizations vie for control over it in hopes of selling the shovels and pickaxes for the next gold rush. So we end up with a lot of ugly compatibility issues.
In effect, the industry is always on this treadmill of hacking together a simple thing, blowing out the complexity, then picking up the pieces and reassembling them into another, slightly cleaner iteration.
Maintenance can be done successfully - there are always examples of teams and organizations that succeed - but like with a lot of infrastructure, there's an investment bias towards new builds.
phkahler
>> No SQL, no UI framework, no MVC architecture - yet it solves the actual problem perfectly.
No SQL but in it's place is some code. The point of SQL was to standardize a language for querying data. This is just using a language other than the standard. A UI is a way for people to avoid writing code.
Sure doing your own custom thing results in something easy for the programmer. Nothing new about that.
rlupi
> Of course, there are tradeoffs. This works beautifully for personal tools and small-team scenarios. It doesn't scale to massive collaborative systems where you need rigid interfaces between components. But I suspect many of us are solving problems that don't actually need that complexity.
Spreadsheets. If you squint the right way, they embody the lisp principles for the non-programmers' world.
kazinator
MS Excel has IF(this, then, else), AND(expr, expr, ...), OR(expr, expr, ...) and more recently LAMBDA.
deterministic
> "Any sufficiently complicated program contains an ad hoc, informally-specified, bug-ridden, slow implementation of half of Common Lisp."
I have never seen that in practice (30+ years of industry experience working on very large applications).
I think it is one of those statements that fans of Lisp love to quote (a lot) without having any empirical data to back it up.
And yes I am sure that there are examples out there. You can probably find examples of anything if you look hard enough. But that doesn't make it a general rule.
wruza
This makes no sense to me. CL is not an astral technology. It’s just a parentheses-rich language that is worse than almost any other until you get to macros, continuations and psychotic polymorphism. Which are cool to talk about at hacker parties, no /s, but don’t do much business-wise.
fuzzfactor
>the collapse of artificial boundaries between program, data, and interface creates a more direct connection to the problem domain.
I always figured that was one of the reasons that Excel can tackle so many different problems.
jamii
This is an old prototype. I ended up making a language for it from scratch so that I could attach provenance metadata to values, making them directly editable even when far removed from their original source.
https://www.scattered-thoughts.net/log/0027#preimp
https://x.com/sc13ts/status/1564759255198351360/video/1
I never wrote up most of that work. I still like the ideas though.
Also if I had ever finished editing this I wouldn't have buried the lede quite so much.
jim_lawless
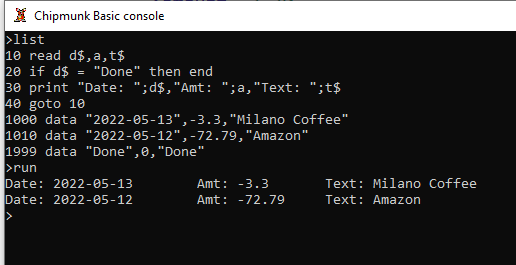
This reminds me of home computing in the late 70's when we used to keep our "database" info in DATA statements embedded in a given BASIC program.
{kind=link}
julesallen
Glad I'm not the only lunatic who would do something like this. At least until I got my paws on dBASE.
I worked with somebody with your name in the early 90s on a Sequent/Dynix system, that wasn't you by chance was it?
jim_lawless
Nope. Not me.
w10-1
That reminds me of a dream:
1. Write queries in datalog
2. Compose them like reusable functions
3. Stream that data between SQL db and dataframe columns and graph db
4. Both also supported with reusable composable function interfaces
5. With IDE/notebook feedback and content-assist including not just syntax but the referenced data model.
6. With distinct modes for exploring datasets and for generating code and tests for hardened pipelines.
7. With abstract accounting for operations of the db, transforms, and transfers.
Data and language will always have ultra-specialized forms. I’m looking for a low-overhead way to explore solutions using different combinations of baseline paradigms before generating code for the one to productize.
kaeland
This might be what you're looking for... https://gtoolkit.com/
bob1029
I am a huge proponent of ideas like using SQL to directly implement business logic. When you bring the logic and the data together under the same abstraction, things will begin to click that you didn't even know existed. Business logic expressed as SQL commands can be stored as yet more data within the same schema. This opens the door for reflection and other features you would ordinarily only think to look for in advanced backend languages.
eitland
I sometimes deal with such code.
I belive it works for you, and I can even say I think most projects have (a little) too few lines of embedded sql in them.
But arguing for code that isn't checked out with the rest of the code when I clone the repo, isn't greppable, and radically departs from everything most people are used to, that isn't something I'd accept.
tmountain
You can greatly improve DX with something like this and get the best of both worlds.
zabzonk
Looks horrible to me. Why not a spreadsheet?
ajross
Without bothering to try to enumerate minutiae, here's the One Thing that would control such a decision in any such "why not just" argument:
Complicated formats can't be meaningfully version controlled.
TZubiri
OTOH
Excel guy: Boom got it done in 5 minutes sips coffee what's next?
10x engineer: I have devised a new programming paradigm to tell me I need to spend less on coffee, wrote a blog post about it and missed a call from a client and a recruiter.
antonvs
I once made over $1 million developing a program to rescue a small financial services company from its unmanageable mess of Excel sheets.
While I was working on that, the company was busy trying to figure out which other companies the millions of unaccounted excess dollars in their fiduciary account belonged to.
Turns out the boom-got-it-done-in-5-minutes types don't always have a plan for making the big picture work, beyond their current 5-minute problem.
hilti
Fair point, and I've certainly been on both sides of this equation!
The Excel approach is absolutely more efficient for one-off tasks or where the goal is simply "get numbers, make decision, move on." No argument there.
Where the programmatic approach shines is when:
1. The same task repeats annually/monthly (like the author's accounting example) 2. The rules or categorizations evolve over time 3. You need an audit trail of how you arrived at conclusions 4. The analysis grows more complex over time
I've seen plenty of Excel wizards whose spreadsheets eventually become their own form of programming - complete with complex macros, VBA, and data models that only they understand. At that point, they've just created an ad-hoc program with a different syntax.
There's a sweet spot for each approach. Sometimes the 5-minute Excel solution is exactly right. Other times, spending an hour on a reusable script saves you 10 hours next year. The real 10x move is knowing which tool fits which situation.
And yes, sometimes we programmers do overthink simple problems because playing with new approaches is fun. I'll cop to that!
endofreach
But then, who'd invent excel? Maybe we need the compromise and let some people be the 10xcel engineer...
zabzonk
> Complicated formats can't be meaningfully version controlled.
Well, at the risk of simply saying "why not" - why not? Preferably with an example.
ajross
How can you diff the formulas in two spreadsheet templates?
jerryhomelab
I version control them by duplicating sheets
AlienRobot
Nor can a single file.
If you're keeping records as files, I think you should just use a million files instead.
1. Easy to version control
2. You can sync on the cloud with less conflicts if each record is isolated from the rest
3. Sounds unique and cool
TZubiri
Single files can easily be versioned. Consider git, which uses blob based tracking, not file based tracking. It doesn't matter if you split file A into A and B, git tracks it just fine.
codr7
Lisp makes a lovely data format imo, much nicer to work with than CSV/JSON/YAML/XML.
moi2388
(defn text->tag [text] (first (for [[keyword tag] keyword->tag :when (clojure.string/includes? text keyword)] tag))) “Joe’s Coffee Hit” text->tag :error #object[TypeError TypeError: a.indexOf is not a function. (In 'a.indexOf(b)', 'a.indexOf' is undefined)] If you type "Joe's Coffee Hut" (including the "!) into the textbox above and hit the text->tag button, you'll see the result of running the text->tag function on that input.
Looks great xD
pmkary
The moment I saw the title I knew it has something to do with EVE. Those people were revolutionary and it is a shame EVE never made it, what a glorious masterpiece of an article.
nullpoint420
The engineers yearn for org-mode
AlienRobot
And to think this could all have been solved in LibreOffice Calc if they spent similar amounts of time learning it...
Hammershaft
tbf learning clojure is a more valuable spend of time then learning LibreOffice Calc.
amelius
Nice. In the same vein, I also like "the program is the config file".
What the author demonstrates here is a powerful principle that dates back to LISP's origins but remains revolutionary today: the collapse of artificial boundaries between program, data, and interface creates a more direct connection to the problem domain.
This example elegantly shows how a few dozen lines of Clojure can replace an entire accounting application. The transactions live directly in the code, the categorization rules are simple pattern matchers, and the "interface" is just printed output of the transformed data. No SQL, no UI framework, no MVC architecture - yet it solves the actual problem perfectly.
The power comes from removing indirection. In a conventional app, you have: - Data model (to represent the domain) - Storage layer (to persist the model) - Business logic (to manipulate the model) - UI (to visualize and interact)
Each boundary introduces translation costs, impedance mismatches, and maintenance burden.
In the LISP approach shown here, those boundaries disappear. The representation is the storage is the computation is the interface. And that direct connection to your problem is surprisingly empowering - it's why REPLs and notebooks have become so important for data work.
Of course, there are tradeoffs. This works beautifully for personal tools and small-team scenarios. It doesn't scale to massive collaborative systems where you need rigid interfaces between components. But I suspect many of us are solving problems that don't actually need that complexity.
I'm reminded of Greenspun's Tenth Rule: "Any sufficiently complicated program contains an ad hoc, informally-specified, bug-ridden, slow implementation of half of Common Lisp." The irony is that by embracing LISP principles directly, you can often avoid building those complicated programs in the first place.
Rich Hickey's "Simple Made Easy" talk explores this distinction perfectly - what the industry calls "easy" (familiar tools and patterns) often creates accidental complexity. The approach shown here prioritizes simplicity over easiness, and the result speaks for itself.