API design note: Beware of adding an "Other" enum value
131 comments
·February 27, 2025remram
kibwen
Note that the stance of the OP here is broadly in agreement with what Rust does. His main objection is this:
> The word “other” means “not mentioned elsewhere”, so the presence of an Other logically implies that the enumeration is exhaustive.
In Rust, because all enums are exhaustive by default and exhaustive matching is enforced by the compiler, there is no risk of this sort of confusion. And then the fact that his proposed solution is:
> Just document that the enumeration is open-ended
The non_exhaustive attribute is effectively compiler-enforced documentation; users now cannot forget to treat the enum as open-ended.
Of course, adding non_exhaustive to Rust was not without its own detractors; it usage for any given enum fundamentally means shifting power away from library consumers (who lose the ability to guarantee exhaustive matching) and towards library authors (who gain the ability to evolve their API without causing guaranteed compilation errors in all of their users (which some users desire!)). As such, the guidance is that it should be used sparingly, mostly for things like error types. But that's an argument against open-ended enums in general, not against the mechanisms we use to achieve those (which, as you say, was already possible in Rust via hacks).
tyre
Maybe there should be a compiler option or function to assert that a match is exhaustive. If the match does not handle a defined case, it blows up.
aecsocket
Rust already asserts that a match is exhaustive at compile time - if you don't include a branch for each option, it will fail to compile. This extends to integer range matching and string matching as well.
It's just that with #[non_exhaustive], you must specify a default branch (`_ => { .. }`), even if you've already explicitly matched on all the values. The idea being that you've written code which matches on all the values which exist right now, but the library author is free to add new variants without breaking your code - since it's now your responsibility as a user of the library to handle the default case.
sunshowers
There is currently a missing middle ground in stable Rust, which is to lint on a missing variant rather than fail compilation. There's an unstable option for it, but it would be very useful for non-exhaustive enums where consumers care about matching against every known variant.
You can practically use it today by gating on a nightly-only cfg flag. See https://github.com/guppy-rs/guppy/blob/fa61210b67bea233de52c... and https://github.com/guppy-rs/guppy/blob/fa61210b67bea233de52c...
eru
Couldn't clippy do that for you?
sunshowers
Not at the moment. The unstable lint is implemented in rustc directly, not in clippy, though I guess it could move to clippy in the future.
rendaw
I absolutely _hate_ this. Since you're forced to add a default case, if a new field is added in the future that you need to actively handle it won't turn into a compile error _or_ surface as a runtime error.
I think half of it is developers presuming to know users' needs and making decisions for them (users can make that decision by themselves, using the default case!) but also a logic-defying fear of build breakage, to the point that I've seen developers turn other compile errors into runtime errors in order to avoid "breaking changes".
Spivak
https://news.ycombinator.com/item?id=43237013
You have to opt into it but it's nice that it's available.
rendaw
Oh nice! That seems so backwards, but hey, if it works...
bobbylarrybobby
I agree, this is the one place where upstream crates should be allowed to make breaking changes for downstream users. As a consumer of another crate’s enum, it's easy to enough opt into “never break my code” by just adding default cases, but I'd like to have to opt into that so that I'm notified when new variants are added upstream. Maybe this should even be a Cargo.toml setting — when an upstream crate is marked non-exhaustive, the downstream consumer gets to choose: require me to add default cases (and don't mark them as dead code), or let me exhaustively match anyway, knowing my match statement might break in the future.
BlackFly
It is all about what constitutes a major version bump and what constitutes the public api.
If I have a parameter in my public API that has enumerated options, I should be able to add a new option without needing to bump my semver major version number since downstream existing code obviously isn't going to use it yet. If downstream was using my public api's enum for some of their own book keeping and so matched on my enum, I want to reserve the right to to say that that is non-public use of my enum, hence the idea that exhaustiveness in enums is a separate decision on to what is included in a public API or not.
On the other hand, if I introduce a new variant in a return value and existing code will get it and need to actually do something with it, then it should probably be breaking. Errors are somewhat of an exception to this since almost all error enumerations need a general, "unknown error" category anyways and introducing a new variant is generally elevating one case out of that general case. Obviously authors can make mistakes.
The alternative, when you cannot mark non_exhaustive, is to introduce stringly typed catch alls, which is much less desirable for everyone.
michaeljsmith
Not sure about Rust, but Typescript allows you to have the default handling but still flag a compile error if a new field is added (the first is useful e.g. if a separate component is updated and starts sending new values).
bmoxb
It arguably makes sense in a large monorepo, but otherwise I would agree.
hchja
This is why language syntax is so important.
Swift allows a ‘default’ enum case which is similar to other but you should use it with caution.
It’s better to not use it unless you’re 110% sure that there will not be additional enums added in the future.
Otherwise, in Swift when you add an additional enum case, the code where you use the enum will not work unless you handle each enum occurrence at it’s respective call site.
layer8
The better solution is to have two different “default” cases in the language, one that expresses handling “future” values (values that aren’t currently defined), and one that expresses “the rest of the currently defined values”. The “future” case wouldn’t be considered for exhaustiveness checks.
mayoff
Swift allows an enum to be marked `@frozen`, which is an API (and ABI) stability guarantee that the enum will never gain more cases. Apple uses this quite sparingly in their APIs.
Swift also has two versions of a `default` case in switch statements, like you described. It has regular `default` and it has `@unknown default`. The `@unknown default` case is specifically for use with non-frozen enums, and gives a warning if you haven't handled all known cases.
So with `@unknown default`, the compiler tells you if you haven't been exhaustive (vs. the current API), but doesn't complain that your `@unknown default` case is unreachable.
SkiFire13
What would the "future" default case actually do though? When you're in the past there's no value for it, and the moment you get to the future the values will become part of the "present" and will still not fall under the "future" case. You would need some kind of versioning support in the enum itself, but that's a much bigger change.
kpcyrd
It's still a gotcha in Rust, I've seen code like:
#[non_exhaustive]
pub enum Protocol {
Tcp,
Udp,
Other(u16),
}
#[non_exhaustive]
pub enum Protocol {
Tcp,
Udp,
Icmp,
Other(u16),
}
Having had this in the back of my head for quite some time, I think instead of an `Other` case there should be two methods, one returns an `Option<Protocol>` and the other one returns the `u16` representation. Unless there's a match on one of your expected cases your default branch would inspect the raw numeric type, which would keep working even if that case is added to the enum.
remram
You can't use non_exhaustive and Other. If you have an Other then it's exhaustive. This design is wrong.
ghfhghg
Languages like haxe simply won't compile if you don't cover every enum value in a switch case. Would that not be preferable? I quite like that feature.
F# I believe is similar wrt discriminated unions and pattern matching
nindalf
I think you misunderstood.
By default Rust expects you to handle every enum variant. Not doing so would be a compile error.
An example - my library exposes enum Colour with 3 variants - Red, Blue Green. In your application code you `match` on all 3. So far so good. But now if I add a 4th colour to my enum, your code will no longer compile because you are no longer handling every enum variant. This is a crappy experience for the user of the library.
Instead, the library writer can make their intent clear - with the #[non_exhaustive] attribute. On such an enum it's not enough to handle the 3 colours of the enum, you must add a wildcard matcher that matches any variants added in future. This gives the library writer flexibility to make changes, while protecting the application developer from breakage.
ghfhghg
Oh I see. I did indeed misunderstand.
Thanks for taking the time to explain!
zdw
I wonder how this aligns with the protobuf best practice of having the first value be UNSPECIFIED:
https://protobuf.dev/best-practices/dos-donts/#unspecified-e...
bocahtie
When the deserializing half of the protobuf definitions encounter an unknown value, it gets deserialized as the zero value. When that client updates, it will then be able to deserialize the new value appropriately (in this case, "Mint"). The advice on that page also specifies to not make the value semantically meaningful, which I take to mean to never set it to that value explicitly.
chen_dev
> it gets deserialized as the zero value
It’s more complicated:
https://protobuf.dev/programming-guides/enum/
>> What happens when a program parses binary data that contains field 1 with the value 2?
>- Open enums will parse the value 2 and store it directly in the field. Accessor will report the field as being set and will return something that represents 2.
>- Closed enums will parse the value 2 and store it in the message’s unknown field set. Accessors will report the field as being unset and will return the enum’s default value.
vitus
Ugh. I hate how we (Google) launched proto editions.
It used to be that we broadly had two sets of semantics (modulo additional customizations): proto2 and proto3. Proto editions was supposed to unify the two versions, but instead now we have the option to mix and match all of the quirks of each of the versions.
And, to make matters worse, you also have language-dependent implementations that don't conform to the spec (in fact, very few implementations are conformant). C++ and Java treat everything imported by a proto2 file as closed; C#, Golang, and JS treat everything as open.
I don't see a path forward for removing these custom deprecated field features, or else we'd have already begun that effort during the initial adoption of editions.
dwattttt
> The advice on that page also specifies to not make the value semantically meaningful, which I take to mean to never set it to that value explicitly.
I've taken to coding my C enums with the first value being "Invalid", indicating it is never intended to be created. If one is encountered, it's a bug.
jmole
The example code used added “other” as the last option, which was the source of the problems he described.
This doesn’t happen when you make the first value in the enum unknown/unspecified
plorkyeran
No, the problem described in the article is entirely unrelated to where in the enum the Other option is located. There is a different problem where keeping the Other option at the end of the enum changes the value of Other, but that is not the problem that the article is about.
jmole
Well it simplifies the logic considerably - if you see an enum value you don’t recognize (mint), you treat it as uninitialized (0).
So any future new flavor will be read back as ‘0’ in older versions.
seeknotfind
This is the same as a null pointer, and the requirement is very deeply tied to protobuf as it is used on large distributed systems that always need to handle version mismatch, and this advice doesn't necessarily apply to API design in general.
eddd-ddde
Even in the simplest web apps you can encounter version mismatch when a client requests a response from a server that just updated.
seeknotfind
This implies an API where the server has a single shared implementation. Imagine for instance that the server implements a shim for each version of the interface, then there isn't a need for the null in the API. Imagine another alternative, that the same API never adds a field, but you add a new method which takes the new type. Imagine yet again an API where you are able to version the clients in lockstep. So, it's a decision about how the API is used and evolves that recommends the API encoding or having a null default. However in a different environment or with different practices, you can avoid the null. Of course the reason to avoid the null is so that you can statically enforce this value is provided in new clients, though this also assumes your client language is typed. So in the end, protobuf teaches us, but it's not always the best in every situation.
hansvm
Hence the advice to make that situation not happen. Update the client and server to support both versions and prefer the new one, then update both to not support the old version. With load balancers and other real-world problems you might have to break that down into 4 coordinated steps.
null
MarkMarine
I don’t mind the zero value for the proto enums, makes sense, but I require converting to my inner logic to not include this “unknown” and error during the conversion if it fails.
I’ve seen engineers bring those unknowns or unspecified through to the business logic and that always made my face flush red with anger.
fmbb
Why the anger?
If you are consuming data from some other system you have no power over what to require from users. You will have data points with unknown properties.
Say you are tracking sign ups in some other system, and they collect the users’ browser in the process, and you want to see conversion rate per browser. If the browser could not be identified, you prefer it to say ”other” instead of ”unknown”?
I think I prefer the protobuf best practices way: you have a 0 ”unknown”/”unset” value, and you enumerate the rest with a unique name (and number). The enum can be expanded in the future so your code must be prepared for unknown enumerated values tagged with the new (future for your code) number. They are all unique, you just don’t yet know the name of some of the enum values.
You can choose to not consume them until your code is updated with a more recent schema. Or you can reconcile later, annotating with the name of you need it.
Now personally, I would not pick an enum for any set och things that is not closed when you are designing. But I’m starting to think that such sets hardly exist in the real world. Humans redefine everything over time.
crabbone
I wrote my own Protobuf implementation (well, with some changes). Ditching the default values was one of the changes I made. I don't see any reason to have that. But I don't think that Protobuf is a reasonable or even decent protocol in general. It has a lot of nonsense and bad planning. Having default values is probably not in the ten worst things about Protobuf.
beart
"Unspecified" is semantically different from "other". The former is more like a default value whereas the latter is actually "specified, but not one of these listed options".
hamandcheese
Standard practice in protobuf is to never assign semantic meaning to the default value. I think some linters enforce that enum 0 is named "unknown" which is actually more semantically correct than "other" or "unspecified".
NoboruWataya
> Just document that the enumeration is open-ended, and programs should treat any unrecognized values as if they were “Other”.
Possibly just showing my lack of knowledge here but are open-ended enumerations a common thing? I always thought the whole point of an enum is that it is closed-ended?
sd9
I’ve worked on systems which where the set of enum values was fixed at any particular point in time, but could change over time as business requirements changed.
For instance, we had an enum that represented a sport that we supported. Initially we supported some sports (say FOOTBALL and ICE_HOCKEY), and over time we added support for other sports, so the enum had to be expanded.
Unfortunately this always required the entire estate to be redeployed. Thankfully this didn’t happen often.
At great expense, we eventually converted this and other enums to “open-ended” enums (essentially Strings with a bit more structure around them, so that you could operate on them as if they were “real” enums). This made upgrades significantly easier.
Now, whether those things should have been enums in the first place is open for debate. But that decision had been made long before I joined the team.
Another example is gender. Initially an enum might represent MALE, FEMALE, UNKNOWN. But over time you might decide you have need for other values: PREFER_NOT_TO_SAY, OTHER, etc.
hansvm
It's common when mixing many executables over time.
I prefer to interpret those as an optional/nullable _closed_ enum (or, situationally, a parse error) if I have to switch on them and let ordinary language conventions guide my code rather than having to understand some sort of pseudo-null without language support.
In something like A/B tests it's not uncommon to have something that's effectively runtime reflection on enum fields too. Your code has one or more enums of experiments you support. The UI for scaling up and down is aware of all of those. Those two executables have to be kept in sync somehow. A common solution is for the UI to treat everything as strings with weights attached and for the parsers/serializers in your application code to handle that via some scheme or another (usually handling it poorly when people scale up experiments that no longer exist in your code). The UI though is definitely open-ended as it interprets that enum data, and the only question is how it's represented internally.
XorNot
The first time you have to add a new schema value, you'll realise you needed "unknown" or similar - because during an upgrade your old systems need a way to deal with new values (or during a rollback you need to handle new entries in the database).
sitkack
Your comment is the only in the entire discussion that mentions "schema". Having an "other" in a schema is a way to ensure you can run n and n+1 versions at the same time.
It is Data Model design, of which API design a subset.
You can only ever avoid having an other if 1) your schema is fixed and 2) if it is total over the universe of values.
furyofantares
This is not really the case mentioned (not API design), but I somewhat often have an enum that is likely to be added to, but rarely (lots of code will have been written in the meantime) and I would like to update all the sites using it, or at least review them. Typically it looks something like this:
enum WidgetFlavor
{
Vanilla,
Chocolate,
Strawberry,
NumWidgetFlavors
};
null
int_19h
Both are valid depending on what you're modelling.
As far as programming languages go, all enums are explicitly open-ended in C, C++, and C#, at least, because casting an integer (of the underlying type) to enum is a valid operation.
jay_kyburz
My pet hate is when folks start doing math on enums or assuming ranges of values within an enum have meaning.
DonHopkins
Like pesky Hex<=>Decimal conversion with the gap between the numbers and the letters, and upper/lower case letters too.
eru
Yeah, C, C++ (and C#) aren't very good at modelling data structures.
fweimer
Enumerations are open-ended in C and C++. They are just integer types with some extra support for defining constants (although later C++ versions give more control over the available operations).
gauge_field
Sometimes, one case where I made use of this is enumeration of uarch for different hardware to read from the host machine. The update for for new uarch type is closed ended until there is new cpu with new uarch, which is long time. So, for a very long time it is open-ended with very low velocity in change. It is ideal for enums (for a very long time), but you still need to support the change in list of enum variants to not break semver.
kstenerud
I use the "other" technique when it's necessary for the user to be able to mix in their own:
enum WidgetFlavor
{
Vanilla,
Chocolate,
Strawberry,
Other=10000,
};
enum CustomWidgetFlavor
{
RockyRoad=Other,
GroovyGrape,
Cola,
};
enum WidgetFlavor
{
Vanilla,
Chocolate,
Strawberry,
Mint,
Other=10000,
};qingcharles
It's code like this that ends in a terminal choco-banana shake hang:
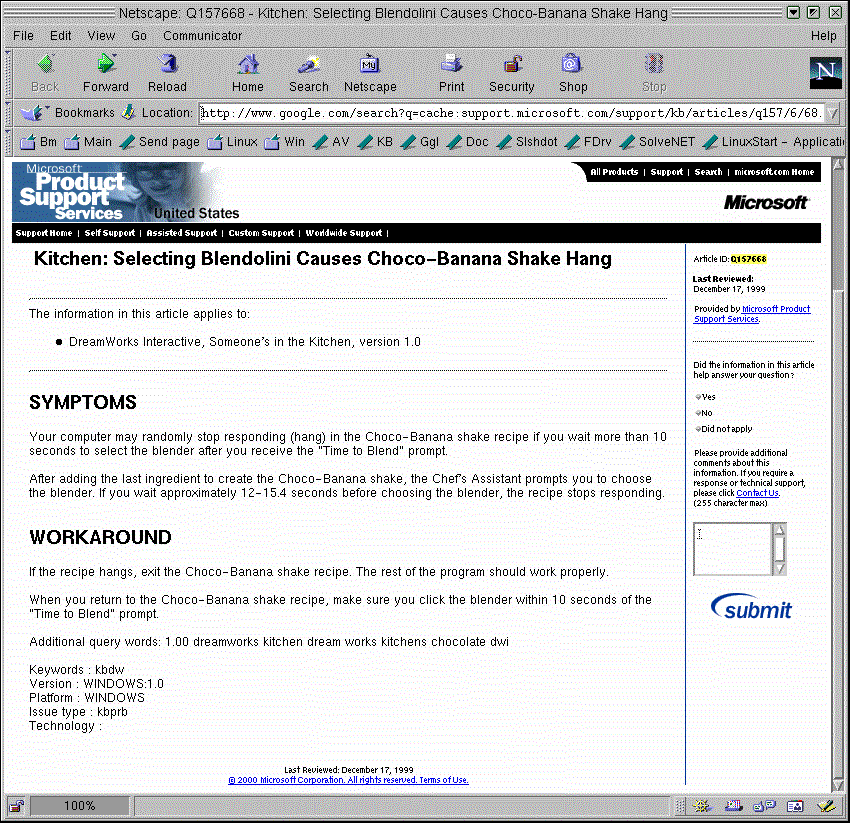{kind=link}
fingerlocks
What is the context here? Is this just a silly nonsense tech support page/meme or an actual product from the late 90s?
qingcharles
It's a real Knowledge Base article from Microsoft. I can't find the original, but it is on archive.org somewhere if you dig around.
sandblast
Is the context not clear for you from the information that the article applies to "DreamWorks Interactive, Someone's in the Kitchen, version 1.0" and other clues that it's a game?
dominicrose
"Other" doesn't mean the same thing before and after Cola has been added. "Unknown" would be more accurate.
My personal opinion would be to make the enum nullable and not add a fake value.
kstenerud
It's not about "other" having a meaning unto itself; rather it's about having a placeholder in the enum "space" (for older languages that implement it as an integer) so that customers can introduce their own variants. My library would then happily accept any value passed in, but only act upon the enum values that the library itself specifies. The customer would be entirely responsible for making sure their own variants behave well.
This is not a common thing to do, of course, but when your customers are clamoring for what would actually be a useful feature for your product, even this somewhat ugly hack is a lot better than saying "no".
mewpmewp2
But null value seems to have the intent that it doesn't have category at all.
So, let's say there's a function createFruit(fruitType: FruitTypeEnum);
If it's null, it seems wrong since it seems to mean that you have a fruit without type.
If it's unknown, then it might also be incorrect, since you very well know the type, it just isn't handled there.
So I'm wondering if best might be something like Unhandled, Unspecified or Unlisted.
dominicrose
I guess if you know the type but it's not in the enum, then you can save it somewhere else. If the enum changes afterwards, that data can be used to update the enum value.
layer8
Slight counterpoint: Unless there is some guarantee that the respective enum type will never ever be extended with a new value, each and every case distinction on an enum value needs to consider the case of receiving an unexpected value (like Mint in the example). When case distinctions do adhere to that principle, then the problem described doesn’t arise.
On the other hand, if the above principle is adhered to as it should, then there is also little benefit in having an Other value. One minor conceivable benefit is that intermediate code can map unsupported values to Other in order to simplify logic in lower-level code. But I agree that it’s usually better to not have it.
A somewhat related topic that comes to mind is error codes. There is a common pattern, used for example by the HTTP status codes, where error codes are organized into categories by using different prefixes. For example in a five-digit error code scheme, the first three digits might indicate the category (e.g. 123 for “authentication errors”), and the remaining two digits represent a more specific error condition in that category. In that setup, the all-zeros code in each category represents a generic error for that category (i.e. 12300 would be “generic authentication error”).
When implementing code that detects a new error situation not covered by the existing specific error codes, the implementer has now the choice of either introducing a new error code (e.g. 12366 — this is analogous to adding a new enum value), which has to be documented and maybe its message text be localized, or else using the generic error code of the appropriate category.
In any case, when error-processing code receives an unknown — maybe newly assigned — error code, they can still map it according to the category. For example, if the above 12366 is unknown, it can be handled like 12300 (e.g. for the purpose of mapping it to a corresponding error message). This is quite similar to the case of having an Other enum value, but with a better justification.
qbane
How about putting Other at the top? You can convince yourself that the value zero (or one if you like) is reserved for unknown values.
shakna
This is what I tend to do. Because 0 is "default", it means "unspecified" in a lot of my API designs.
Cthulhu_
That's the Go approach, where every value is zeroed so it makes sense for enum values to have a 'none' or 'other' or 'unknown' value as the first value.
(note that Go doesn't have enums as a language feature, but you can use its const declaration to create enum-like constants)
dataflow
I think there are multiple concerns here, and they need to be analyzed separately -- they don't converge to the same solution:
- Naming: "Other" should probably be called "Unrecognized" in these situations. Then users understand that members may not be mutually exclusive.
- ABI: If you need ABI compatibility, the constraint you have is "don't change the meanings of values or members", which is somewhat stronger. The practical implication is that if you do need to have an Other value, its value should be something out of range of possible future values.
- Protocol updates: If you can atomically update all the places where the enum is used, then there's no inherent need to avoid Other values. Instead, you can use compile-time techniques (exhaustive switch statements, compiler warnings, temporarily removing the Other member, grep, clang-query, etc.) to find and update the usage sites at compile time. This requires being a little disciplined in how you use the enum during development, but it's doable.
- Distributed code: If you don't have control over all the code using your enum might, then you must avoid an Other value, unless you can somehow ensure out-of-band that users have updated their code.
coin
Just call it "unknown" or "unspecified" or better yet use an optional to hold the enum.
101011
This ended up being the preferred pattern we moved into.
If, like us, you were passing the object between two applications, the owning API would serialize the enum value as a String value, then we had a client helper method that would parse the string value into an Optional enum value.
If the original service started transferring a new String object between services, it wouldn't break any downstream clients, because the clients would just end up with Optional empty
janci
How that works when you need to distinguish between "no value provided" and "a value that is not in the list" - in some applications they have different semantics.
101011
You could treat it as an nullable Option<SomeType>.
In practice, as it relates to enums, I don't usually see 'no value provided' as a frequently used case - it's more likely that 'no value provided' maps to a more informative 'enum' value
KPGv2
> Rust has the "non_exhaustive" attribute that lets you declare that an enum might get more fields in the future.a
Is there a reason, aside from documentation, that this is ever desirable? I rarely program in Rust, but why would this ever be useful in practice, outside of documentation? (Seems like code-as-documentation gone awry when your code is doing nothing but making a statement about future code possibilities)
LegionMammal978
Normally, when you match on the value of an enum, Rust forces you to either add a case for every possible variant, or add a default arm "_ => ..." that acts as a 'none of the above' case. This is called exhaustiveness checking [0].
When you add #[non_exhaustive] to an enum, the compiler says to external users, "You're no longer allowed to just match every existing variant. You must always have a default 'none of the above' case when you're matching on this enum."
This lets you add more variants in the future without breaking the API for existing users, since they all have a 'none of the above' case for the new variants to fall into.
[0] https://doc.rust-lang.org/book/ch06-02-match.html#matches-ar...
jeroenhd
If your library processes data from another language, you'll probably need to deal with the possibility that the library returns open ended enums.
I believe I've also seen this declaration for generated bindings for a JSON API that promises backwards compatibility for calls and basic functionality at least. Future versions may include more options, but the code will still compile fine against the older API.
I don't think it's a great tool to use everywhere, but there are edge cases where Rust's demand for exhaustive matches conflicts with the non-Rust world, and that's where stuff like this becomes hard to avoid.
jffhn
>"programs should treat any unrecognized values as if they were “Other”"
Having such an "Other" value does not prevent from considering that the enum is open-ended, and it simplifies a lot all the code that has to deal with potentially invalid or unknown values (no need for a validity flag or null).
That's probably why in DIS (Distributed Interactive Simulation) standard, which defines many enums, all start with OTHER, which has the value zero.
In STANAGs (NATO standards), the value zero is used for NO_STATEMENT, which can also be used when the actual value is in the enum but you can't or don't need to indicate it.
I remember an "architecture astronaut" who claimed that NO_STATEMENT was not a domain value, and removed it from all the enums in its application. That did not last long.
That also reminds me of Philippe Khan (Bordland) having in some presentation the ellipse extend the circle, to add a radius. A scientist said he would do the other way around, and Khan replied: "This is exactly the difference between research and industry".
ivan_gammel
>That also reminds me of Philippe Khan (Bordland) having in some presentation the ellipse extend the circle, to add a radius. A scientist said he would do the other way around, and Khan replied: "This is exactly the difference between research and industry".
My favorite question on interviews on the OOP topic. It can be correct either way or both can be wrong, so the good answer would be "It depends". When developers rush to give a specific answer, they do not demonstrate due attention to the domain and it may mean that they will assume thousand other falsehoods from those articles on Github.
jffhn
err that's Kahn
sylware
As another example: vulkan3D made the mistake to use enum in its API.
Now, they must be sure it is a signed 32bits on 32 or 64 bits systems, namely check the compiler behavior. You can check the code, they always add a 0x7fffffff as the last enum value to "force" the compiler and tell developers (which have enough experience) "hey, this is a signed 32bits"... whoopsie!
We should eat the bullet: remove the enum in vulkan3D, and use the appropriate primitive type for each platform ABI (not API...), so the "fix" should be transparent as it would no break the ABI. But all the "code generators" using khronos xml specifications and static source code are to be modified in one shot to stay consistent. This ain't small feat.
[NOTE: enum is one of those things which should be removed from the "legacy profile" of C (like tons of keywords, integer promotion, implicit cast, etc).]
esafak
Just add a free-form text field to hold the other value, and revise your enum as necessary, while migrating the data.
AceJohnny2
I can't even tell if you're trolling.
bilekas
As the other commenter mentioned, I hope this is an excersize in trolling. Please don't do this when using enums.
> Free-form text firle to hold the other value
> revise your enum as necessary, while migrating the dat
Both instances would defeat the purpose of an enum..
As for the original post, my 2cents are valued enums.
{
Other = 0, Vanilla = 1, Chocolate = 2, Strawberry = 3 }
In this case it allows some flexibility to add later while still being able to make use of 0 (Other). Or maybe I missed the OP's point ?
esafak
With a form you will have an empirical basis to determine what the missing enum values should be, and the user won't enter any text unless necessary.
bilekas
> and the user won't enter any text unless necessary
You are underestimating users' ability to ignore non strict constraints. Also when I can, why would I not increase my compile time checking ? There are very good reasons to use Enums, you seem to just want to ignore those reasons.
Rust has the "non_exhaustive" attribute that lets you declare that an enum might get more fields in the future. In practice that means that when you match on an enum value, you have to add a default case. It's like a "other" field in the enum except you can't reference it directly, you use a default case.
IIRC a secret 'other' field (or '__non_exhaustive' or something) is actually how we did thing before non_exhaustive was introduced.